Mostavi Milad, Chiu Yu-Chiao, Chen Yidong, Huang Yufei
Greehey Children's Cancer Research Institute, University of Texas Health San Antonio, San Antonio, TX, 78229, USA.
Department of Electrical and Computer Engineering, University of Texas at San Antonio, San Antonio, TX, 78249, USA.
BMC Bioinformatics. 2021 May 12;22(1):244. doi: 10.1186/s12859-021-04157-w.
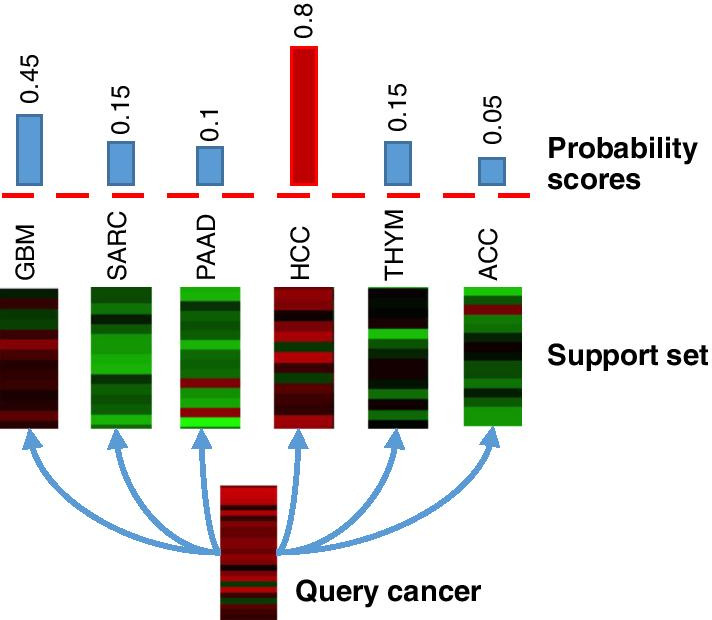
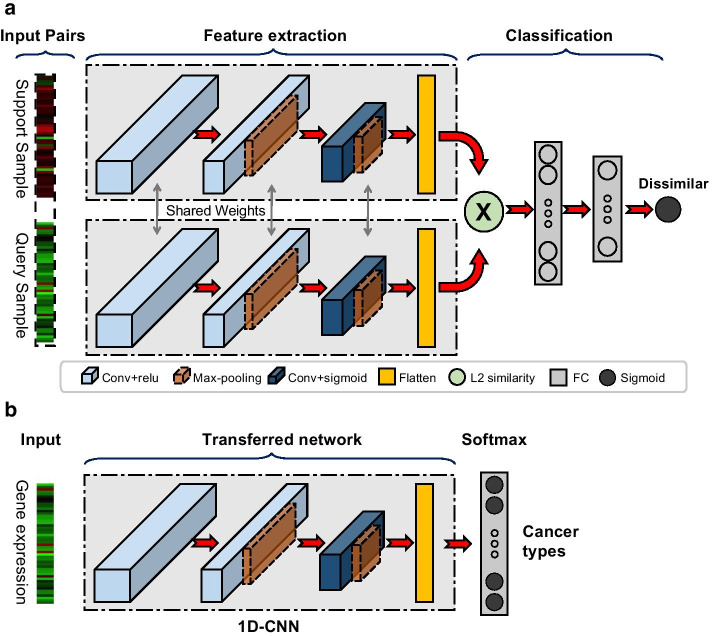
The state-of-the-art deep learning based cancer type prediction can only predict cancer types whose samples are available during the training where the sample size is commonly large. In this paper, we consider how to utilize the existing training samples to predict cancer types unseen during the training. We hypothesize the existence of a set of type-agnostic expression representations that define the similarity/dissimilarity between samples of the same/different types and propose a novel one-shot learning model called CancerSiamese to learn this common representation. CancerSiamese accepts a pair of query and support samples (gene expression profiles) and learns the representation of similar or dissimilar cancer types through two parallel convolutional neural networks joined by a similarity function.
