Centre for Translational Data Science, The University of Sydney, Sydney, Australia.
Northern Clinical School, The University of Sydney, Sydney, Australia.
BMC Med Inform Decis Mak. 2021 Mar 8;21(1):91. doi: 10.1186/s12911-021-01441-w.
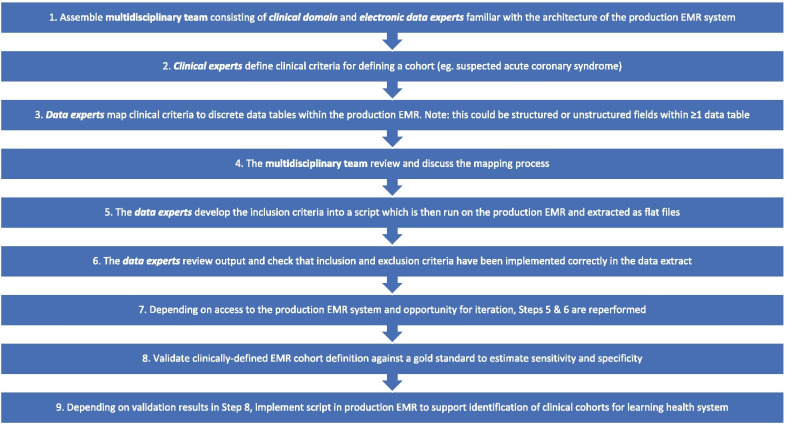
There have been few studies describing how production EMR systems can be systematically queried to identify clinically-defined populations and limited studies utilising free-text in this process. The aim of this study is to provide a generalisable methodology for constructing clinically-defined EMR-derived patient cohorts using structured and unstructured data in EMRs.
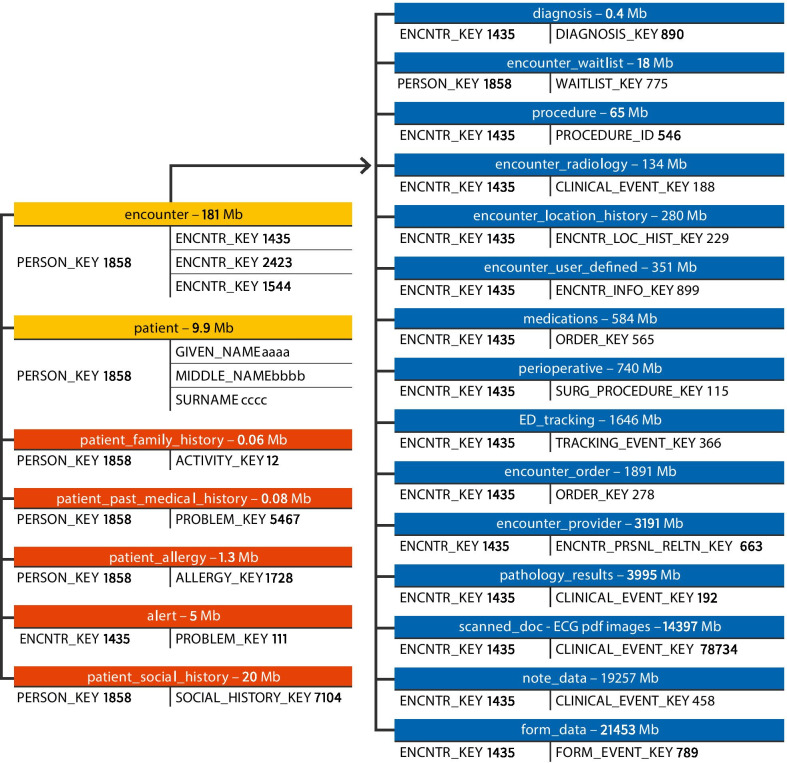
Patients with possible acute coronary syndrome (ACS) were used as an exemplar. Cardiologists defined clinical criteria for patients presenting with possible ACS. These were mapped to data tables within the production EMR system creating seven inclusion criteria comprised of structured data fields (orders and investigations, procedures, scanned electrocardiogram (ECG) images, and diagnostic codes) and unstructured clinical documentation. Data were extracted from two local health districts (LHD) in Sydney, Australia. Outcome measures included examination of the relative contribution of individual inclusion criteria to the identification of eligible encounters, comparisons between inclusion criterion and evaluation of consistency of data extracts across years and LHDs.
