Meid Andreas D, Ruff Carmen, Wirbka Lucas, Stoll Felicitas, Seidling Hanna M, Groll Andreas, Haefeli Walter E
Department of Clinical Pharmacology and Pharmacoepidemiology, University of Heidelberg, Heidelberg 69120, Germany.
Cooperation Unit Clinical Pharmacy, University of Heidelberg, Heidelberg 69120, Germany.
Clin Epidemiol. 2020 Nov 2;12:1223-1234. doi: 10.2147/CLEP.S274466. eCollection 2020.
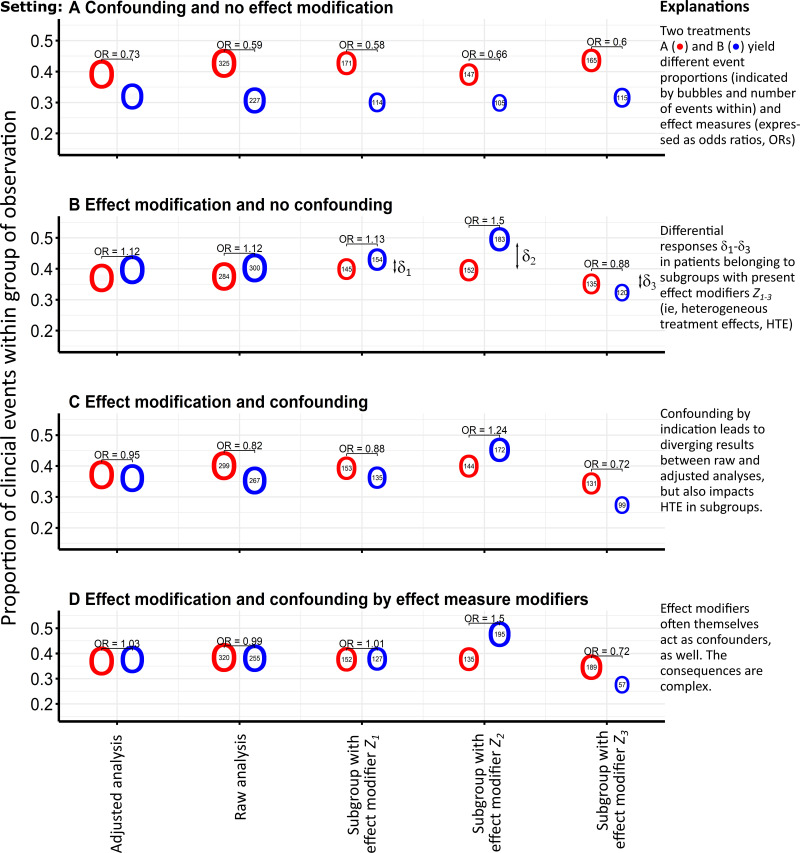
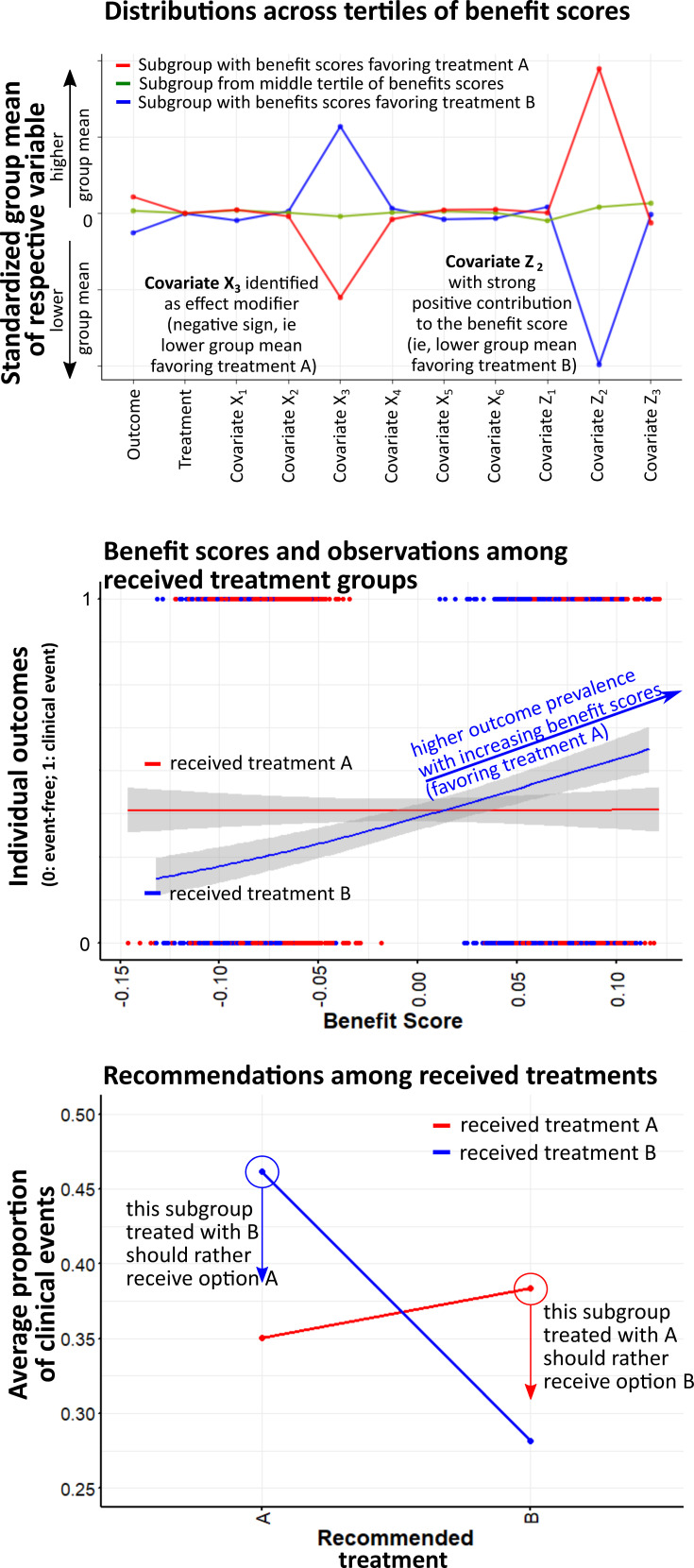
When healthcare professionals have the choice between several drug treatments for their patients, they often experience considerable decision uncertainty because many decisions simply have no single "best" choice. The challenges are manifold and include that guideline recommendations focus on randomized controlled trials whose populations do not necessarily correspond to specific patients in everyday treatment. Further reasons may be insufficient evidence on outcomes, lack of direct comparison of distinct options, and the need to individually balance benefits and risks. All these situations will occur in routine care, its outcomes will be mirrored in routine data, and could thus be used to guide decisions. We propose a concept to facilitate decision-making by exploiting this wealth of information. Our working example for illustration assumes that the response to a particular (drug) treatment can substantially differ between individual patients depending on their characteristics (heterogeneous treatment effects, HTE), and that decisions will be more