Psychological Sciences, University of Connecticut.
BCBL, Basque Center on Cognition Brain and Language.
Cogn Sci. 2021 Apr;45(4):e12962. doi: 10.1111/cogs.12962.
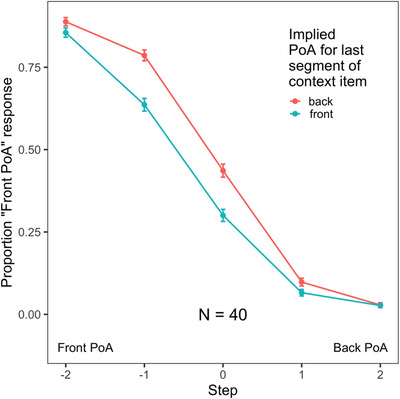
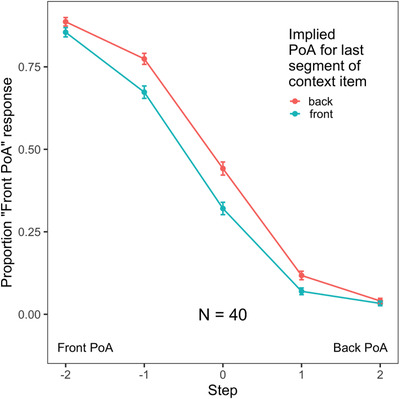
A long-standing question in cognitive science is how high-level knowledge is integrated with sensory input. For example, listeners can leverage lexical knowledge to interpret an ambiguous speech sound, but do such effects reflect direct top-down influences on perception or merely postperceptual biases? A critical test case in the domain of spoken word recognition is lexically mediated compensation for coarticulation (LCfC). Previous LCfC studies have shown that a lexically restored context phoneme (e.g., /s/ in Christma#) can alter the perceived place of articulation of a subsequent target phoneme (e.g., the initial phoneme of a stimulus from a tapes-capes continuum), consistent with the influence of an unambiguous context phoneme in the same position. Because this phoneme-to-phoneme compensation for coarticulation is considered sublexical, scientists agree that evidence for LCfC would constitute strong support for top-down interaction. However, results from previous LCfC studies have been inconsistent, and positive effects have often been small. Here, we conducted extensive piloting of stimuli prior to testing for LCfC. Specifically, we ensured that context items elicited robust phoneme restoration (e.g., that the final phoneme of Christma# was reliably identified as /s/) and that unambiguous context-final segments (e.g., a clear /s/ at the end of Christmas) drove reliable compensation for coarticulation for a subsequent target phoneme. We observed robust LCfC in a well-powered, preregistered experiment with these pretested items (N = 40) as well as in a direct replication study (N = 40). These results provide strong evidence in favor of computational models of spoken word recognition that include top-down feedback.
认知科学中长期存在的一个问题是如何将高层知识与感官输入相结合。例如,听者可以利用词汇知识来解释一个模糊的语音,但这些影响是否反映了对感知的直接自上而下的影响,还是仅仅是感知后的偏见?在口语识别领域的一个关键测试案例是词汇介导的协同发音补偿(LCfC)。以前的 LCfC 研究表明,词汇恢复的上下文音素(例如,Christma#中的/s/)可以改变后续目标音素的感知发音位置(例如,从 tapes-capes 连续体刺激的初始音素),这与同一位置上明确上下文音素的影响一致。由于这种协同发音的音素到音素补偿被认为是亚词汇的,科学家们一致认为,LCfC 的证据将为自上而下的相互作用提供强有力的支持。然而,以前的 LCfC 研究结果不一致,并且积极的影响往往很小。在这里,我们在进行 LCfC 测试之前,对刺激进行了广泛的预测试。具体来说,我们确保上下文项目引起了强大的音素恢复(例如,Christma#的最后一个音素被可靠地识别为/s/),并且明确的上下文结尾部分(例如,Christmas 结尾处清晰的/s/)为后续目标音素的协同发音补偿驱动了可靠的补偿。我们在这些预测试项目的强大、预先注册的实验(N=40)以及直接复制研究(N=40)中观察到了强大的 LCfC。这些结果为包括自上而下反馈的口语识别计算模型提供了强有力的证据。