Department of Computer Science, University of Toronto, Toronto, ON, Canada.
Vector Institute for Artificial Intelligence, Toronto, ON, Canada.
J Med Internet Res. 2021 Apr 23;23(4):e26628. doi: 10.2196/26628.
National governments worldwide have implemented nonpharmaceutical interventions to control the COVID-19 pandemic and mitigate its effects.
The aim of this study was to investigate the prediction of future daily national confirmed COVID-19 infection growth-the percentage change in total cumulative cases-across 14 days for 114 countries using nonpharmaceutical intervention metrics and cultural dimension metrics, which are indicative of specific national sociocultural norms.
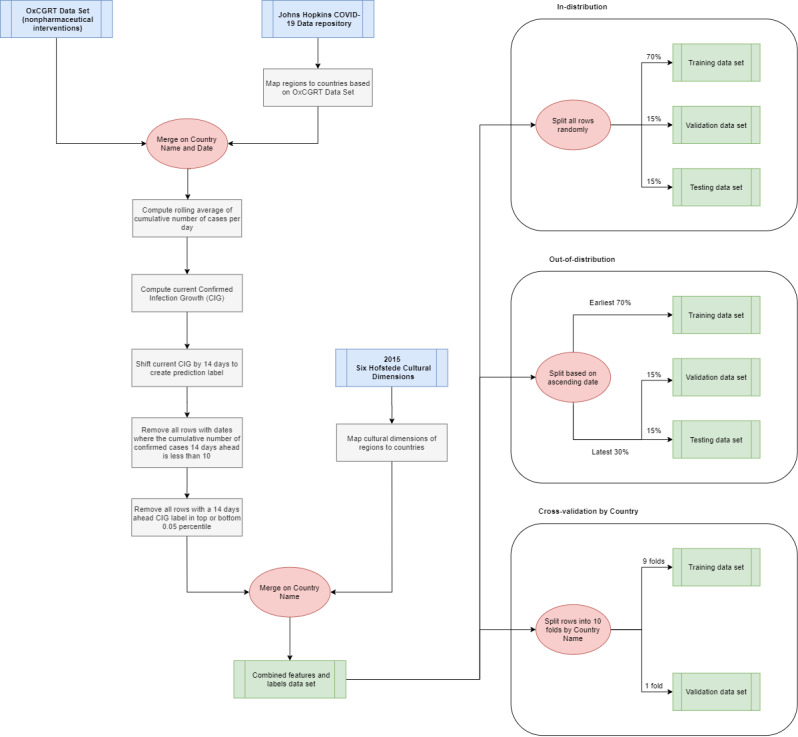
We combined the Oxford COVID-19 Government Response Tracker data set, Hofstede cultural dimensions, and daily reported COVID-19 infection