precise if they are based on real-world evidence of HTE considering this information. However, such methods must account for confounding by indication and effect measure modification, eg, by adequately using machine learning methods or parametric regressions to estimate individual responses to pharmacological treatments. The better a model assesses the underlying HTE, the more accurate are predicted probabilities of treatment response. After probabilities for treatment-related benefit and harm have been calculated, decision rules can be applied and patient preferences can be considered to provide individual recommendations. Emulated trials in observational data are a straightforward technique to predict the effects of such decision rules when applied in routine care. Prediction-based decision rules from routine data have the potential to efficiently supplement clinical guidelines and support healthcare professionals in creating personalized treatment plans using decision support tools.
当医疗保健专业人员为患者选择几种药物治疗方案时,他们常常会面临很大的决策不确定性,因为许多决策根本没有单一的“最佳”选择。挑战是多方面的,包括指南建议侧重于随机对照试验,而这些试验的人群不一定与日常治疗中的特定患者相符。其他原因可能是关于治疗结果的证据不足、缺乏对不同选项的直接比较,以及需要个别权衡益处和风险。所有这些情况都会在常规护理中出现,其结果会反映在常规数据中,因此可用于指导决策。我们提出了一个概念,通过利用这些丰富的信息来促进决策制定。我们用于说明的工作示例假设,特定(药物)治疗的反应在个体患者之间可能因他们的特征而有很大差异(异质性治疗效果,HTE),并且如果基于考虑这些信息的HTE的真实世界证据进行决策,将会更加精确。然而,此类方法必须考虑适应症混杂和效应测量修正,例如,通过充分使用机器学习方法或参数回归来估计个体对药物治疗的反应。一个模型对潜在HTE的评估越好,预测的治疗反应概率就越准确。在计算出治疗相关益处和危害的概率后,可以应用决策规则并考虑患者偏好以提供个性化建议。在观察性数据中进行模拟试验是一种直接的技术,可用于预测此类决策规则在常规护理中应用时的效果。基于常规数据的预测性决策规则有可能有效补充临床指南,并支持医疗保健专业人员使用决策支持工具制定个性化治疗方案。