Department of Pathology and Laboratory Medicine, Weill Cornell Medicine, 1300 York Avenue, New York, NY 10065, USA.
Department of Biostatistics, Johns Hopkins University, 615 N Wolfe St, Baltimore, MD 21205, USA.
Database (Oxford). 2021 May 15;2021. doi: 10.1093/database/baab027.
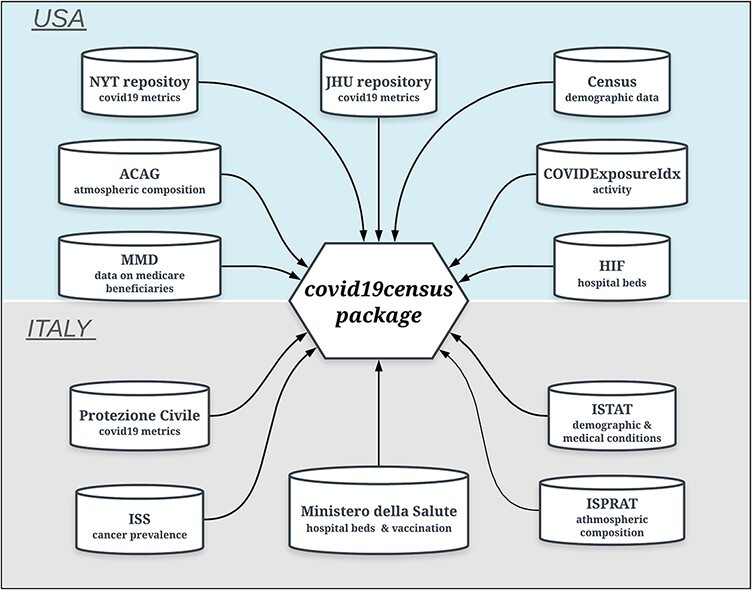
Since the beginning of the coronavirus disease-2019 (COVID-19) pandemic in 2020, there has been a tremendous accumulation of data capturing different statistics including the number of tests, confirmed cases and deaths. This data wealth offers a great opportunity for researchers to model the effect of certain variables on COVID-19 morbidity and mortality and to get a better understanding of the disease at the epidemiological level. However, in order to draw any reliable and unbiased estimate, models also need to take into account other variables and metrics available from a plurality of official and unofficial heterogenous resources. In this study, we introduce covid19census, an R package that extracts from many different repositories and combines together COVID-19 metrics and other demographic, environment- and health-related variables of the USA and Italy at the county and regional levels, respectively. The package is equipped with a number of user-friendly functions that dynamically extract the data over different timepoints and contains a detailed description of the included variables. To demonstrate the utility of this tool, we used it to extract and combine different county-level data from the USA, which we subsequently used to model the effect of diabetes on COVID-19 mortality at the county level, taking into account other variables that may influence such effects. In conclusion, it was observed that the 'covid19census' package allows to easily extract area-level data from both the USA and Italy using few functions. These comprehensive data can be used to provide reliable estimates of the effect of certain variables on COVID-19 outcomes. Database URL: https://github.com/c1au6i0/covid19census.
自 2020 年冠状病毒病-2019(COVID-19)大流行开始以来,已经积累了大量数据,包括测试数量、确诊病例和死亡人数等不同统计数据。这些数据为研究人员提供了一个很好的机会,可以对某些变量对 COVID-19 发病率和死亡率的影响进行建模,并在流行病学层面更好地了解该疾病。然而,为了得出任何可靠和无偏的估计,模型还需要考虑来自多个官方和非官方异质资源的其他变量和指标。在这项研究中,我们引入了 covid19census,这是一个 R 包,它从许多不同的存储库中提取并分别将美国和意大利的 COVID-19 指标以及其他人口统计学、环境和健康相关变量组合在一起。该包配备了许多用户友好的功能,可以在不同时间点动态提取数据,并包含对包含变量的详细描述。为了演示该工具的实用性,我们使用它从美国提取和组合了不同县级的数据,随后我们使用这些数据来建模糖尿病对县级 COVID-19 死亡率的影响,同时考虑了可能影响这些影响的其他变量。总之,观察到 'covid19census' 包允许使用几个函数轻松从美国和意大利提取区域级数据。这些综合数据可用于提供某些变量对 COVID-19 结果的影响的可靠估计。数据库 URL:https://github.com/c1au6i0/covid19census。