Computational Story Lab, Vermont Complex Systems Center, MassMutual Center of Excellence for Complex Systems and Data Science, University of Vermont, Burlington, VT, United States of America.
Department of Mathematics & Statistics, University of Vermont, Burlington, VT, United States of America.
PLoS One. 2021 Jan 6;16(1):e0244476. doi: 10.1371/journal.pone.0244476. eCollection 2021.
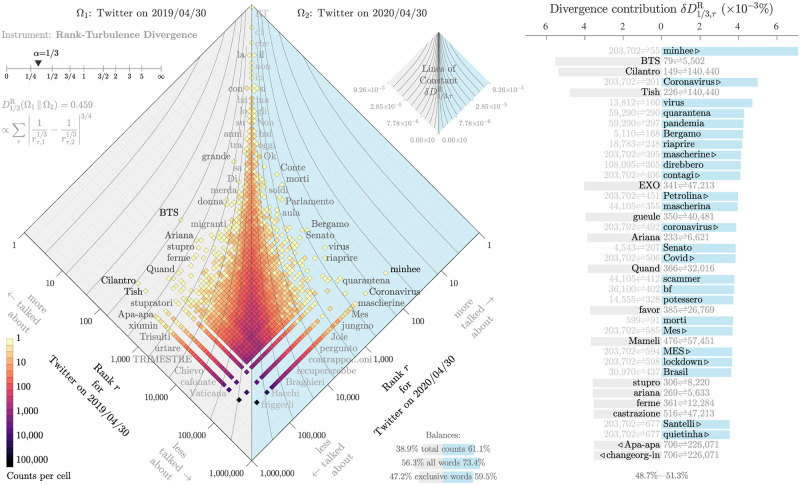
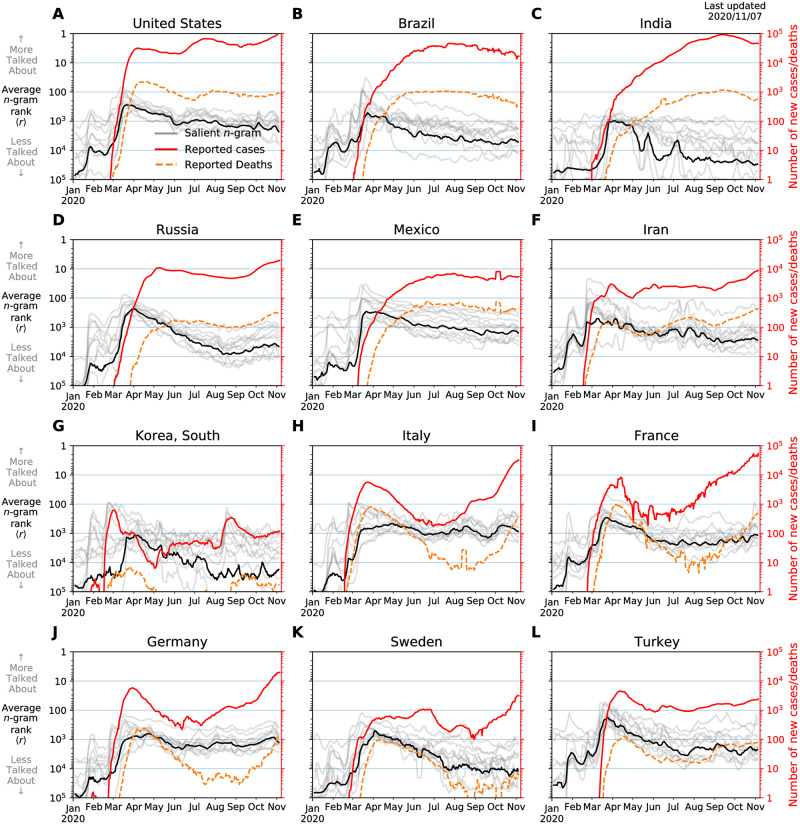
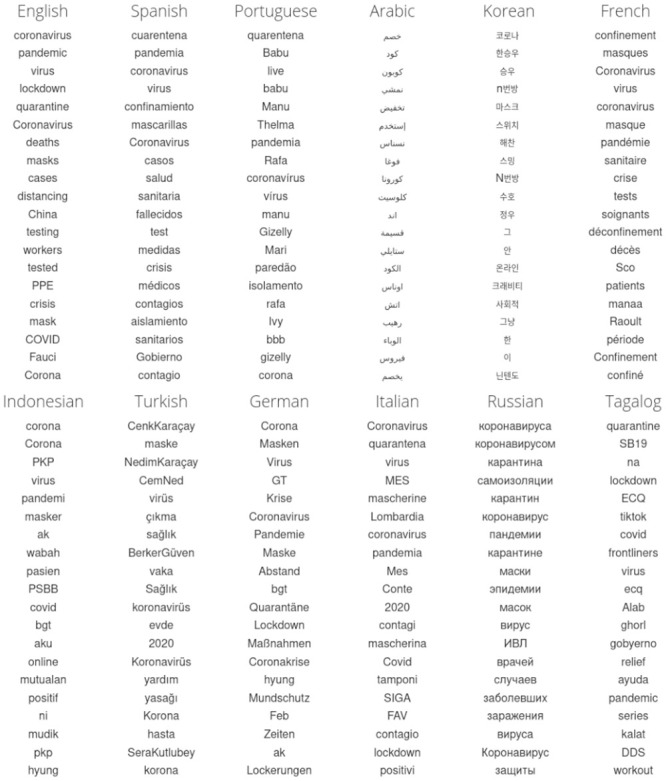
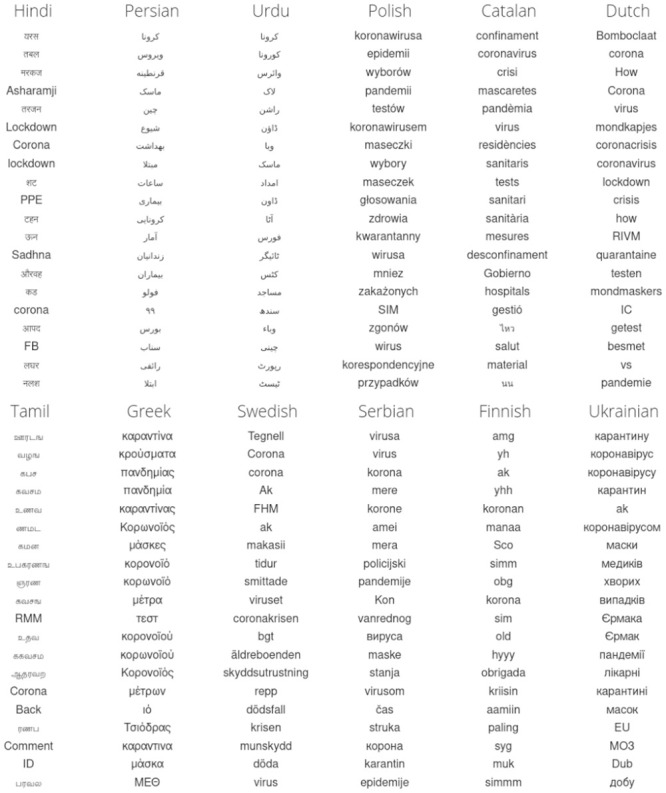
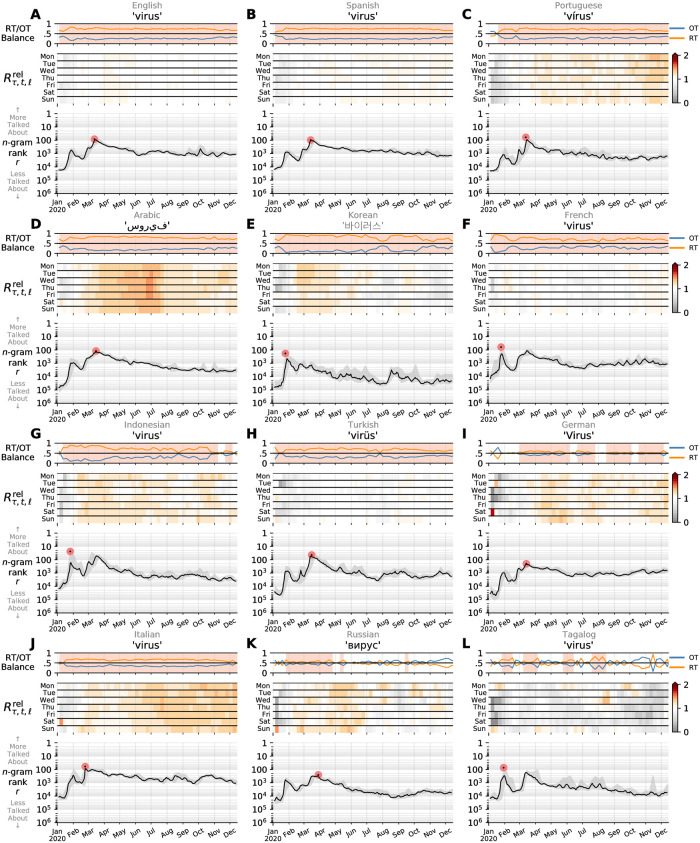
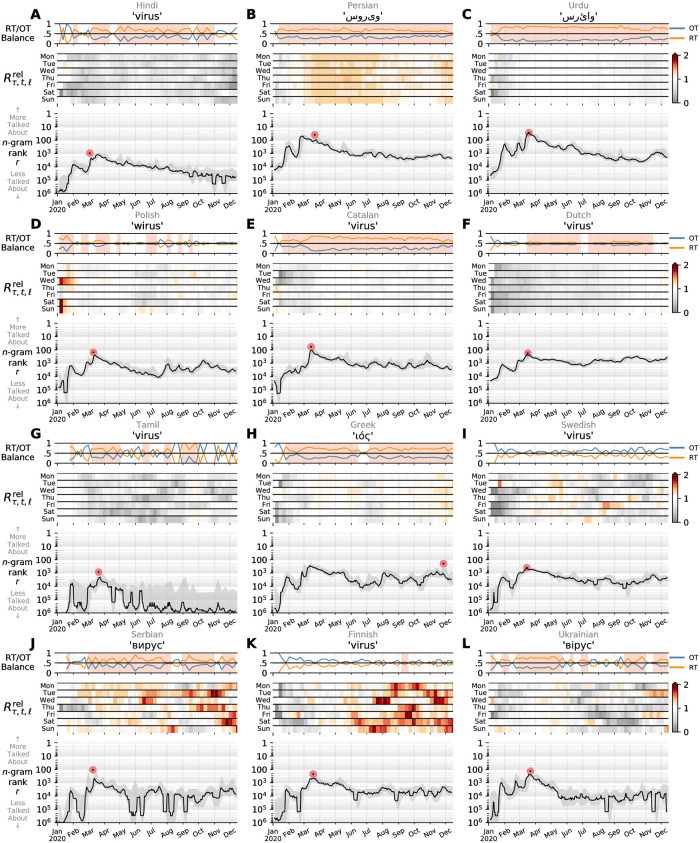
In confronting the global spread of the coronavirus disease COVID-19 pandemic we must have coordinated medical, operational, and political responses. In all efforts, data is crucial. Fundamentally, and in the possible absence of a vaccine for 12 to 18 months, we need universal, well-documented testing