Institute of Health Service and Transfusion Medicine, Beijing, People's Republic of China.
School of Informatics, Xiamen University, Xiamen, People's Republic of China.
Genome Biol. 2022 Aug 9;23(1):171. doi: 10.1186/s13059-022-02739-2.
A fused method using a combination of multi-omics data enables a comprehensive study of complex biological processes and highlights the interrelationship of relevant biomolecules and their functions. Driven by high-throughput sequencing technologies, several promising deep learning methods have been proposed for fusing multi-omics data generated from a large number of samples.
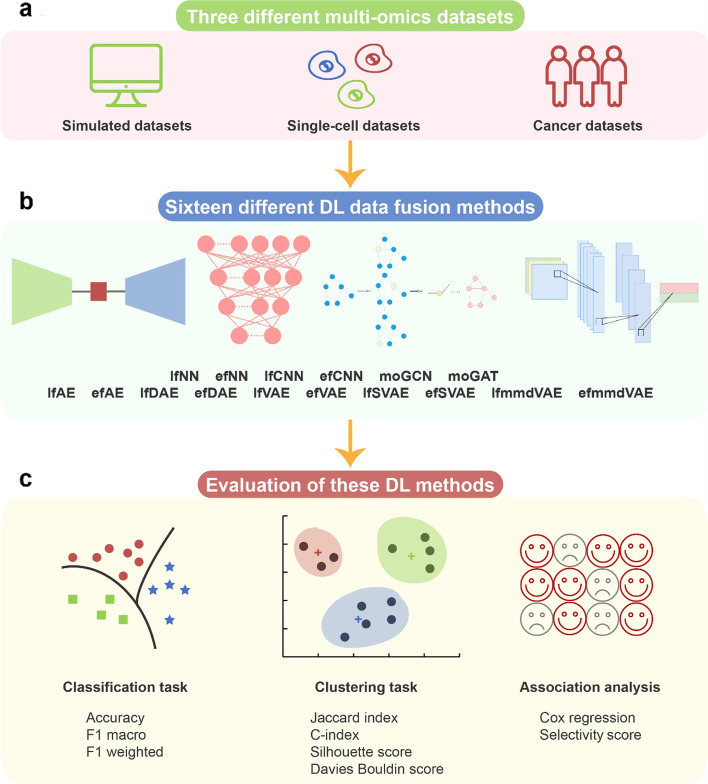
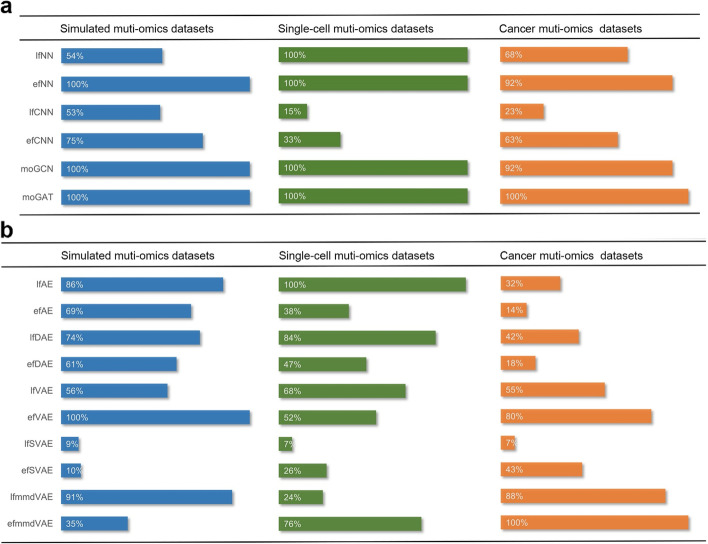