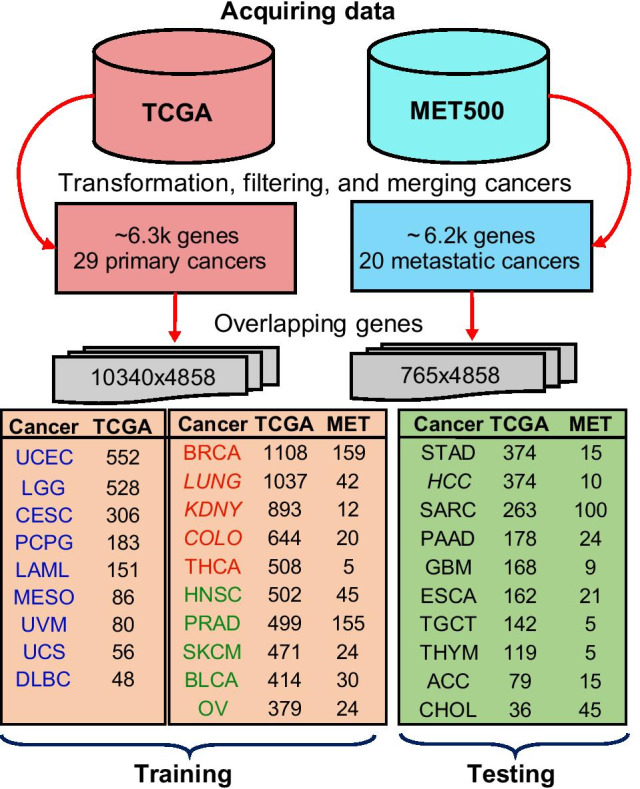
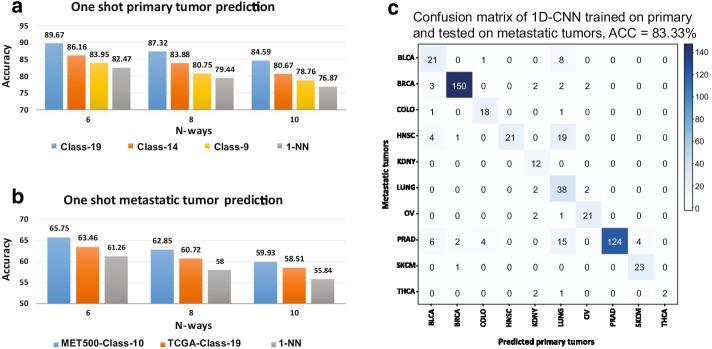
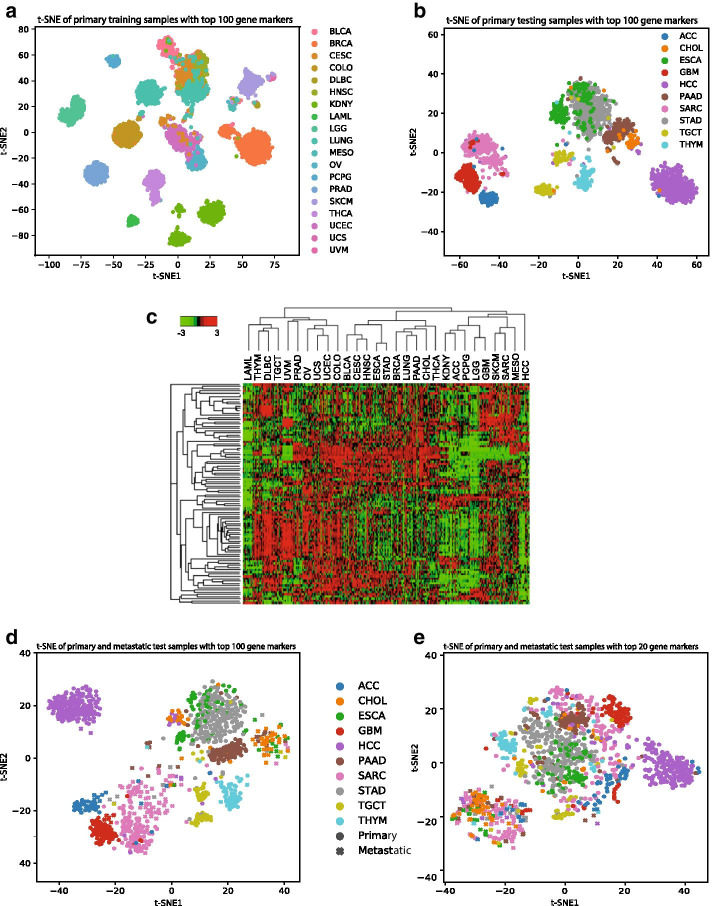
We trained CancerSiamese for cancer type prediction for primary and metastatic tumors using samples from the Cancer Genome Atlas (TCGA) and MET500. Network transfer learning was utilized to facilitate the training of the CancerSiamese models. CancerSiamese was tested for different N-way predictions and yielded an average accuracy improvement of 8% and 4% over the benchmark 1-Nearest Neighbor (1-NN) classifier for primary and metastatic tumors, respectively. Moreover, we applied the guided gradient saliency map and feature selection to CancerSiamese to examine 100 and 200 top marker-gene candidates for the prediction of primary and metastatic cancers, respectively. Functional analysis of these marker genes revealed several cancer related functions between primary and metastatic tumors.
This work demonstrated, for the first time, the feasibility of predicting unseen cancer types whose samples are limited. Thus, it could inspire new and ingenious applications of one-shot and few-shot learning solutions for improving cancer diagnosis, prognostic, and our understanding of cancer.
基于深度学习的最先进癌症类型预测只能预测在训练期间有可用样本的癌症类型,且样本量通常很大。在本文中,我们考虑如何利用现有的训练样本预测训练期间未见过的癌症类型。我们假设存在一组与类型无关的表达表示,这些表示定义了相同/不同类型样本之间的相似性/不相似性,并提出了一种名为CancerSiamese的新型一次性学习模型来学习这种通用表示。CancerSiamese接受一对查询样本和支持样本(基因表达谱),并通过由相似性函数连接的两个并行卷积神经网络学习相似或不相似癌症类型的表示。
我们使用来自癌症基因组图谱(TCGA)和MET500的样本训练CancerSiamese用于原发性和转移性肿瘤的癌症类型预测。利用网络迁移学习来促进CancerSiamese模型的训练。对CancerSiamese进行了不同N路预测的测试,与基准1最近邻(1-NN)分类器相比,原发性和转移性肿瘤的平均准确率分别提高了8%和4%。此外,我们将引导梯度显著性图和特征选择应用于CancerSiamese,分别检查了100个和200个用于预测原发性和转移性癌症的顶级标记基因候选者。对这些标记基因的功能分析揭示了原发性和转移性肿瘤之间的几种癌症相关功能。
这项工作首次证明了预测样本有限的未见过的癌症类型的可行性。因此,它可以激发一次性和少样本学习解决方案在改善癌症诊断、预后以及我们对癌症的理解方面的新颖和巧妙应用。