case numbers to train and evaluate five non-time series machine learning models in predicting confirmed infection growth. We used three validation methods-in-distribution, out-of-distribution, and country-based cross-validation-for the evaluation, each of which was applicable to a different use case of the models.
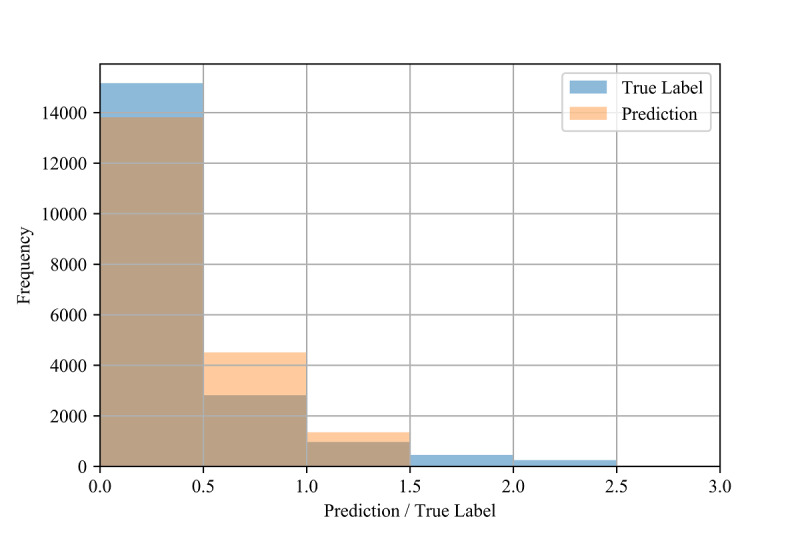
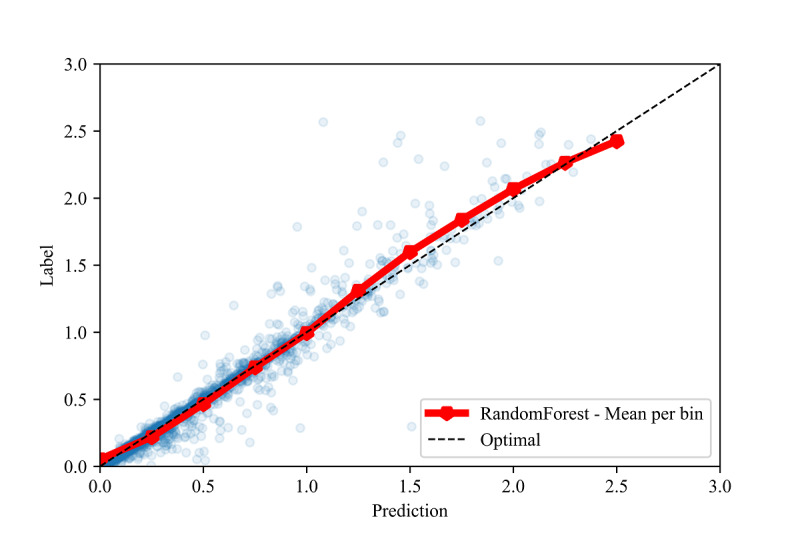
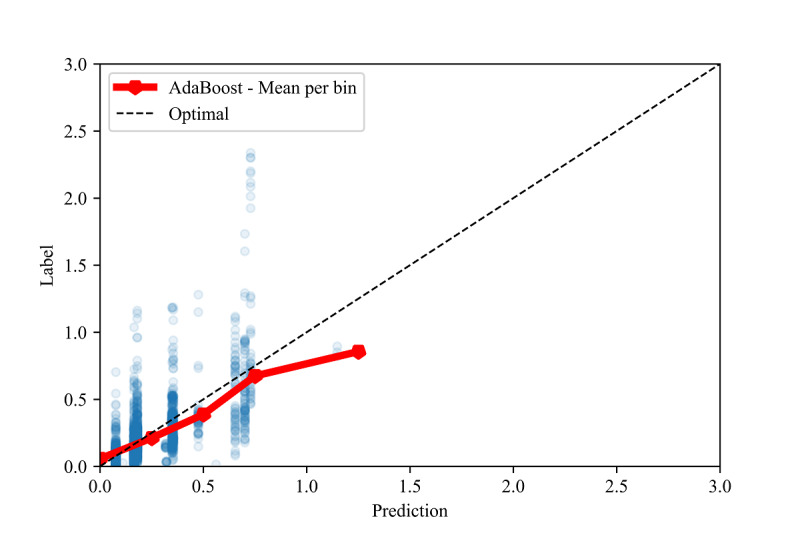
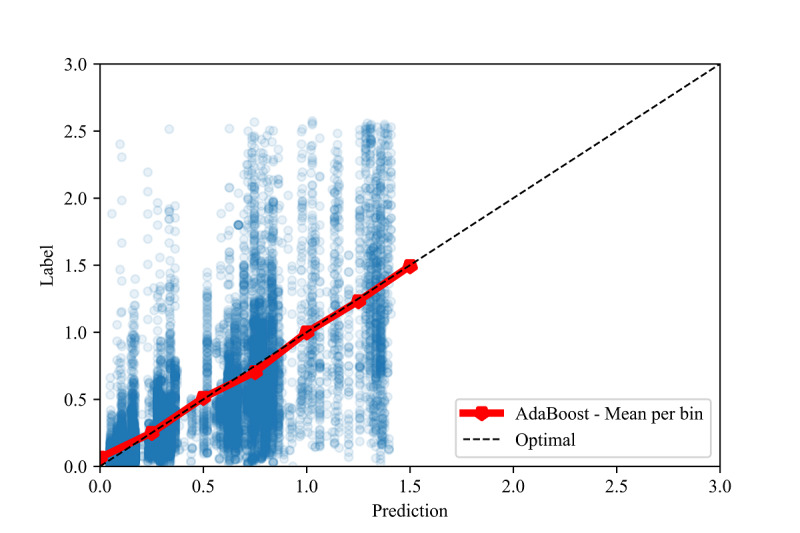
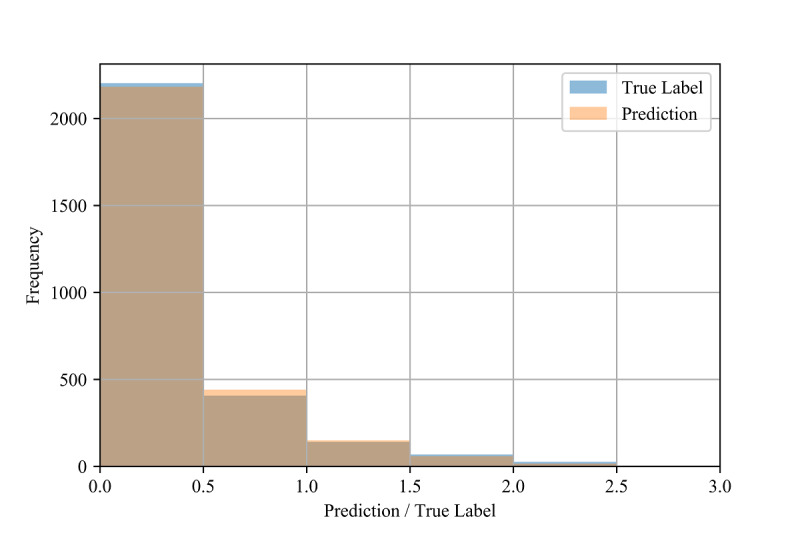
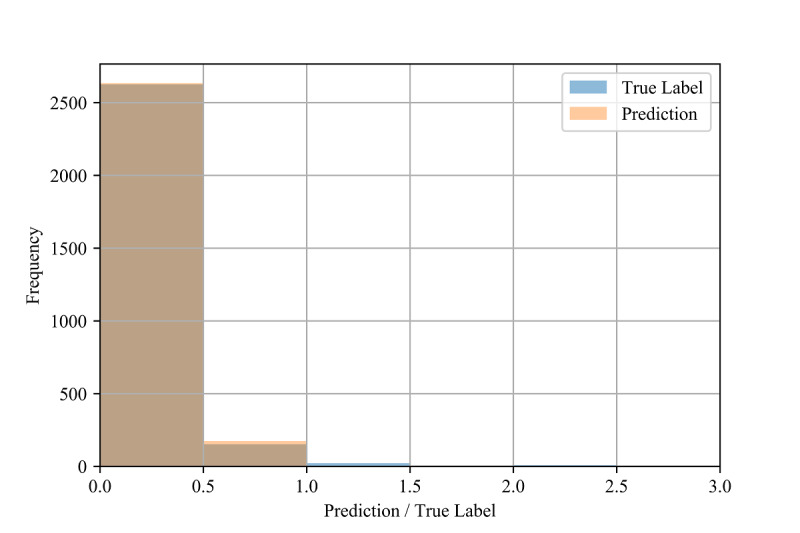
Our results demonstrate high R values between the labels and predictions for the in-distribution method (0.959) and moderate R values for the out-of-distribution and country-based cross-validation methods (0.513 and 0.574, respectively) using random forest and adaptive boosting (AdaBoost) regression. Although