Division of Information and Computing Technology, College of Science and Engineering, Hamad Bin Khalifa University, Qatar Foundation, Doha, Qatar.
College of Health and Life Sciences, Hamad Bin Khalifa University, Qatar Foundation, Doha, Qatar.
J Med Internet Res. 2021 Mar 8;23(3):e23703. doi: 10.2196/23703.
Shortly after the emergence of COVID-19, researchers rapidly mobilized to study numerous aspects of the disease such as its evolution, clinical manifestations, effects, treatments, and vaccinations. This led to a rapid increase in the number of COVID-19-related publications. Identifying trends and areas of interest using traditional review methods (eg, scoping and systematic reviews) for such a large domain area is challenging.
We aimed to conduct an extensive bibliometric analysis to provide a comprehensive overview of the COVID-19 literature.
We used the COVID-19 Open Research Dataset (CORD-19) that consists of a large number of research articles related to all coronaviruses. We used a machine learning-based method to analyze the most relevant COVID-19-related articles and extracted the most prominent topics. Specifically, we used a clustering algorithm to group published articles based on the similarity of their abstracts to identify research hotspots and current research directions. We have made our software accessible to the community via GitHub.
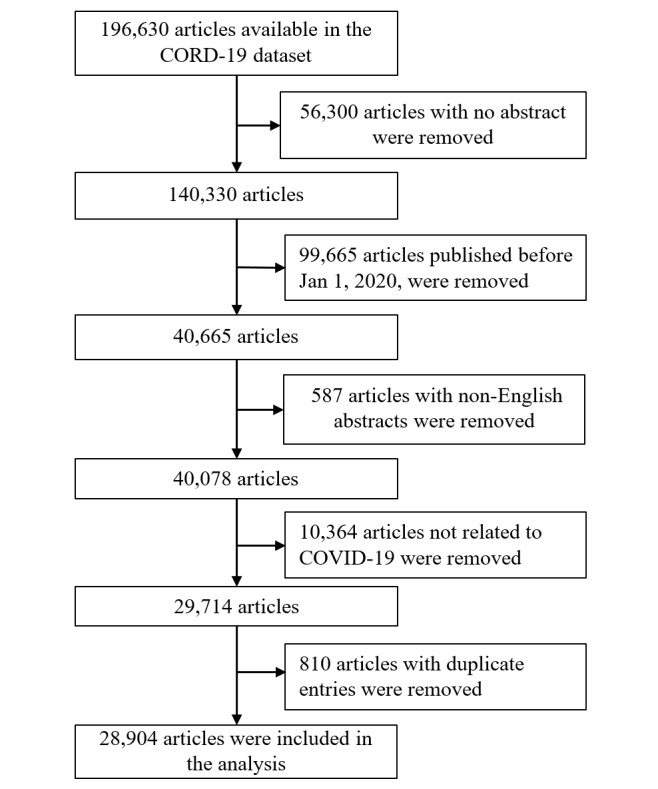
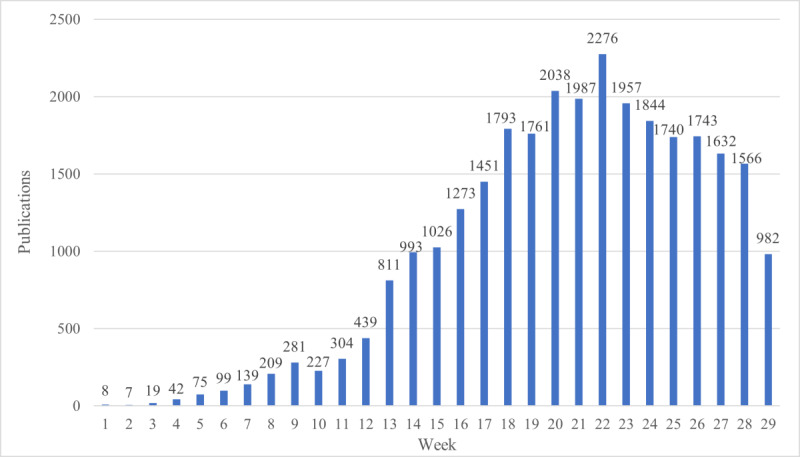
Of the 196,630 publications retrieved from the database, we included 28,904 in our analysis. The mean number of weekly publications was 990 (SD 789.3). The country that published the highest number of COVID-19-related articles was China (2950/17,270, 17.08%). The highest number of articles were published in bioRxiv. Lei Liu affiliated with the Southern University of Science and Technology in China published the highest number of articles (n=46). Based on titles and abstracts alone, we were able to identify 1515 surveys, 733 systematic reviews, 512 cohort studies, 480 meta-analyses, and 362 randomized control trials. We identified 19 different topics covered among the publications reviewed. The most dominant topic was public health response, followed by clinical care practices during the COVID-19 pandemic, clinical characteristics and risk factors, and epidemic models for its spread.