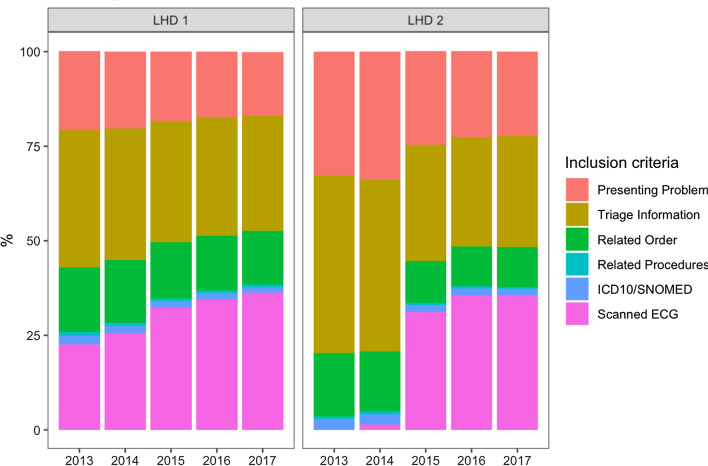
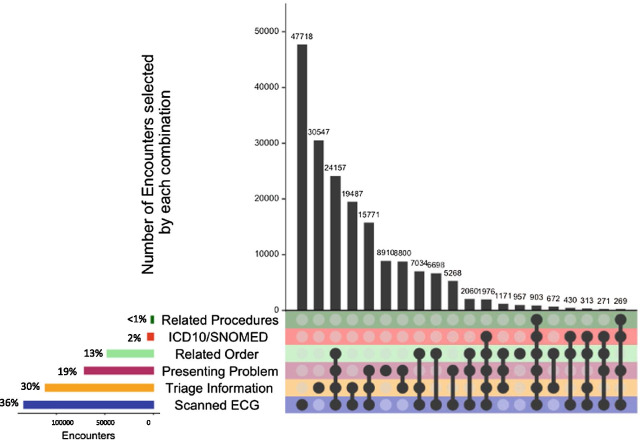
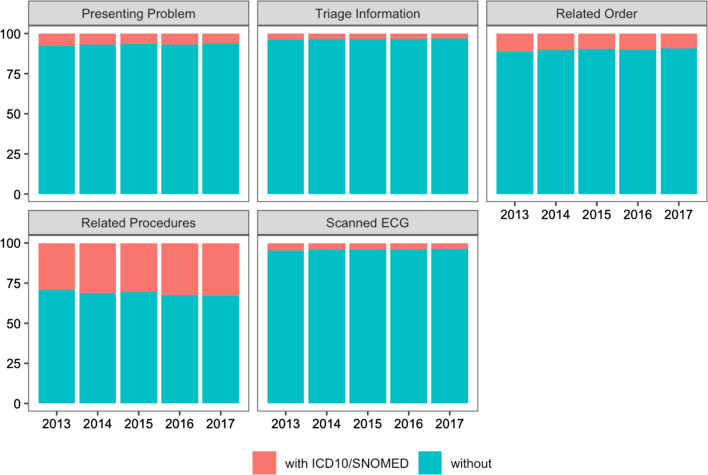
Among 802,742 encounters in a 5 year dataset (1/1/13-30/12/17), the presence of an ECG image (54.8% of encounters) and symptoms and keywords in clinical documentation (41.4-64.0%) were used most often to identify presentations of possible ACS. Orders and investigations (27.3%) and procedures (1.4%), were less often present for identified presentations. Relevant ICD-10/SNOMED CT codes were present for 3.7% of identified encounters. Similar trends were seen when the two LHDs were examined separately, and across years.
Clinically-defined EMR-derived cohorts combining structured and unstructured data during cohort identification is a necessary prerequisite for critical validation work required for development of real-time clinical decision support and learning health systems.
描述如何系统地查询生产电子病历 (EMR) 系统以识别临床定义人群的研究较少,利用这一过程中的自由文本进行的研究也有限。本研究的目的是提供一种可推广的方法,用于使用 EMR 中的结构化和非结构化数据构建临床定义的 EMR 衍生患者队列。
以可能的急性冠状动脉综合征 (ACS) 患者为例。心脏病专家为可能出现 ACS 的患者定义了临床标准。这些标准被映射到生产 EMR 系统中的数据表中,创建了七个包含结构化数据字段(医嘱和检查、程序、扫描心电图 (ECG) 图像和诊断代码)和非结构化临床文档的纳入标准。数据从澳大利亚悉尼的两个地方卫生区 (LHD) 中提取。结果测量包括检查各个纳入标准对确定合格就诊的相对贡献,以及对纳入标准的比较和对跨年份和 LHD 的数据提取的一致性的评估。
在 5 年数据集(2013 年 1 月 1 日至 2017 年 12 月 30 日)中的 802,742 次就诊中,最常用于识别可能 ACS 表现的是 ECG 图像的存在(54.8%的就诊)和临床文档中的症状和关键字(41.4-64.0%)。对于确定的表现,医嘱和检查(27.3%)和程序(1.4%)不太常见。确定的就诊中,相关的 ICD-10/SNOMED CT 代码存在 3.7%。当分别检查两个 LHD 以及跨年份时,也出现了类似的趋势。
在队列识别过程中结合结构化和非结构化数据进行临床定义的 EMR 衍生队列是开发实时临床决策支持和学习健康系统所需的关键验证工作的必要前提。