for both the presence of the disease as well as confirmed recovery through serological tests for antibodies, and we need to track major socioeconomic indices. But we also need auxiliary data of all kinds, including data related to how populations are talking about the unfolding pandemic through news and stories. To in part help on the social media side, we curate a set of 2000 day-scale time series of 1- and 2-grams across 24 languages on Twitter that are most 'important' for April 2020 with respect to April 2019. We determine importance through our allotaxonometric instrument, rank-turbulence divergence. We make some basic observations about some of the time series, including a comparison to numbers of confirmed deaths due to COVID-19 over time. We broadly observe across all languages a peak for the language-specific word for 'virus' in January 2020 followed by a decline through February and then a surge through March and April. The world's collective attention dropped away while the virus spread out from China. We host the time series on Gitlab, updating them on a daily basis while relevant. Our main intent is for other researchers to use these time series to enhance whatever analyses that may be of use during the pandemic as well as for retrospective investigations.
在应对冠状病毒疾病 COVID-19 大流行的全球传播时,我们必须协调医疗、运营和政治应对措施。在所有努力中,数据至关重要。从根本上说,在未来 12 到 18 个月内可能没有疫苗的情况下,我们需要对疾病的存在以及通过血清学测试对抗体的确认康复进行普遍、有充分记录的检测,我们需要跟踪主要的社会经济指标。但我们还需要各种辅助数据,包括与人们如何通过新闻和故事来谈论正在发生的大流行有关的数据。为了在社交媒体方面提供部分帮助,我们对 24 种语言的 Twitter 上的 1- 和 2-gram 进行了 2000 个日尺度时间序列的整理,这些时间序列在 2020 年 4 月相对于 2019 年 4 月是最重要的。我们通过 allotaxonometric 工具——等级湍度散度来确定重要性。我们对一些时间序列进行了一些基本观察,包括与 COVID-19 确诊死亡人数随时间的比较。我们广泛观察了所有语言,发现 2020 年 1 月出现了特定语言的“病毒”一词的峰值,随后在 2 月和 3 月至 4 月期间下降,然后在 3 月和 4 月期间飙升。随着病毒从中国传播开来,全世界的注意力都转移了。我们将时间序列托管在 Gitlab 上,在相关的情况下每天进行更新。我们的主要目的是让其他研究人员使用这些时间序列来增强在大流行期间可能有用的任何分析,以及进行回顾性调查。