Bissanum Rassanee, Chaichulee Sitthichok, Kamolphiwong Rawikant, Navakanitworakul Raphatphorn, Kanokwiroon Kanyanatt
Department of Biomedical Sciences and Biomedical Engineering, Faculty of Medicine, Prince of Songkla University, Hat Yai, Songkhla 90110, Thailand.
J Pers Med. 2021 Sep 1;11(9):881. doi: 10.3390/jpm11090881.
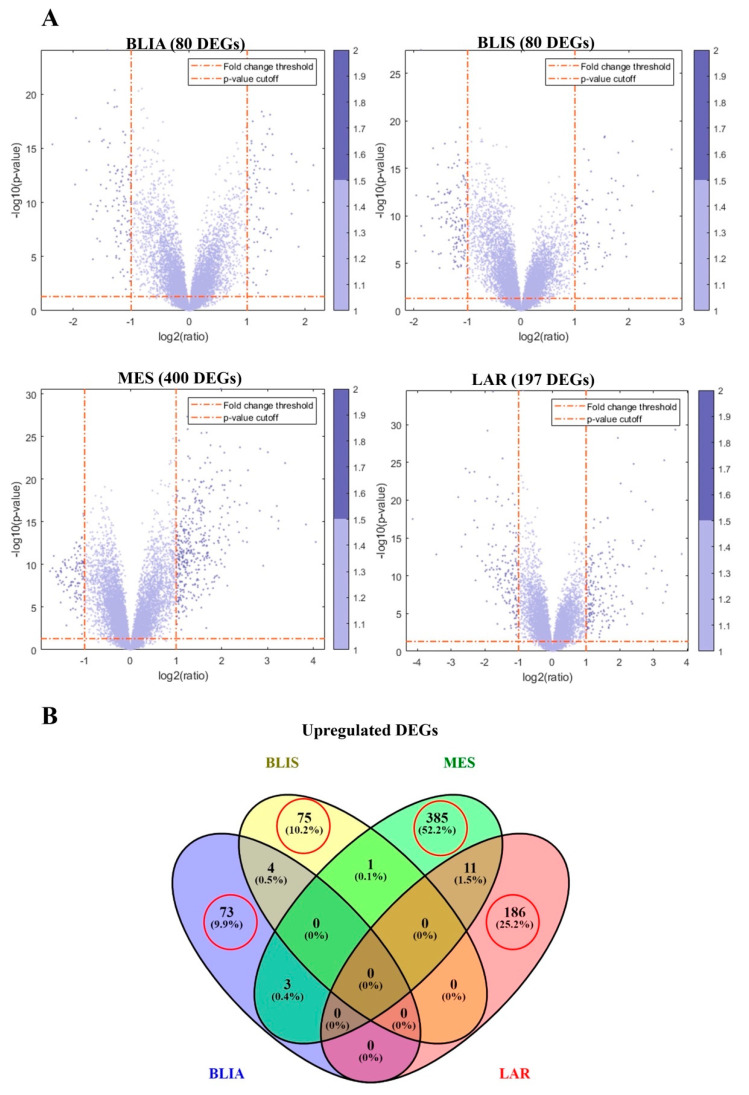
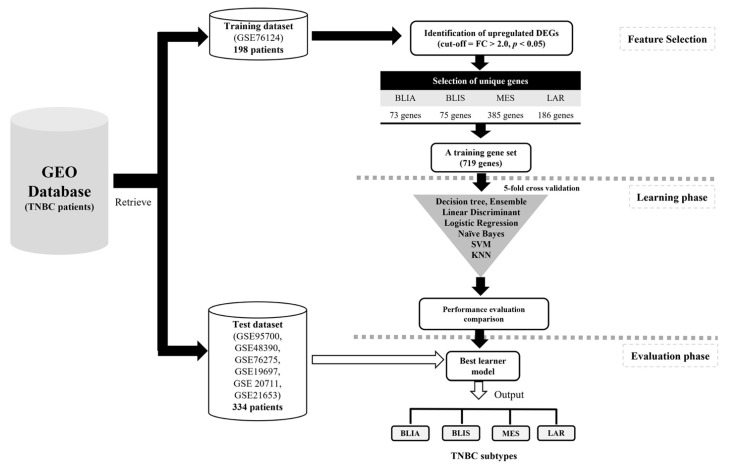
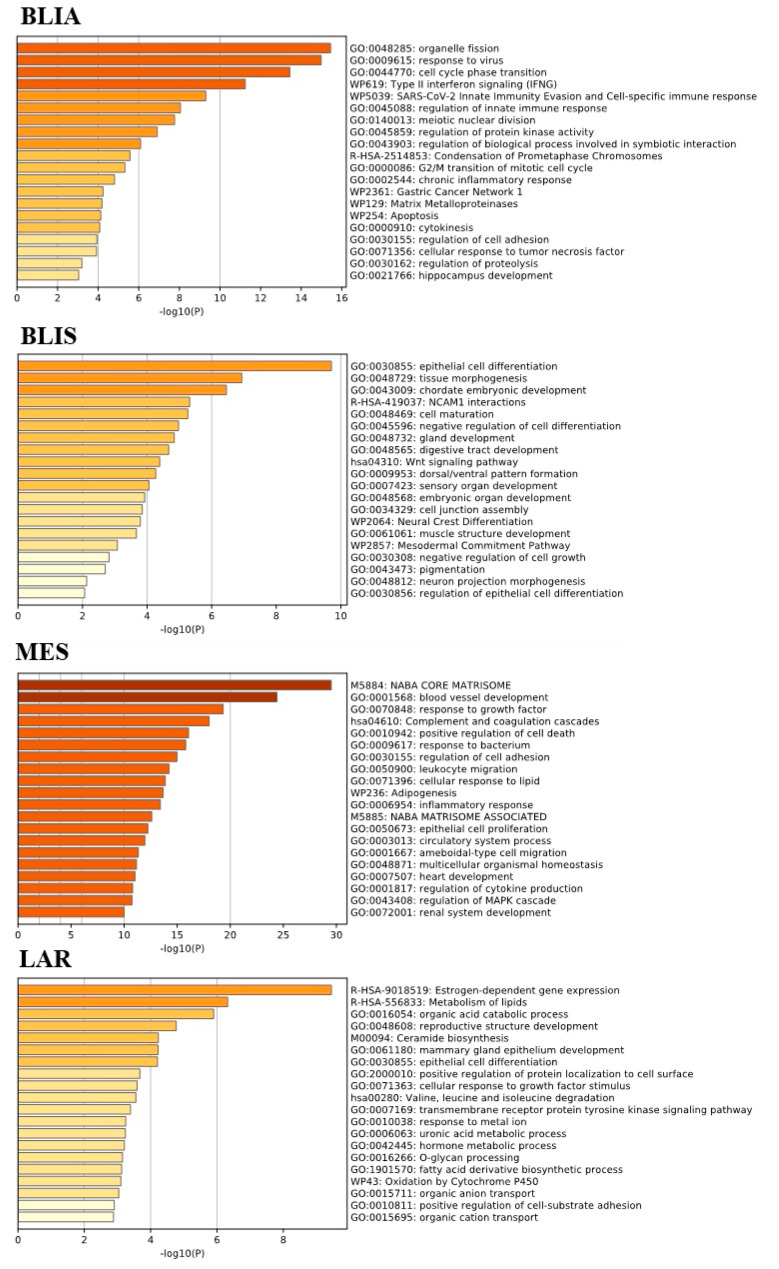
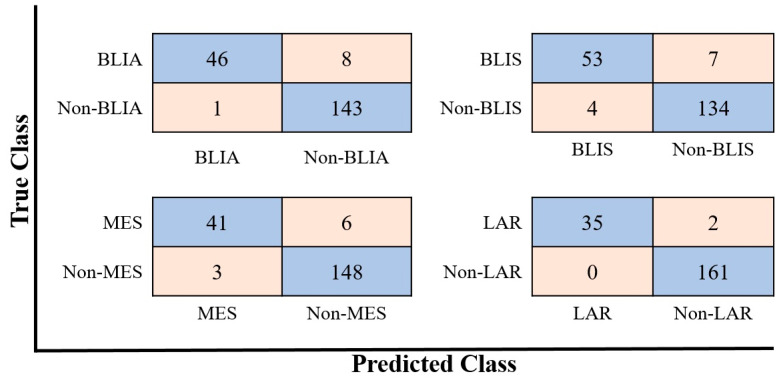
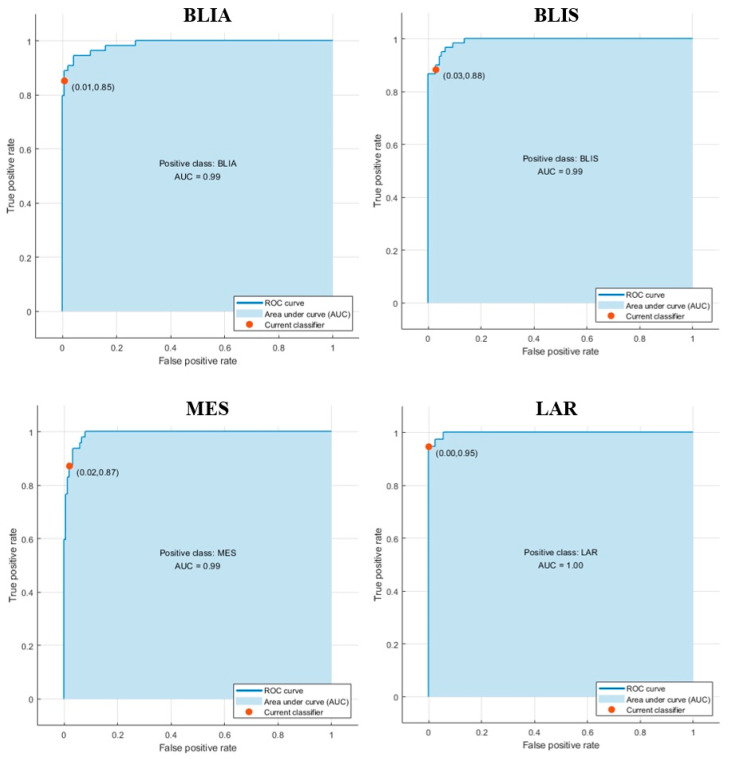
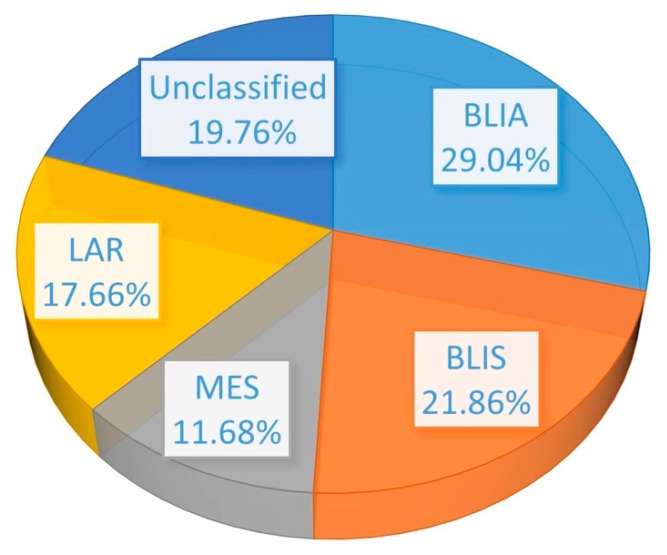
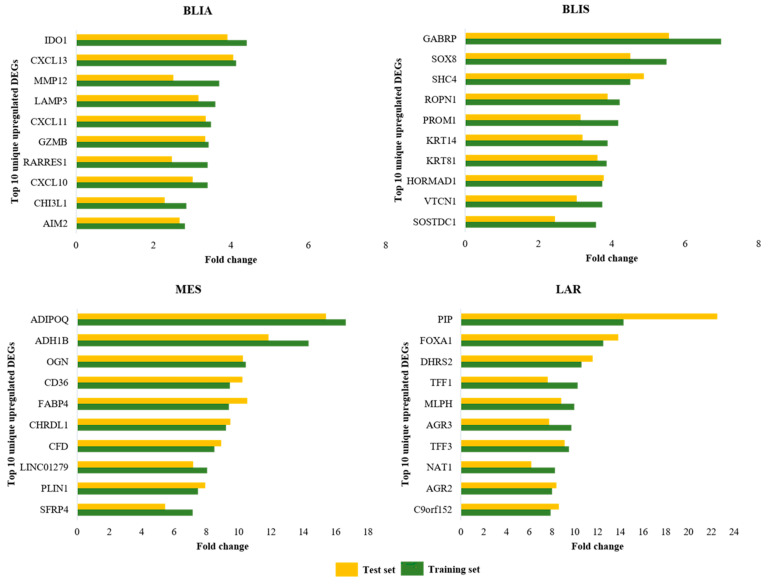
Triple negative breast cancer (TNBC) lacks well-defined molecular targets and is highly heterogenous, making treatment challenging. Using gene expression analysis, TNBC has been classified