Antontsev Victor, Jagarapu Aditya, Bundey Yogesh, Hou Hypatia, Khotimchenko Maksim, Walsh Jason, Varshney Jyotika
VeriSIM Life, 1 Sansome Street, Suite 3500, San Francisco, CA, 94104, USA.
Sci Rep. 2021 May 27;11(1):11143. doi: 10.1038/s41598-021-90637-1.
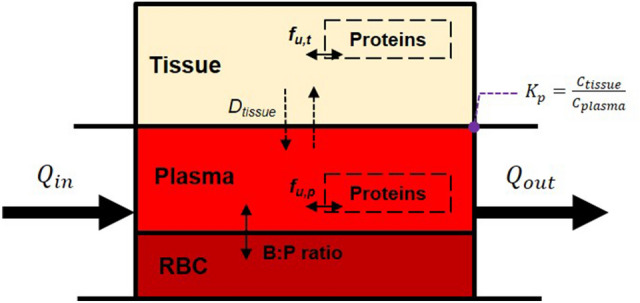
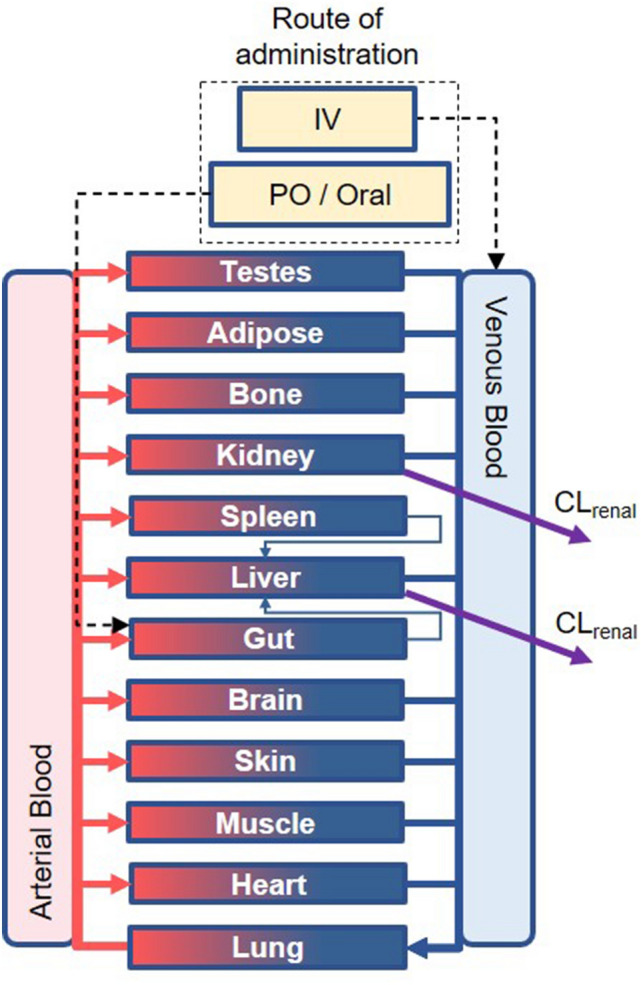
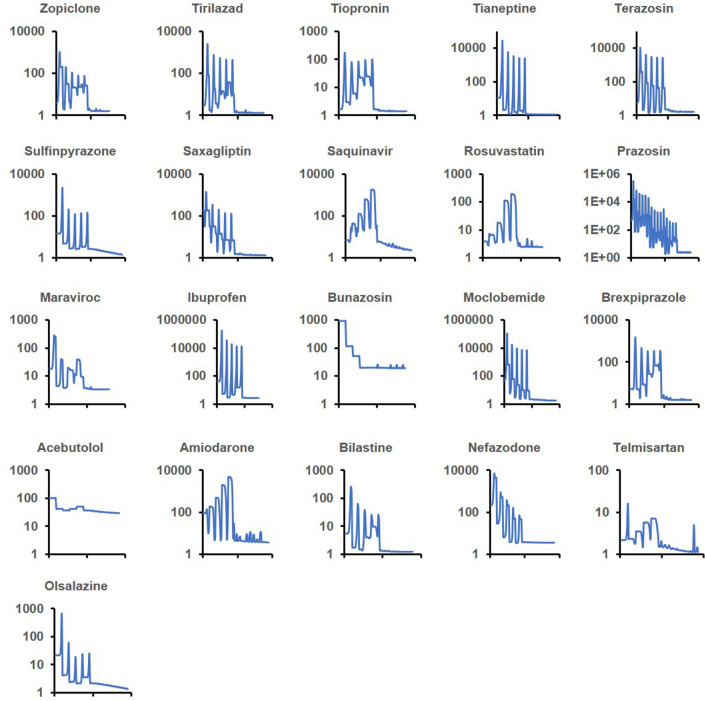
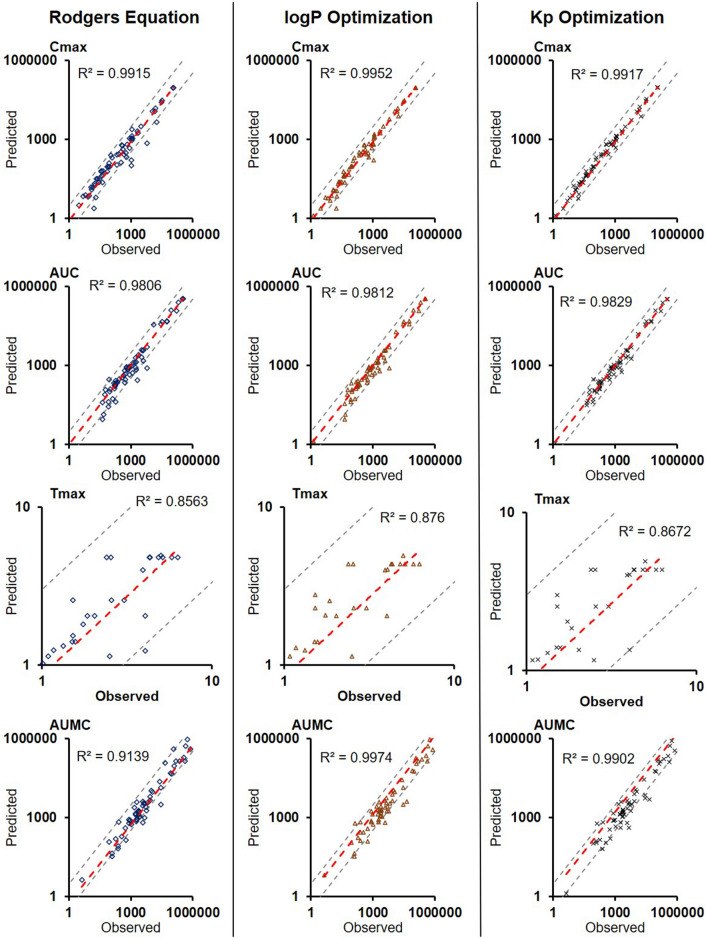
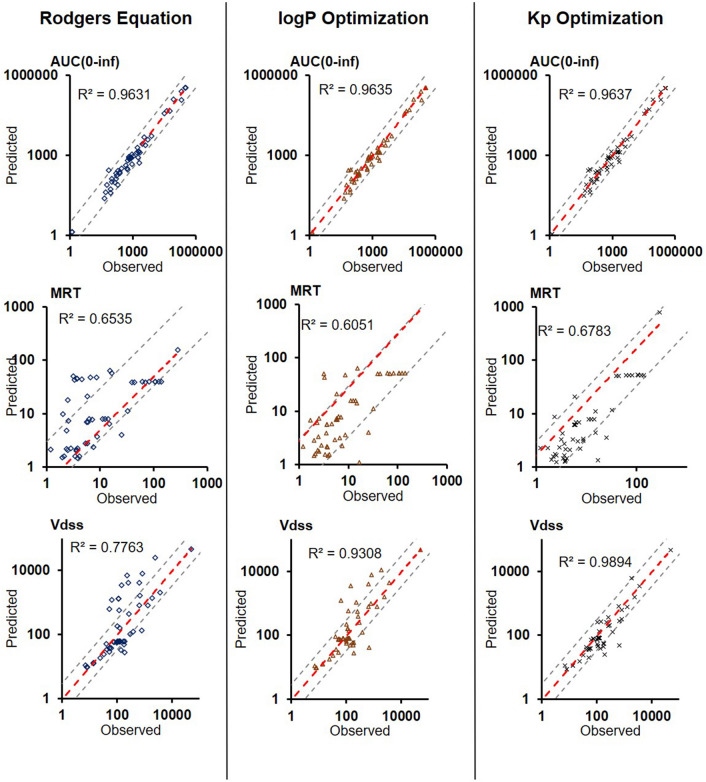
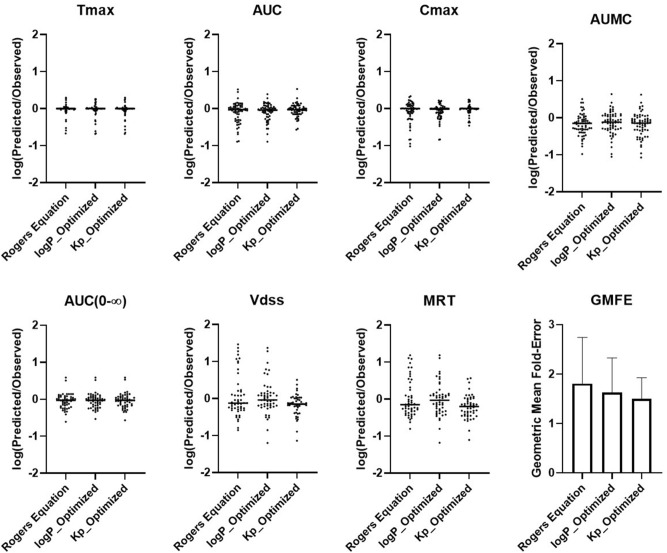
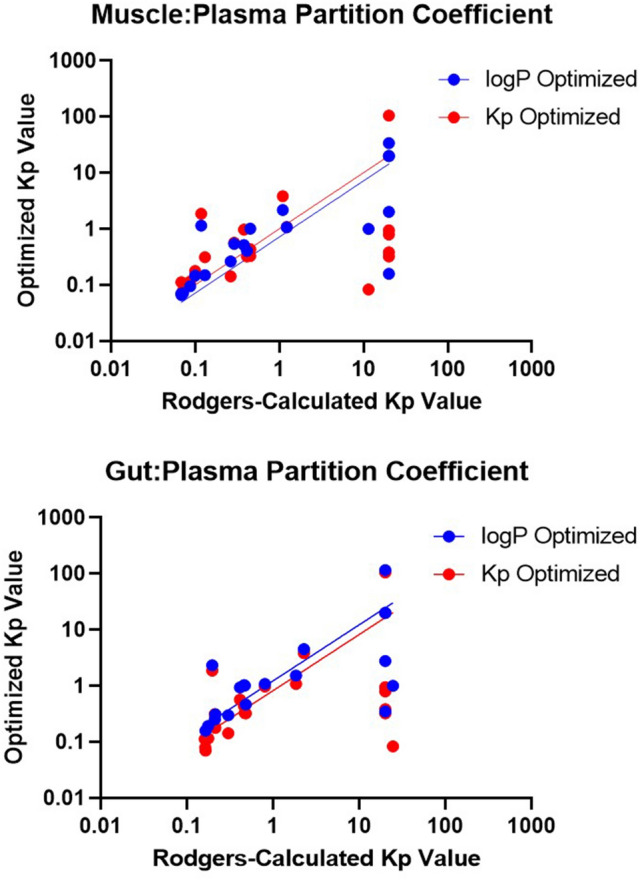
Prediction of the first-in-human dosing regimens is a critical step in drug development and requires accurate quantitation of drug distribution. Traditional in vivo studies used to characterize clinical candidate's volume of distribution are error-prone, time- and