Department of Psychiatry, University of Münster, Münster, Germany.
Faculty of Mathematics and Computer Science, University of Münster, Münster, Germany.
Neuropsychopharmacology. 2021 Jul;46(8):1510-1517. doi: 10.1038/s41386-021-01020-7. Epub 2021 May 6.
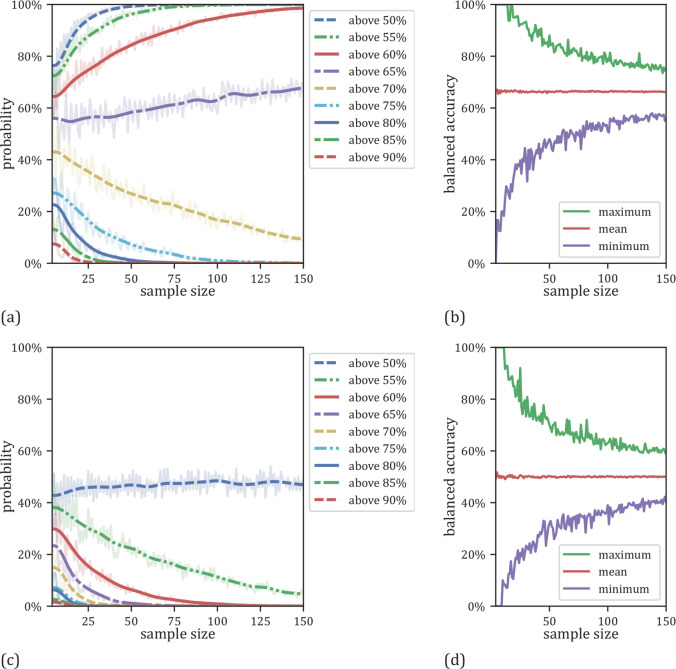
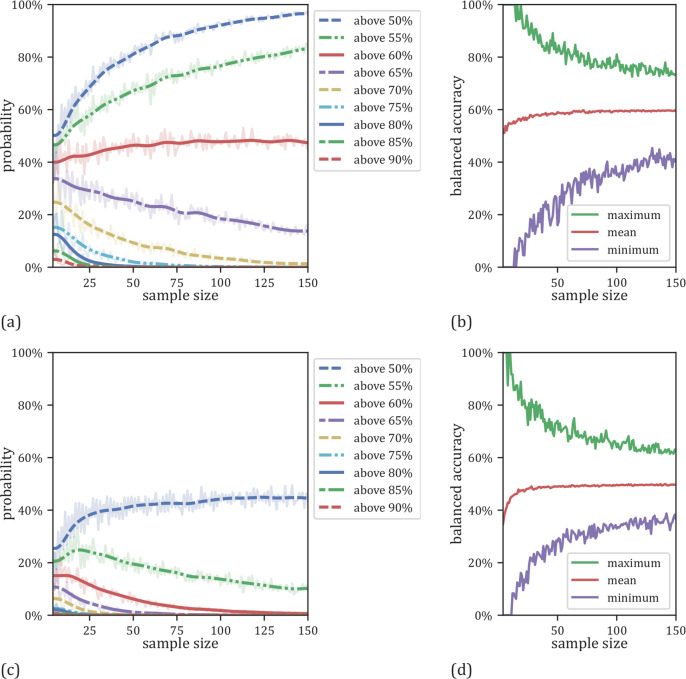
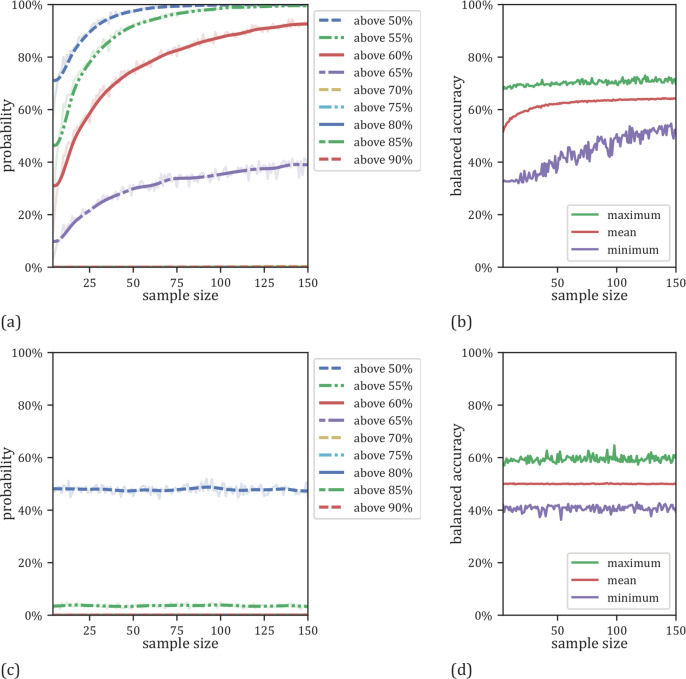
We currently observe a disconcerting phenomenon in machine learning studies in psychiatry: While we would expect larger samples to yield better results due to the availability of more data, larger machine learning studies consistently show much weaker performance than the numerous small-scale studies. Here, we systematically investigated this effect focusing on one of the most heavily studied questions in the field, namely the classification of patients suffering from Major Depressive Disorder (MDD) and healthy controls based on neuroimaging data. Drawing upon structural MRI data from a balanced sample of N = 1868 MDD patients and healthy controls from our recent international Predictive Analytics Competition (PAC), we first trained and tested a classification model on the full dataset which yielded an accuracy of 61%. Next, we mimicked the process by which researchers would draw samples of various sizes (N = 4 to N = 150) from the population and showed a strong risk of misestimation. Specifically, for small sample sizes (N = 20), we observe accuracies of up to 95%. For medium sample sizes (N = 100) accuracies up to 75% were found. Importantly, further investigation showed that sufficiently large test sets effectively protect against performance misestimation whereas larger datasets per se do not. While these results question the validity of a substantial part of the current literature, we outline the relatively low-cost remedy of larger test sets, which is readily available in most cases.
尽管我们期望更大的样本由于数据的可用性而产生更好的结果,但更大的机器学习研究始终显示出比众多小规模研究弱得多的性能。在这里,我们集中研究了这个问题,重点是该领域研究最多的问题之一,即基于神经影像学数据对患有重度抑郁症(MDD)和健康对照的患者进行分类。利用我们最近的国际预测分析竞赛(PAC)中来自 N = 1868 名 MDD 患者和健康对照的平衡样本的结构 MRI 数据,我们首先在全数据集上训练和测试了分类模型,该模型的准确率为 61%。接下来,我们模拟了研究人员从人群中抽取各种大小样本(N = 4 到 N = 150)的过程,并显示出严重的估计错误风险。具体来说,对于小样本量(N = 20),我们观察到高达 95%的准确率。对于中等样本量(N = 100),发现准确率高达 75%。重要的是,进一步的调查表明,足够大的测试集可以有效地防止性能估计错误,而大数据集本身并不能。虽然这些结果对当前文献的很大一部分提出了质疑,但我们概述了相对低成本的补救措施,即更大的测试集,这在大多数情况下都可以轻松获得。