Amato Federica, Borzì Luigi, Olmo Gabriella, Orozco-Arroyave Juan Rafael
Department of Control and Computing Engineering, Politecnico di Torino, Corso Duca degli Abruzzi 24, Turin, Italy.
GITA Lab, Faculty of Engineering, University of Antioquia, Medellín, Colombia.
Health Inf Sci Syst. 2021 Jul 30;9(1):32. doi: 10.1007/s13755-021-00162-8. eCollection 2021 Dec.
Automatic assessment of speech impairment is a cutting edge topic in Parkinson's disease (PD). Language disorders are known to occur several years earlier than typical motor symptoms, thus speech analysis may contribute to the early diagnosis of the disease. Moreover, the remote monitoring of dysphonia could allow achieving an effective follow-up of PD clinical condition, possibly performed in the home environment.
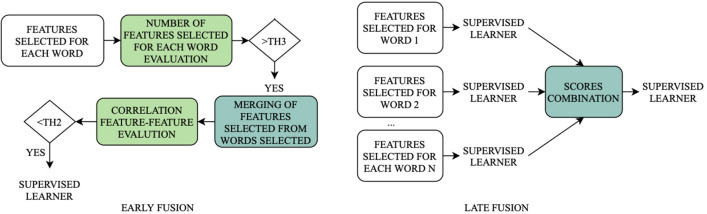
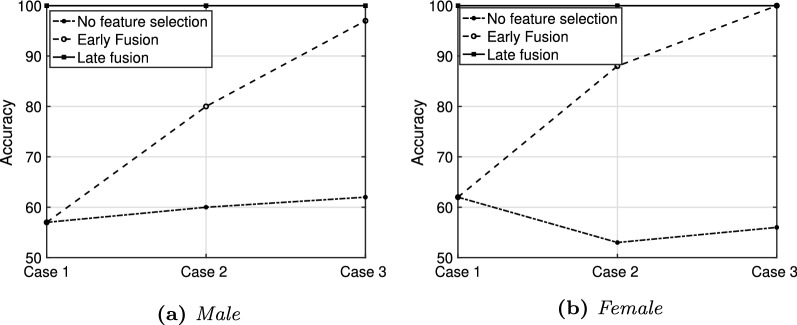
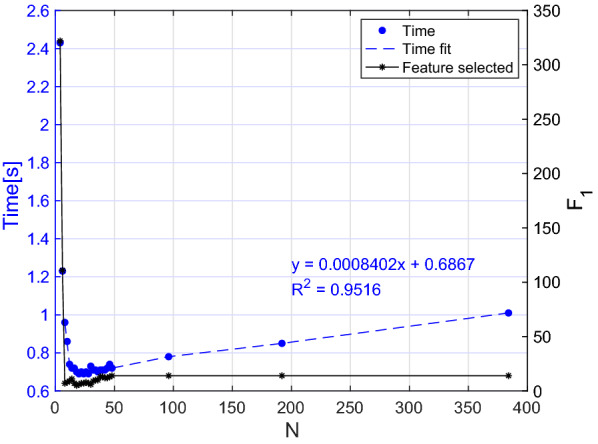
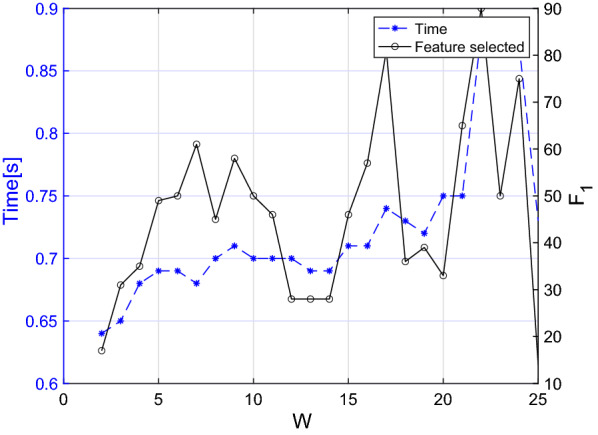
In this work, we performed a multi-level analysis, progressively combining features extracted from the entire signal, the voiced segments, and the on-set/off-set regions, leading to a total number of 126 features. Furthermore, we compared the performance of early and late feature fusion schemes, aiming to identify the best model configuration and taking advantage of having 25 isolated words pronounced by each subject. We employed data from the PC-GITA database (50 healthy controls and 50 PD patients) for validation and testing.
We implemented an optimized k-Nearest Neighbours model for the binary classification of PD patients versus healthy controls. We achieved an accuracy of 99.4% in 10-fold cross-validation and 94.3% in testing on the PC-GITA database (average value of male and female subjects).
The promising performance yielded by our model confirms the feasibility of automatic assessment of PD using voice recordings. Moreover, a post-hoc analysis of the most relevant features discloses the option of voice processing using a simple smartphone application.
语音障碍的自动评估是帕金森病(PD)领域的一个前沿话题。已知语言障碍比典型运动症状早数年出现,因此语音分析可能有助于该疾病的早期诊断。此外,对发音障碍的远程监测可以实现对PD临床状况的有效随访,这可能在家庭环境中进行。
在这项工作中,我们进行了多层次分析,逐步结合从整个信号、浊音段和起始/结束区域提取的特征,总共得到126个特征。此外,我们比较了早期和晚期特征融合方案的性能,旨在确定最佳模型配置,并利用每个受试者说出的25个孤立单词。我们使用来自PC - GITA数据库(50名健康对照者和50名PD患者)的数据进行验证和测试。
我们为PD患者与健康对照者的二元分类实现了一个优化的k近邻模型。在10折交叉验证中,我们的准确率达到了99.4%,在PC - GITA数据库上进行测试时(男性和女性受试者的平均值)准确率为94.3%。
我们的模型所取得的令人鼓舞的性能证实了使用语音记录自动评估PD的可行性。此外,对最相关特征的事后分析揭示了使用简单智能手机应用程序进行语音处理的可能性。