Institute of Social and Preventive Medicine, University of Bern, Bern, Switzerland.
Department of Psychiatry, University of Oxford, Oxford, UK.
Stat Methods Med Res. 2021 May;30(5):1358-1372. doi: 10.1177/0962280220982643. Epub 2021 Jan 27.
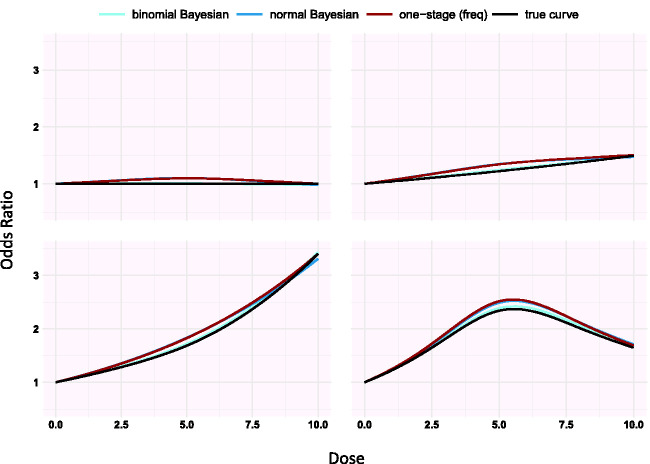
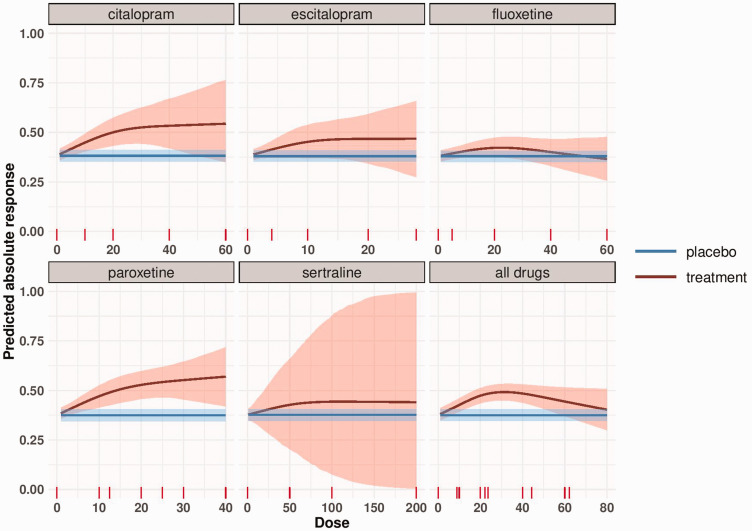
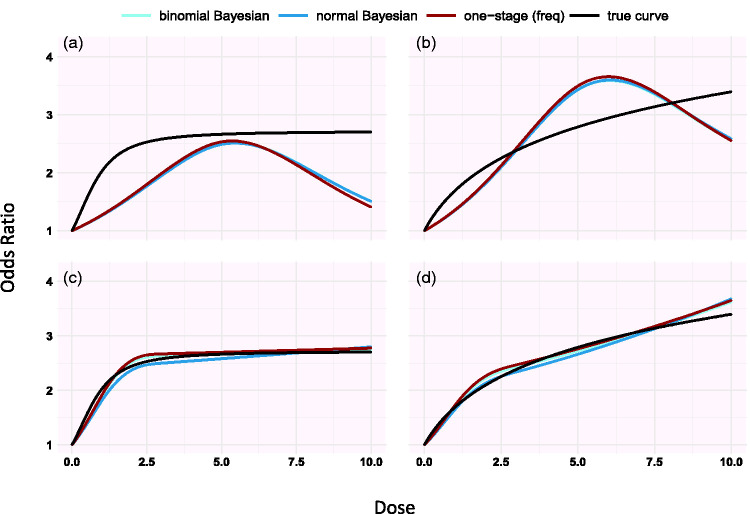
Dose-response models express the effect of different dose or exposure levels on a specific outcome. In meta-analysis, where aggregated-level data is available, dose-response evidence is synthesized using either one-stage or two-stage models in a frequentist setting. We propose a hierarchical dose-response model implemented in a Bayesian framework. We develop our model assuming normal or binomial likelihood and accounting for exposures grouped in clusters. To allow maximum flexibility, the dose-response association is modelled using restricted cubic splines. We implement these models in R using JAGS and we compare our approach to the one-stage dose-response meta-analysis model in a simulation study. We found that the Bayesian dose-response model with binomial likelihood has lower bias than the Bayesian model with normal likelihood and the frequentist one-stage model when studies have small sample size. When the true underlying shape is log-log or half-sigmoid, the performance of all models depends on choosing an appropriate location for the knots. In all other examined situations, all models perform very well and give practically identical results. We also re-analyze the data from 60 randomized controlled trials (15,984 participants) examining the efficacy (response) of various doses of serotonin-specific reuptake inhibitor (SSRI) antidepressant drugs. All models suggest that the dose-response curve increases between zero dose and 30-40 mg of fluoxetine-equivalent dose, and thereafter shows small decline. We draw the same conclusion when we take into account the fact that five different antidepressants have been studied in the included trials. We show that implementation of the hierarchical model in Bayesian framework has similar performance to, but overcomes some of the limitations of the frequentist approach and offers maximum flexibility to accommodate features of the data.
剂量反应模型表达了不同剂量或暴露水平对特定结果的影响。在荟萃分析中,如果有汇总水平的数据,则在频率论框架下使用单阶段或两阶段模型来综合剂量反应证据。我们提出了一种在贝叶斯框架下实现的分层剂量反应模型。我们通过假设正态或二项式似然,并考虑分组暴露,来开发我们的模型。为了允许最大的灵活性,我们使用受限立方样条来模拟剂量反应关联。我们使用 JAGS 在 R 中实现这些模型,并在模拟研究中比较我们的方法与单阶段剂量反应荟萃分析模型。我们发现,当研究样本量较小时,二项式似然的贝叶斯剂量反应模型比正态似然的贝叶斯模型和频率论的单阶段模型具有更低的偏差。当真实的基础形状为对数-对数或半-西格玛时,所有模型的性能取决于为节点选择合适的位置。在所有其他检查的情况下,所有模型都表现得非常好,给出了几乎相同的结果。我们还重新分析了来自 60 项随机对照试验(15984 名参与者)的数据,这些试验研究了各种剂量的 5-羟色胺特异性再摄取抑制剂(SSRI)抗抑郁药的疗效(反应)。所有模型都表明,在零剂量和 30-40mg 氟西汀等效剂量之间,剂量反应曲线增加,然后显示出小的下降。当我们考虑到纳入试验中研究了五种不同的抗抑郁药这一事实时,我们得出了同样的结论。我们表明,在贝叶斯框架下实现分层模型具有与频率论方法相似的性能,但克服了一些局限性,并为适应数据特征提供了最大的灵活性。