Cell Signalling & Proteomics Group, Centre for Genomics & Computational Biology, Barts Cancer Institute, Queen Mary University of London, Charterhouse Square, London, UK.
Kinomica Ltd, Alderley Park, Alderley Edge, Macclesfield, UK.
Nat Commun. 2021 Mar 25;12(1):1850. doi: 10.1038/s41467-021-22170-8.
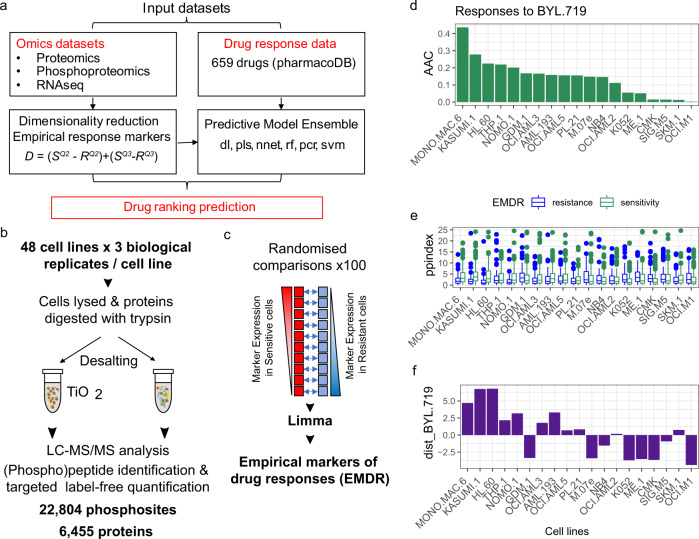
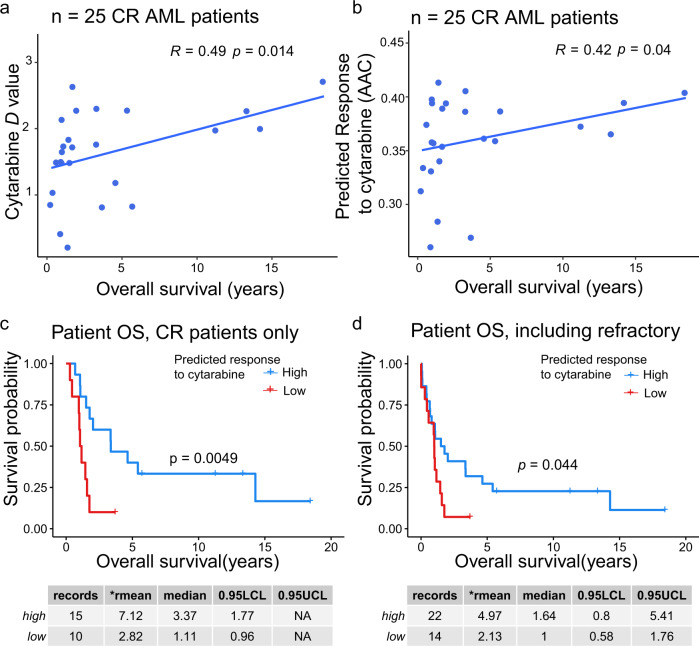
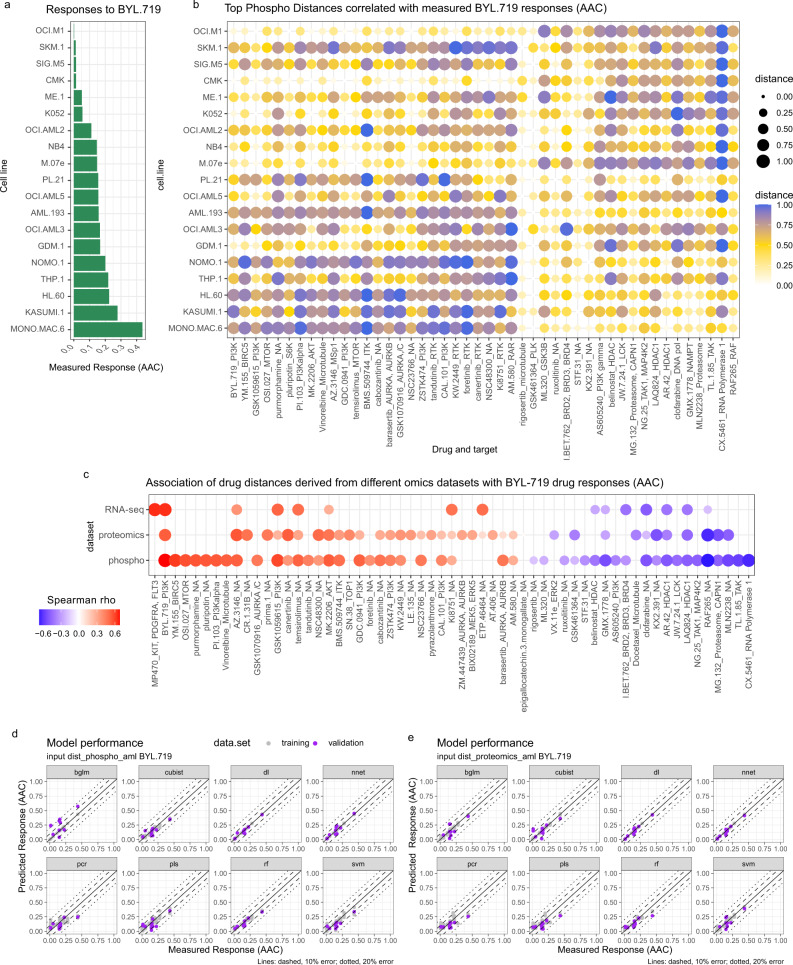
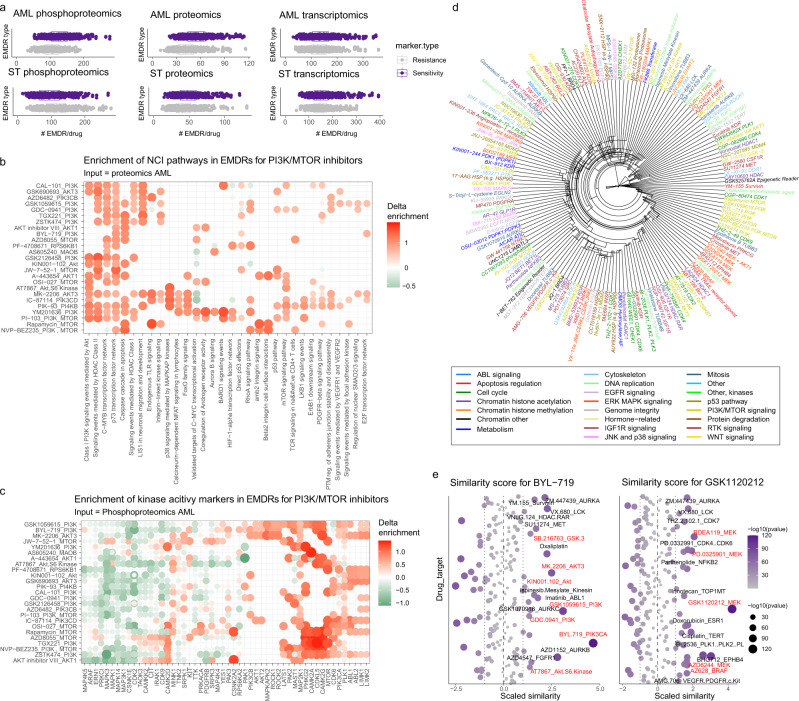
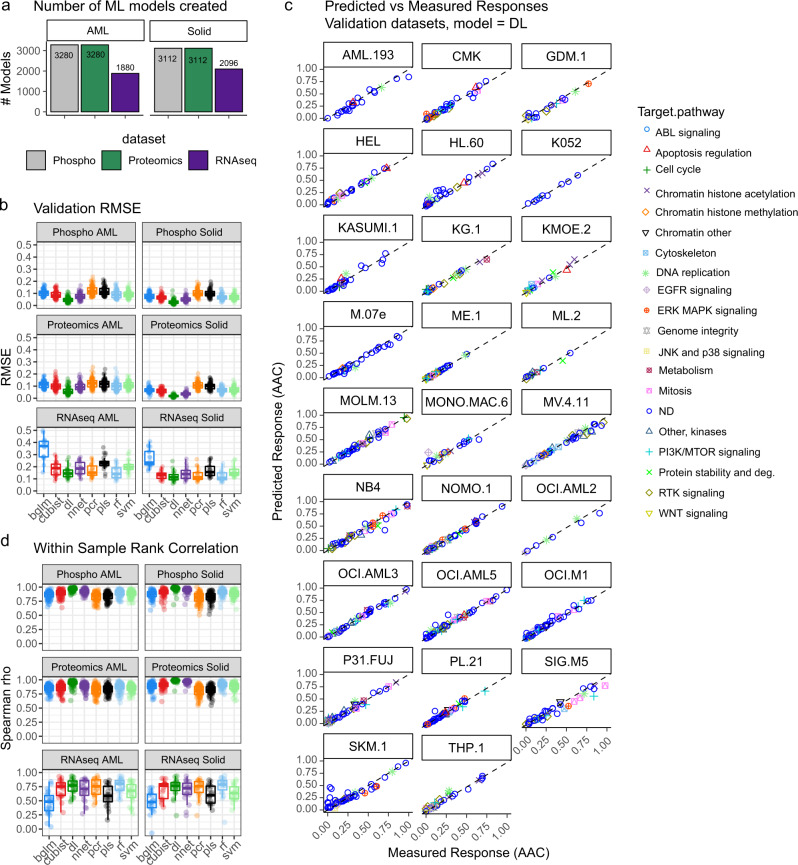
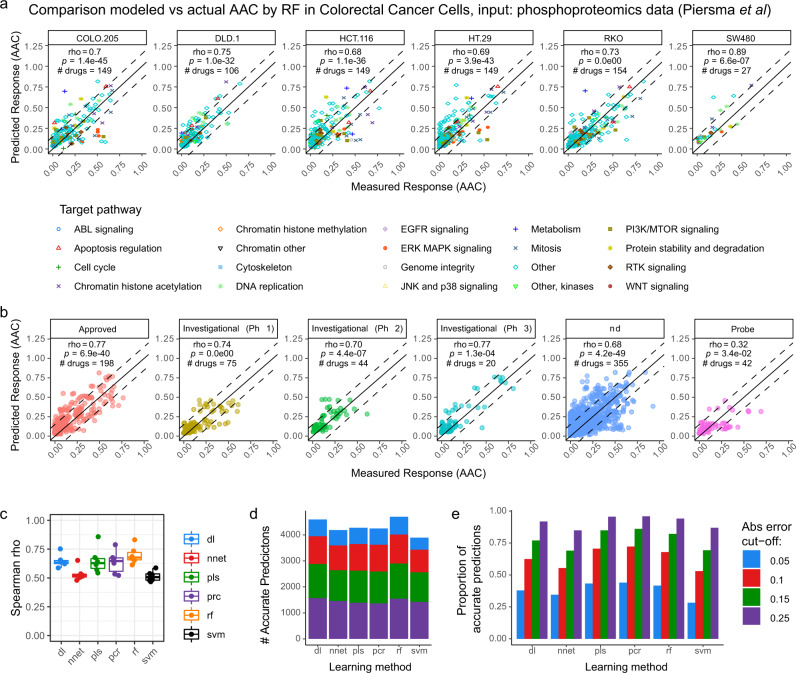
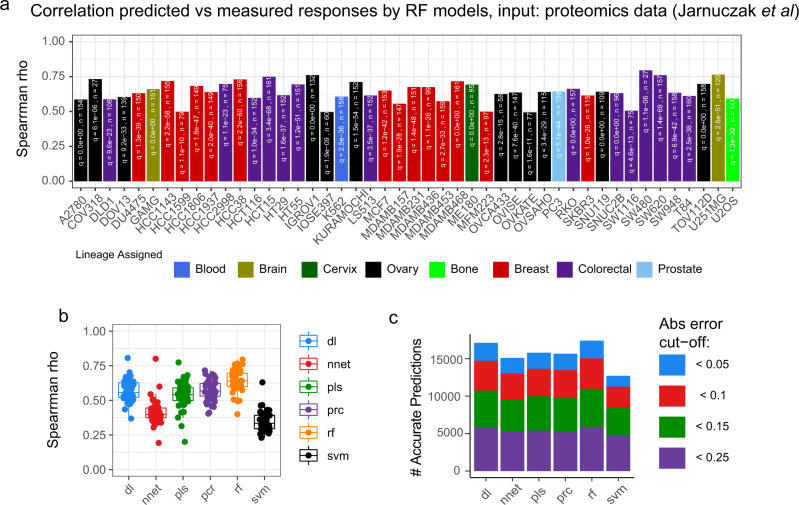
Artificial intelligence and machine learning (ML) promise to transform cancer therapies by accurately predicting the most appropriate therapies