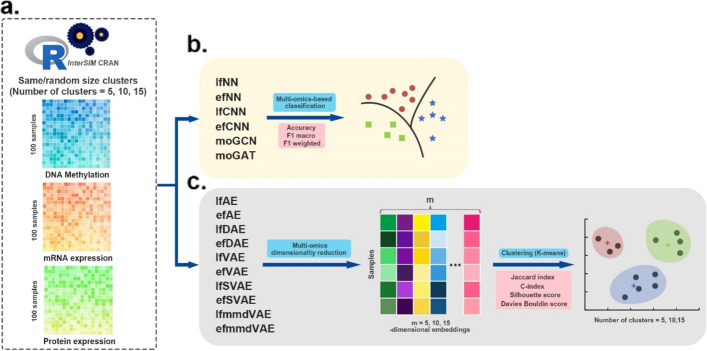
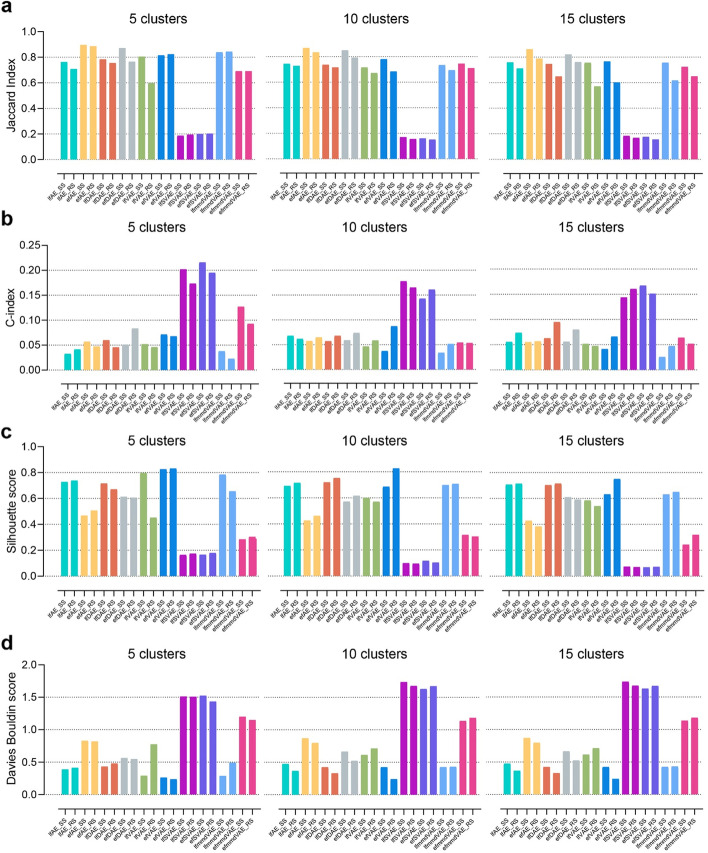
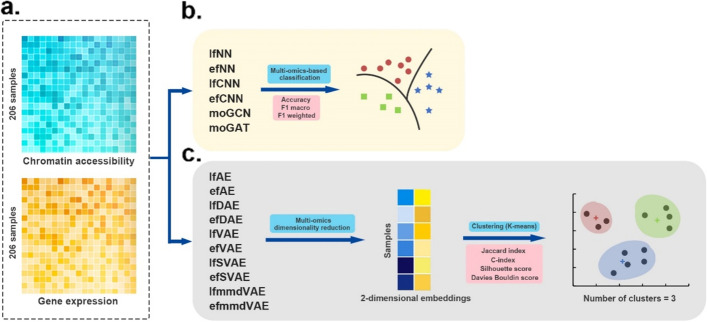
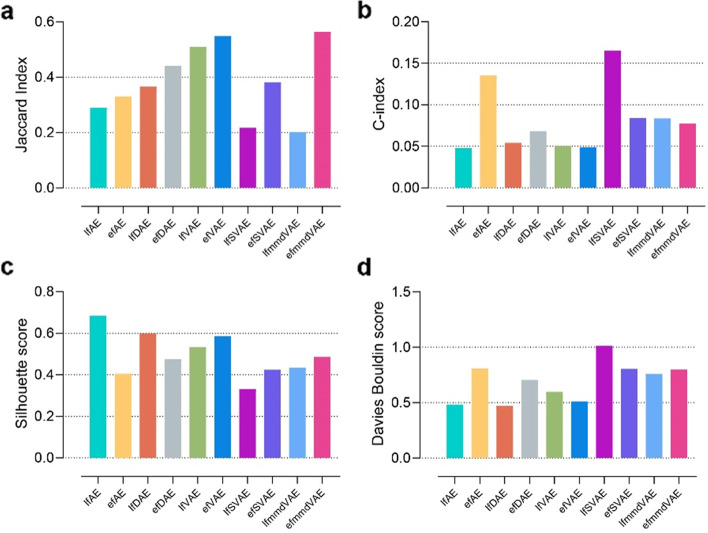
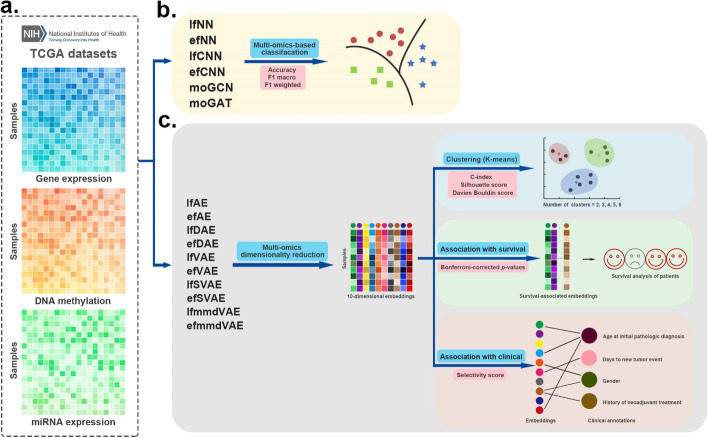
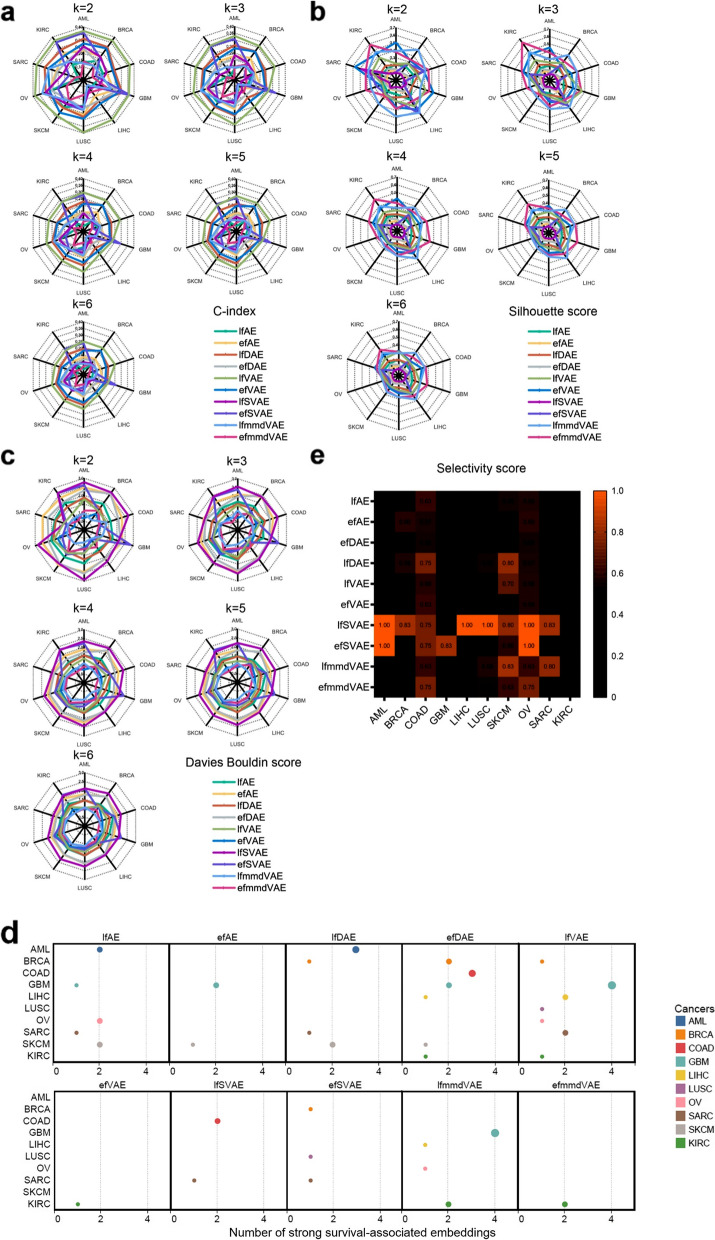
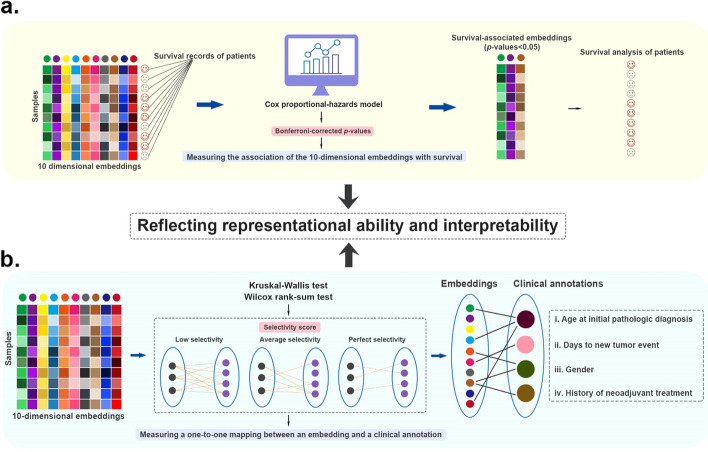
In this study, 16 representative deep learning methods are comprehensively evaluated on simulated, single-cell, and cancer multi-omics datasets. For each of the datasets, two tasks are designed: classification and clustering. The classification performance is evaluated by using three benchmarking metrics including accuracy, F1 macro, and F1 weighted. Meanwhile, the clustering performance is evaluated by