Weber Christoph, Röschke Lena, Modersohn Luise, Lohr Christina, Kolditz Tobias, Hahn Udo, Ammon Danny, Betz Boris, Kiehntopf Michael
Department of Clinical Chemistry and Laboratory Diagnostics and Integrated Biobank Jena (IBBJ), Jena University Hospital, 07747 Jena, Germany.
Jena University Language & Information Engineering (JULIE) Lab, Friedrich Schiller University Jena, 07743 Jena, Germany.
J Clin Med. 2020 Sep 12;9(9):2955. doi: 10.3390/jcm9092955.
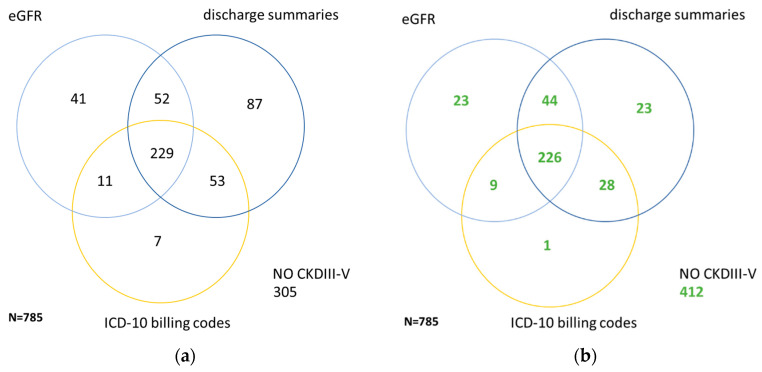
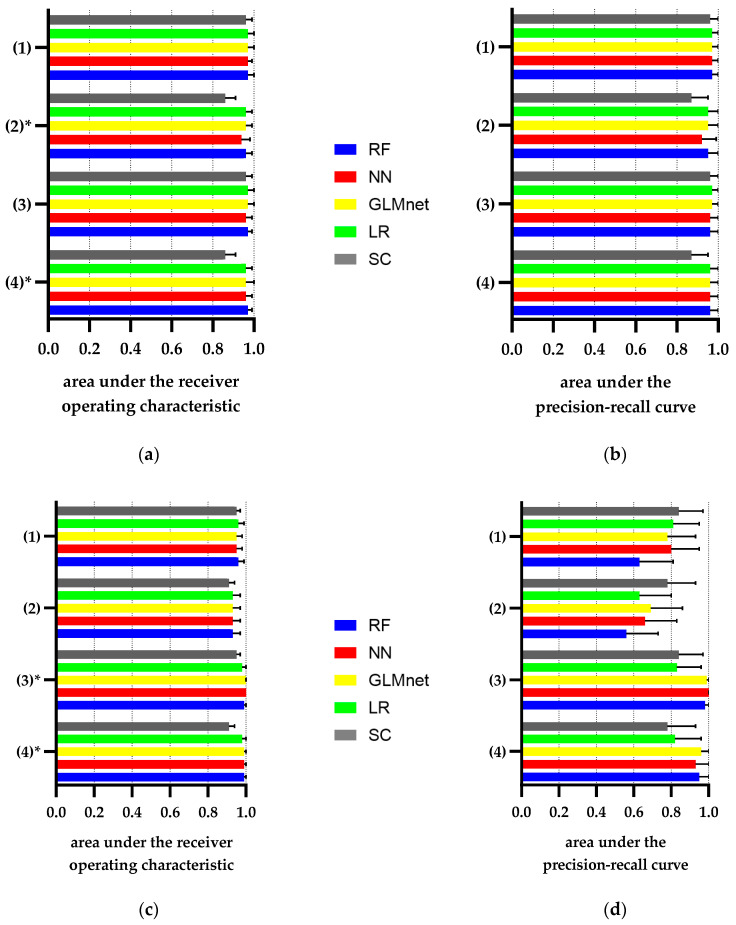
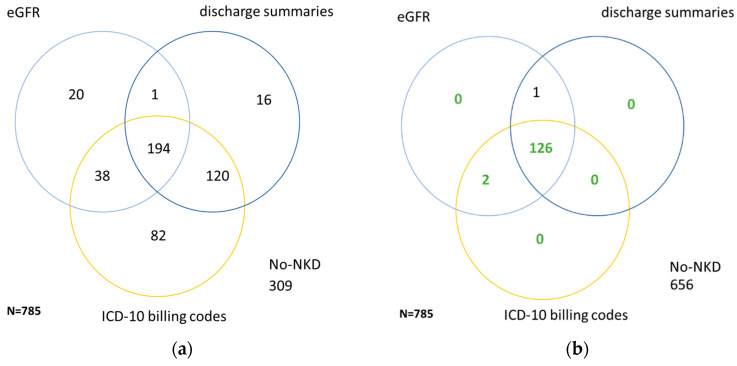
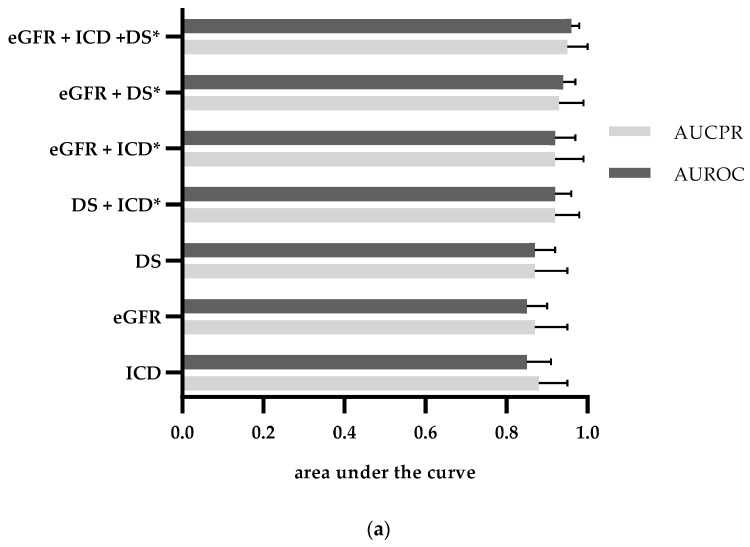
Automated identification of advanced chronic kidney disease (CKD ≥ III) and of no known kidney disease (NKD) can support both clinicians and researchers. We hypothesized that identification of CKD and NKD can be improved, by combining information from different electronic health record (EHR) resources, comprising laboratory values, discharge summaries and ICD-10 billing codes, compared to using each component alone. We included EHRs from 785 elderly multimorbid patients, hospitalized between 2010 and 2015, that were divided into a training and a test (n = 156) dataset. We used both the area under the receiver operating characteristic (AUROC) and under the precision-recall curve (AUCPR) with a 95% confidence interval for evaluation of different classification models. In the test dataset, the combination of EHR components as a simple classifier identified CKD ≥ III (AUROC 0.96[0.93-0.98]) and NKD (AUROC 0.94[0.91-0.97]) better than