Hart Gregory R, Nartowt Bradley J, Muhammad Wazir, Liang Ying, Huang Gloria S, Deng Jun
Department of Therapeutic Radiology, School of Medicine, Yale University, New Haven, CT, United States.
Department of Obstetrics, Gynecology and Reproductive Sciences, School of Medicine, Yale University, New Haven, CT, United States.
Front Big Data. 2019 Jul 2;2:24. doi: 10.3389/fdata.2019.00024. eCollection 2019.
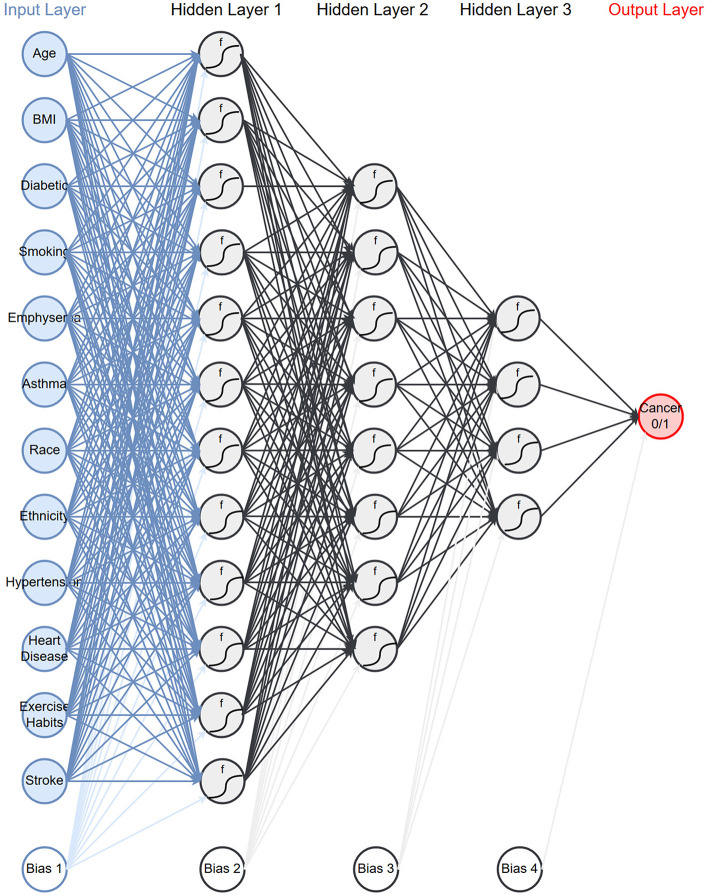
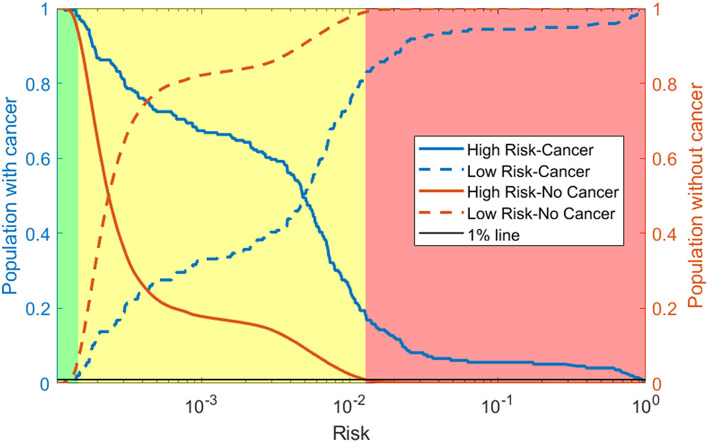
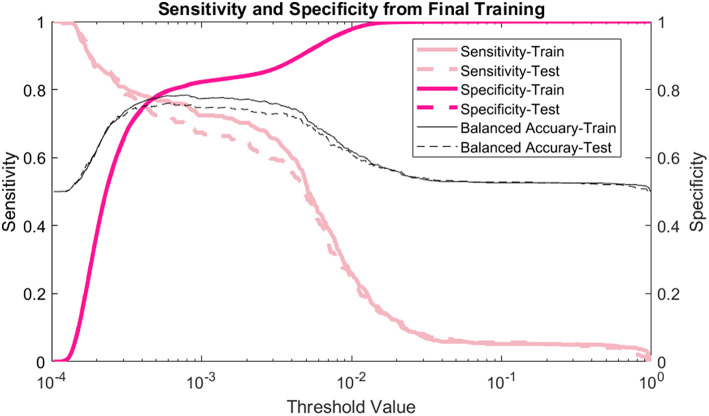
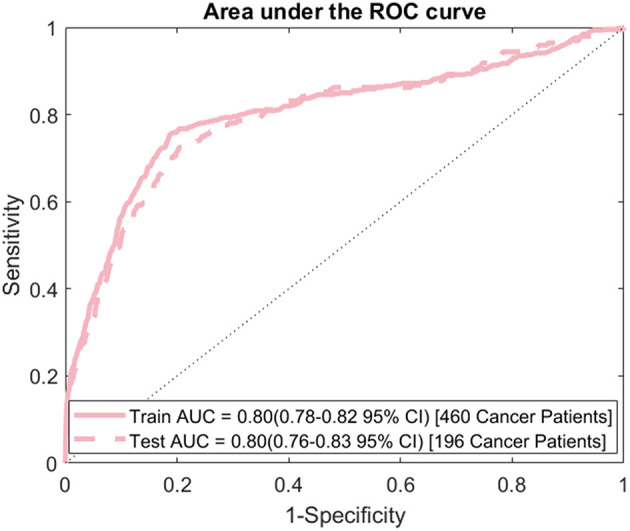
Screening the general population for ovarian cancer is not recommended by every major medical or public health organization because the harms from screening outweigh the benefit it provides. To improve ovarian cancer detection and survival many are looking at high-risk populations who would benefit from screening. We train a neural network on readily available personal health data to predict and stratify ovarian cancer risk. We use two different datasets to train our network: The National Health Interview Survey and Prostate, Lung, Colorectal, and Ovarian Cancer Screening Trial. Our model has an area under the receiver operating characteristic curve of 0.71. We further demonstrate how the model could be used to stratify patients into different risk categories. A simple 3-tier scheme classifies 23.8% of those with cancer and 1.0% of those without as high-risk similar to genetic testing, and 1.1% of those with cancer and 24.4% of those without as low risk. The developed neural network offers a cost-effective and non-invasive way to identify those who could benefit from targeted screening.
各大医学或公共卫生组织均不建议对普通人群进行卵巢癌筛查,因为筛查的危害大于其带来的益处。为了提高卵巢癌的检测率和生存率,许多人将目光投向了能从筛查中获益的高危人群。我们基于现有的个人健康数据训练了一个神经网络,以预测和分层卵巢癌风险。我们使用两个不同的数据集来训练网络:《国民健康访谈调查》和《前列腺、肺、结肠和卵巢癌筛查试验》。我们的模型在受试者工作特征曲线下的面积为0.71。我们进一步展示了该模型如何用于将患者分层到不同的风险类别。一个简单的三层方案将23.8%的癌症患者和1.0%的非癌症患者归类为高风险,类似于基因检测,将1.1%的癌症患者和24.4%的非癌症患者归类为低风险。所开发的神经网络提供了一种经济高效且非侵入性的方法来识别那些能从靶向筛查中获益的人群。