using four benchmarking metrics including the Jaccard index (JI), C-index, silhouette score, and Davies Bouldin score. For the cancer multi-omics datasets, the methods' strength in capturing the association of multi-omics dimensionality reduction results with survival and clinical annotations is further evaluated. The benchmarking results indicate that moGAT achieves the best classification performance. Meanwhile, efmmdVAE, efVAE, and lfmmdVAE show the most promising performance across all complementary contexts in clustering tasks.
Our benchmarking results not only provide a reference for biomedical researchers to choose appropriate deep learning-based multi-omics data fusion methods, but also suggest the future directions for the development of more effective multi-omics data fusion methods. The deep learning frameworks are available at https://github.com/zhenglinyi/DL-mo .
融合使用多种组学数据的方法能够全面研究复杂的生物过程,并突出相关生物分子及其功能的相互关系。受高通量测序技术的推动,已经提出了几种有前途的深度学习方法,用于融合来自大量样本的多种组学数据。
在这项研究中,16 种有代表性的深度学习方法在模拟、单细胞和癌症多组学数据集中进行了全面评估。对于每个数据集,设计了两个任务:分类和聚类。使用准确性、F1 宏和 F1 加权三种基准指标评估分类性能。同时,使用 Jaccard 指数(JI)、C 指数、轮廓得分和 Davies Bouldin 得分四种基准指标评估聚类性能。对于癌症多组学数据集,进一步评估了方法在捕捉多维组学降维结果与生存和临床注释的关联方面的优势。基准测试结果表明,moGAT 实现了最佳的分类性能。同时,efmmdVAE、efVAE 和 lfmmdVAE 在聚类任务的所有互补上下文中表现出最有前途的性能。
我们的基准测试结果不仅为生物医学研究人员选择合适的基于深度学习的多组学数据融合方法提供了参考,也为开发更有效的多组学数据融合方法提供了未来的方向。深度学习框架可在 https://github.com/zhenglinyi/DL-mo 上获得。