laboratory values (AUROC CKD 0.85[0.79-0.90], NKD 0.91[0.87-0.94]), discharge summaries (AUROC CKD 0.87[0.82-0.92], NKD 0.84[0.79-0.89]) or ICD-10 billing codes (AUROC CKD 0.85[0.80-0.91], NKD 0.77[0.72-0.83]) alone. Logistic regression and machine learning models improved recognition of CKD ≥ III compared to the simple classifier if only laboratory values were used (AUROC 0.96[0.92-0.99] vs. 0.86[0.81-0.91], < 0.05) and improved recognition of NKD if information from previous hospital stays was used (AUROC 0.99[0.98-1.00] vs. 0.95[0.92-0.97]], < 0.05). Depending on the availability of data, correct automated identification of CKD ≥ III and NKD from EHRs can be improved by generating classification models based on the combination of different EHR components.
自动识别晚期慢性肾脏病(CKD≥III期)和无已知肾脏疾病(NKD)的情况,可为临床医生和研究人员提供帮助。我们假设,与单独使用每个组件相比,通过整合来自不同电子健康记录(EHR)资源的信息(包括实验室检查值、出院小结和ICD-10计费代码),可以改善对CKD和NKD的识别。我们纳入了2010年至2015年间住院的785例老年多病患者的电子健康记录,并将其分为训练数据集和测试数据集(n = 156)。我们使用了受试者工作特征曲线下面积(AUROC)和精确召回率曲线下面积(AUCPR)以及95%置信区间来评估不同的分类模型。在测试数据集中,作为简单分类器的EHR组件组合对CKD≥III期(AUROC 0.96[0.93 - 0.98])和NKD(AUROC 0.94[0.91 - 0.97])的识别,优于单独使用实验室检查值(CKD的AUROC 0.85[0.79 - 0.90],NKD的AUROC 0.91[0.87 - 0.94])、出院小结(CKD的AUROC 0.87[0.82 - 0.92],NKD的AUROC 0.84[0.79 - 0.89])或ICD-10计费代码(CKD的AUROC 0.85[0.80 - 0.91],NKD的AUROC 0.77[0.72 - 0.83])。如果仅使用实验室检查值,逻辑回归和机器学习模型与简单分类器相比,对CKD≥III期的识别有所改善(AUROC 0.96[0.92 - 0.99]对0.86[0.81 - 0.91],P < 0.05);如果使用既往住院信息,则对NKD的识别有所改善(AUROC 0.99[0.98 - 1.00]对0.95[0.92 - 0.97],P < 0.05)。根据数据的可用性,通过基于不同EHR组件的组合生成分类模型,可以改善从EHR中正确自动识别CKD≥III期和NKD的情况。