Ithree Institute, University of Technology Sydney, Broadway, PO Box 123, Ultimo, NSW, 2007, Australia.
Proteomics Core Facility, University of Technology Sydney, Broadway, PO Box 123, Ultimo, NSW, 2007, Australia.
Sci Rep. 2021 Mar 24;11(1):6743. doi: 10.1038/s41598-021-86217-y.
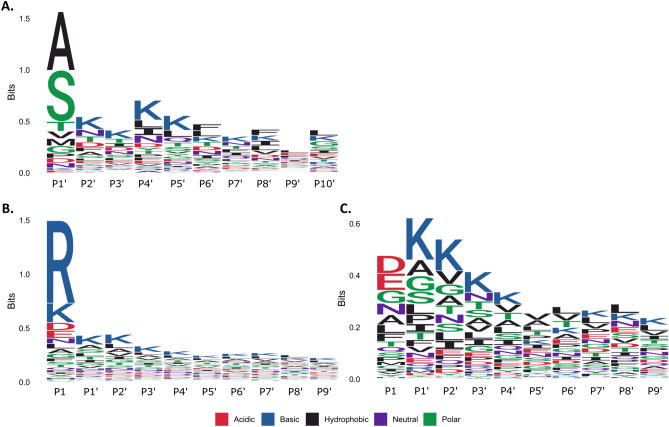
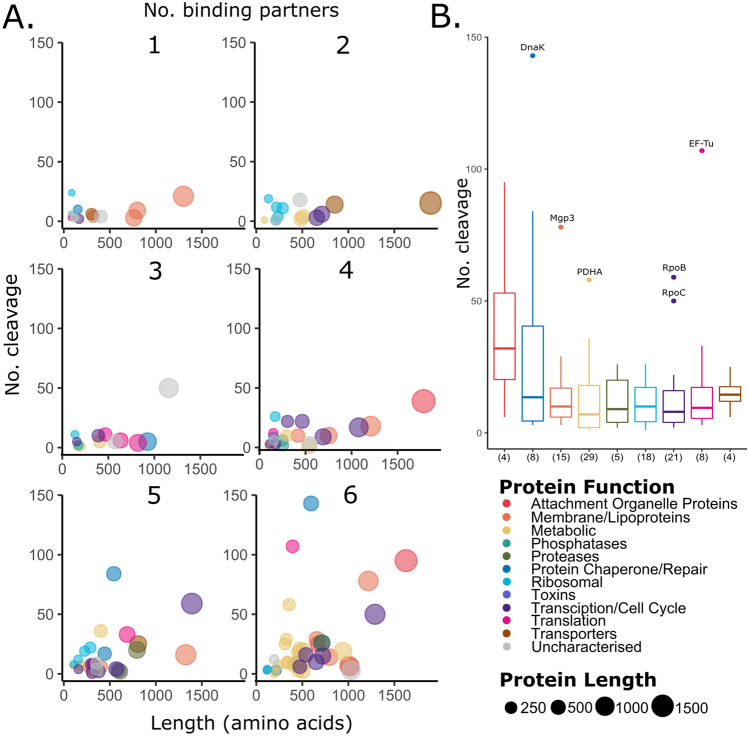
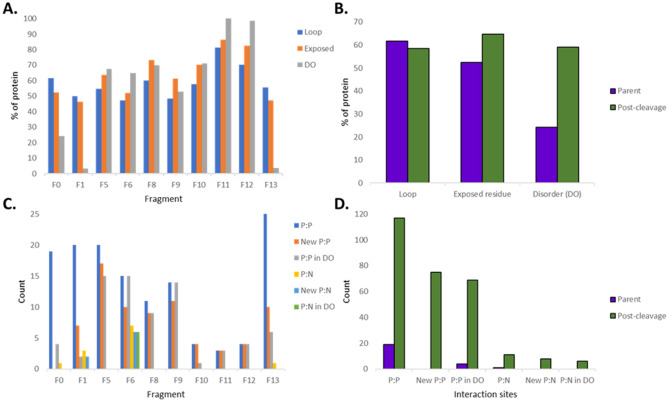
Mycoplasma pneumoniae is a significant cause of pneumonia and post infection sequelae affecting organ sites distant to the respiratory tract are common. It is also a model organism where extensive 'omics' studies have been conducted to gain insight into how minimal genome self-replicating organisms function. An N-terminome study undertaken here identified 4898 unique N-terminal peptides that mapped to 391 (56%) predicted M. pneumoniae proteins. True N-terminal sequences beginning with the initiating methionine (iMet) residue from the predicted Open Reading Frame (ORF) were identified for 163 proteins. Notably, almost half (317; 46%) of the ORFS derived from M. pneumoniae strain M129 are post-translationally modified, presumably by proteolytic processing, because dimethyl labelled neo-N-termini were characterised that mapped beyond the predicted N-terminus. An analysis of the N-terminome describes endoproteolytic processing events predominately targeting tryptic-like sites, though cleavages at negatively charged residues in P1' (D and E) with lysine or serine/alanine in P2' and P3' positions also occurred frequently. Surfaceome studies identified 160 proteins (23% of the proteome) to be exposed on the extracellular surface of M. pneumoniae. The two orthogonal methodologies used to characterise the surfaceome each identified the same 116 proteins, a 72% (116/160) overlap. Apart from lipoproteins, transporters, and adhesins, 93/160 (58%) of the surface proteins lack signal peptides and have well characterised, canonical functions in the cell. Of the 160 surface proteins identified, 134 were also targets of endo-proteolytic processing. These processing events are likely to have profound implications for how the host immune system recognises and responds to M. pneumoniae.
肺炎支原体是引起肺炎的重要原因,感染后呼吸道以外的器官发生后遗症较为常见。它也是一种模式生物,广泛的“组学”研究已经进行,以深入了解最小基因组自我复制的生物体如何发挥作用。这里进行的 N 端组学研究鉴定了 4898 个独特的 N 端肽,这些肽映射到 391 个(56%)预测的肺炎支原体蛋白。从预测的开放阅读框(ORF)起始甲硫氨酸(iMet)残基开始,鉴定了 163 个蛋白的真实 N 端序列。值得注意的是,M129 株衍生的 ORFS 中几乎有一半(317 个;46%)是经过翻译后修饰的,推测是通过蛋白水解加工修饰的,因为鉴定出了与预测 N 端之外映射的二甲基标记的新 N 端。N 端组学分析描述了主要针对胰蛋白酶样位点的内切蛋白酶加工事件,但在 P1'(D 和 E)位带有负电荷的残基处,以及 P2' 和 P3'位带有赖氨酸或丝氨酸/丙氨酸的切割也经常发生。表面组学研究鉴定出 160 种蛋白(占蛋白质组的 23%)暴露在肺炎支原体的细胞外表面。用于描述表面组学的两种正交方法都鉴定出了相同的 116 种蛋白,重叠率为 72%(116/160)。除了脂蛋白、转运蛋白和黏附素外,160 种表面蛋白中有 93 种(58%)缺乏信号肽,它们在细胞中有明确的、典型的功能。在鉴定的 160 种表面蛋白中,有 134 种也是内切蛋白酶加工的靶标。这些加工事件可能对宿主免疫系统识别和应对肺炎支原体有深远的影响。