We provide an overview of the COVID-19 literature and have identified current hotspots and research directions. Our findings can be useful for the research community to help prioritize research needs and recognize leading COVID-19 researchers, institutes, countries, and publishers. Our study shows that an AI-based bibliometric analysis has the potential to rapidly explore a large corpus of academic publications during a public health crisis. We believe that this work can be used to analyze other eHealth-related literature to help clinicians, administrators, and policy makers to obtain a holistic view of the literature and be able to categorize different topics of the existing research for further analyses. It can be further scaled (for instance, in time) to clinical summary documentation. Publishers should avoid noise in the data by developing a way to trace the evolution of individual publications and unique authors.
新冠疫情爆发后不久,研究人员迅速行动起来,研究疾病的诸多方面,如疾病的演变、临床表现、影响、治疗和疫苗接种等。这导致与 COVID-19 相关的出版物数量迅速增加。使用传统的综述方法(例如,范围和系统综述)来确定如此大的领域的趋势和关注领域具有挑战性。
我们旨在进行广泛的文献计量分析,以提供 COVID-19 文献的综合概述。
我们使用了包含大量与所有冠状病毒相关研究文章的 COVID-19 开放研究数据集 (CORD-19)。我们使用基于机器学习的方法来分析与 COVID-19 最相关的文章,并提取最突出的主题。具体来说,我们使用聚类算法根据其摘要的相似性对已发表的文章进行分组,以识别研究热点和当前的研究方向。我们已经通过 GitHub 向社区提供了我们的软件。
从数据库中检索到的 196630 篇出版物中,我们纳入了 28904 篇进行分析。每周出版物的平均数量为 990 篇(SD 789.3)。发表与 COVID-19 相关文章数量最多的国家是中国(2950/17270,17.08%)。发表文章最多的出版物是 bioRxiv。中国南方科技大学的 Lei Liu 发表的文章数量最多(n=46)。仅根据标题和摘要,我们就能够识别出 1515 项调查、733 项系统评价、512 项队列研究、480 项荟萃分析和 362 项随机对照试验。我们在审查的出版物中确定了 19 个不同的主题。最主要的主题是公共卫生应对,其次是 COVID-19 大流行期间的临床护理实践、临床特征和危险因素以及传播的流行模型。
我们提供了 COVID-19 文献的概述,并确定了当前的热点和研究方向。我们的研究结果可以为研究界提供帮助,确定研究需求的优先级,并识别领先的 COVID-19 研究人员、机构、国家和出版商。我们的研究表明,基于人工智能的文献计量分析具有在公共卫生危机期间快速探索大量学术出版物的潜力。我们相信这项工作可以用于分析其他电子健康相关文献,以帮助临床医生、管理人员和政策制定者全面了解文献,并能够对现有研究的不同主题进行分类,以便进一步分析。它可以进一步扩展(例如,在时间上)到临床总结文件。出版商应通过开发一种跟踪单个出版物和独特作者演变的方法来避免数据中的噪音。