these models may be used to predict confirmed infection growth, the differing accuracies obtained from the three tasks suggest a strong influence of the use case.
This work provides new considerations in using machine learning techniques with nonpharmaceutical interventions and cultural dimensions as metrics to predict the national growth of confirmed COVID-19 infections.
全球各国政府已实施非药物干预措施来控制 COVID-19 大流行并减轻其影响。
本研究旨在利用非药物干预措施和文化维度指标(反映特定国家社会文化规范),预测 114 个国家未来 14 天每日全国确诊 COVID-19 感染增长率(总累计病例的百分比变化)。
我们结合牛津 COVID-19 政府反应追踪器数据集、霍夫斯泰德文化维度和每日报告的 COVID-19 感染病例数,训练和评估五个非时间序列机器学习模型,以预测确诊感染增长率。我们使用三种验证方法(分布内、分布外和基于国家的交叉验证)进行评估,每种方法都适用于模型的不同用例。
我们的结果表明,使用随机森林和自适应增强(AdaBoost)回归,分布内方法的标签和预测之间的 R 值很高(0.959),分布外和基于国家的交叉验证方法的 R 值适中(分别为 0.513 和 0.574)。虽然这些模型可用于预测确诊感染增长率,但从三个任务中获得的不同准确性表明,用例的影响很大。
这项工作提供了在使用机器学习技术和非药物干预措施以及文化维度作为指标来预测全国确诊 COVID-19 感染增长率方面的新考虑因素。