to treat individual patients. Here, we present an approach, named Drug Ranking Using ML (DRUML), which uses omics data to produce ordered lists of >400 drugs based on their anti-proliferative efficacy in cancer cells. To reduce noise and increase predictive robustness, instead of individual features, DRUML uses internally normalized distance metrics of drug response as features for ML model generation. DRUML is trained using in-house proteomics and phosphoproteomics data derived from 48 cell lines, and it is verified with data comprised of 53 cellular models from 12 independent laboratories. We show that DRUML predicts drug responses in independent verification datasets with low error (mean squared error < 0.1 and mean Spearman's rank 0.7). In addition, we demonstrate that DRUML predictions of cytarabine sensitivity in clinical leukemia samples are prognostic of patient survival (Log rank p < 0.005). Our results indicate that DRUML accurately ranks anti-cancer drugs by their efficacy across a wide range of pathologies.
人工智能和机器学习 (ML) 有望通过准确预测最适合治疗个体患者的疗法来改变癌症治疗方法。在这里,我们提出了一种名为基于机器学习的药物排序 (DRUML) 的方法,该方法使用组学数据根据癌细胞中的抗增殖功效对 >400 种药物进行排序。为了减少噪声并提高预测稳健性,DRUML 不是使用单个特征,而是使用药物反应的内部归一化距离度量作为 ML 模型生成的特征。DRUML 使用源自 48 个细胞系的内部蛋白质组学和磷酸化蛋白质组学数据进行训练,并使用来自 12 个独立实验室的 53 个细胞模型数据进行验证。我们表明,DRUML 在独立验证数据集中以低误差(均方误差 < 0.1 和平均 Spearman 等级 0.7)预测药物反应。此外,我们证明 DRUML 对临床白血病样本中阿糖胞苷敏感性的预测对患者生存具有预后意义(对数秩检验 p < 0.005)。我们的结果表明,DRUML 可以准确地根据其在广泛病理范围内的功效对抗癌药物进行排序。