into four different subtypes: basal-like immune-activated (BLIA), basal-like immune-suppressed (BLIS), mesenchymal (MES), and luminal androgen receptor (LAR). However, there is currently no standardized method for classifying TNBC subtypes. We attempted to define a gene signature for each subtype, and to develop a classification method based on machine learning (ML) for TNBC subtyping. In these experiments, gene expression microarray data for TNBC patients were downloaded from the Gene Expression Omnibus database. Differentially expressed genes unique to 198 known TNBC cases were identified and selected as a training gene set to train in seven different classification models. We produced a training set consisting of 719 DEGs selected from uniquely expressed genes of all four subtypes. The highest average accuracy of classification of the BLIA, BLIS, MES, and LAR subtypes was achieved by the SVM algorithm (accuracy 95-98.8%; AUC 0.99-1.00). For model validation, we used 334 samples of unknown TNBC subtypes, of which 97 (29.04%), 73 (21.86%), 39 (11.68%) and 59 (17.66%) were predicted to be BLIA, BLIS, MES, and LAR, respectively. However, 66 TNBC samples (19.76%) could not be assigned to any subtype. These samples contained only three upregulated genes (, , and ). Each TNBC subtype had a unique gene expression pattern, which was confirmed by identification of DEGs and pathway analysis. These results indicated that our training gene set was suitable for development of classification models, and that the SVM algorithm could classify TNBC into four unique subtypes. Accurate