cost-intensive and lack reproducibility in clinical settings. The paper demonstrates how a computational platform integrating machine learning optimization with mechanistic modeling can be used to simulate compound plasma concentration profile and predict tissue-plasma partition coefficients with high accuracy by varying the lipophilicity descriptor logP. The approach applied to chemically diverse small molecules resulted in comparable geometric mean fold-errors of 1.50 and 1.63 in pharmacokinetic outputs for direct tissue:plasma partition and hybrid logP optimization, with the latter enabling prediction of tissue permeation that can be used to guide toxicity and efficacy dosing in human subjects. The optimization simulations required to achieve these results were parallelized on the AWS cloud and generated outputs in under 5 h. Accuracy, speed, and scalability of the framework indicate that it can be used to assess the relevance of other mechanistic relationships implicated in pharmacokinetic-pharmacodynamic phenomena with a lower risk of overfitting datasets and generate large database of physiologically-relevant drug disposition for further integration with machine learning models.
预测人体首次给药方案是药物研发中的关键一步,需要准确测定药物分布情况。过去用于表征临床候选药物分布容积的传统体内研究容易出错,耗时且成本高昂,在临床环境中缺乏可重复性。本文展示了一个将机器学习优化与机理建模相结合的计算平台,如何通过改变亲脂性描述符logP来高精度模拟化合物血浆浓度曲线并预测组织-血浆分配系数。将该方法应用于化学结构多样的小分子,在直接组织:血浆分配和混合logP优化的药代动力学输出中,几何平均倍数误差分别为1.50和1.63,后者能够预测组织渗透性,可用于指导人体受试者的毒性和疗效给药。实现这些结果所需的优化模拟在AWS云上并行运行,并在5小时内生成输出。该框架的准确性、速度和可扩展性表明,它可用于评估药代动力学-药效学现象中涉及的其他机理关系的相关性,过度拟合数据集的风险较低,并生成大量生理相关药物处置的数据库,以便进一步与机器学习模型集成。