and consistent classification of the TNBC subtypes is essential for personalized treatment and prognosis of TNBC.
三阴性乳腺癌(TNBC)缺乏明确的分子靶点且高度异质性,这使得治疗颇具挑战性。通过基因表达分析,TNBC已被分为四种不同亚型:基底样免疫激活型(BLIA)、基底样免疫抑制型(BLIS)、间充质型(MES)和腔面雄激素受体型(LAR)。然而,目前尚无用于TNBC亚型分类的标准化方法。我们试图为每种亚型定义一个基因特征,并开发一种基于机器学习(ML)的TNBC亚型分类方法。在这些实验中,从基因表达综合数据库下载了TNBC患者的基因表达微阵列数据。鉴定并选择了198例已知TNBC病例特有的差异表达基因作为训练基因集,用于训练七种不同的分类模型。我们生成了一个由从所有四种亚型的独特表达基因中选择的719个差异表达基因组成的训练集。支持向量机(SVM)算法实现了BLIA、BLIS、MES和LAR亚型分类的最高平均准确率(准确率95 - 98.8%;曲线下面积0.99 - 1.00)。为了进行模型验证,我们使用了334个未知TNBC亚型的样本,其中分别有97个(29.04%)、73个(21.86%)、39个(11.68%)和59个(17.66%)被预测为BLIA、BLIS、MES和LAR。然而,66个TNBC样本(19.76%)无法被归类到任何亚型。这些样本仅包含三个上调基因( 、 和 )。每种TNBC亚型都有独特的基因表达模式,这通过差异表达基因的鉴定和通路分析得到了证实。这些结果表明我们的训练基因集适用于分类模型的开发,并且SVM算法可以将TNBC分为四种独特的亚型。TNBC亚型的准确且一致的分类对于TNBC的个性化治疗和预后至关重要。