Cohn Neil, Schilperoord Joost
Department of Communication and Cognition, Tilburg School of Humanities and Digital Sciences, Tilburg University, Tilburg, Netherlands.
Front Artif Intell. 2022 Jan 4;4:778060. doi: 10.3389/frai.2021.778060. eCollection 2021.
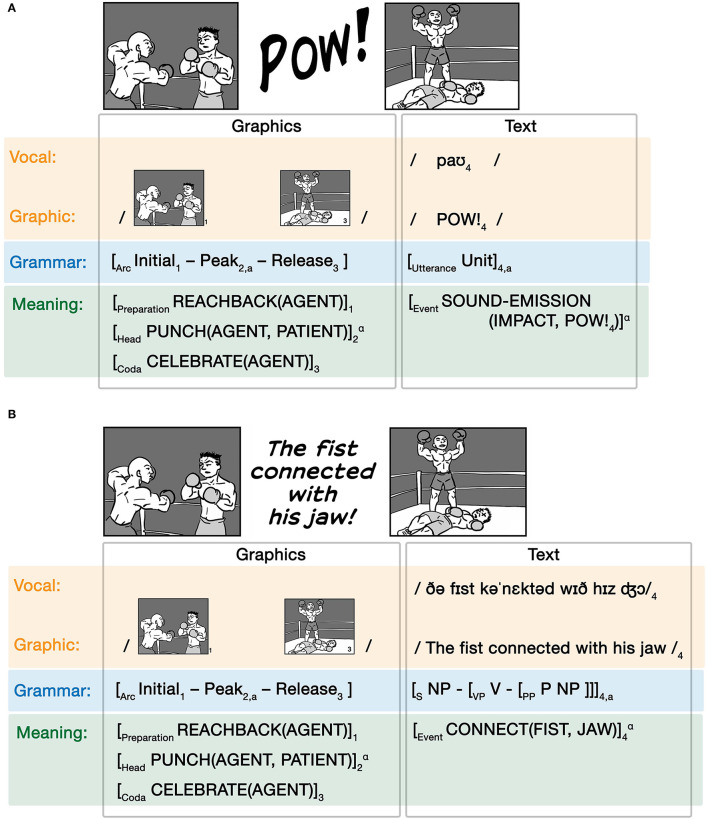
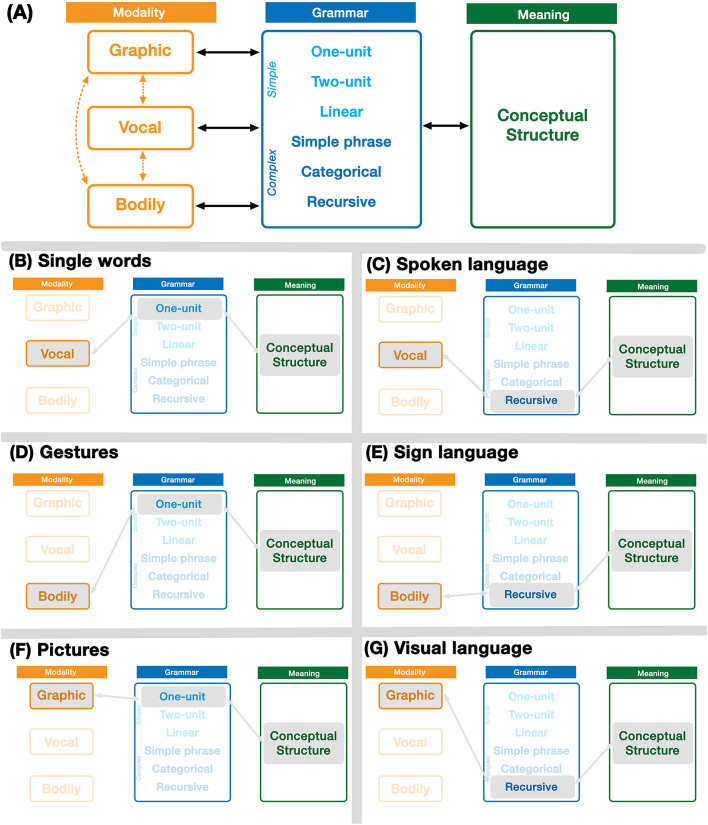
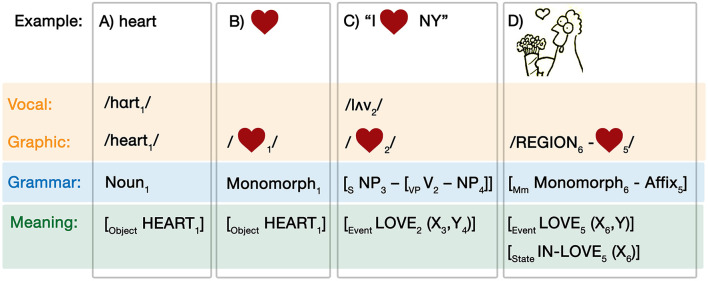
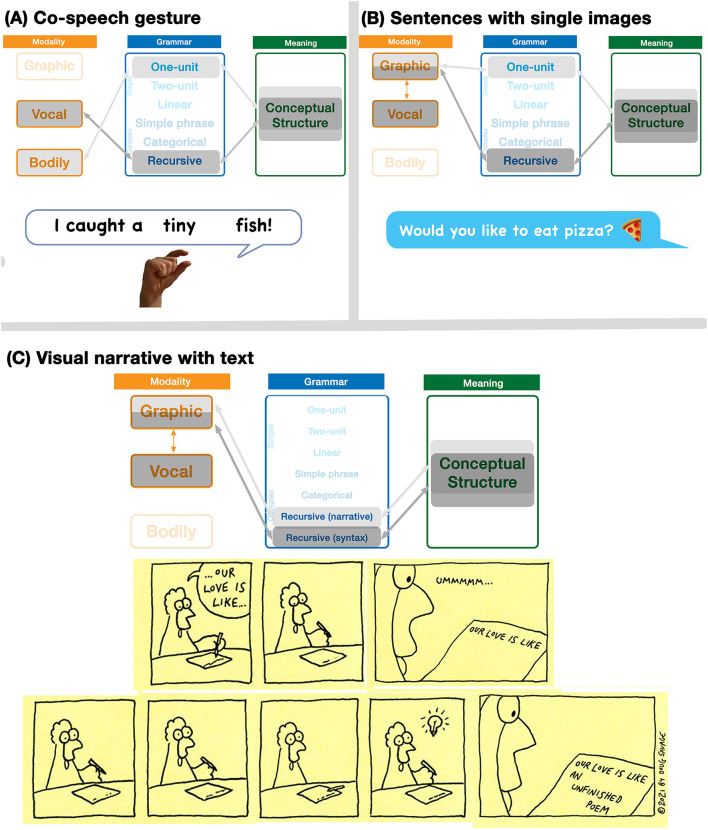
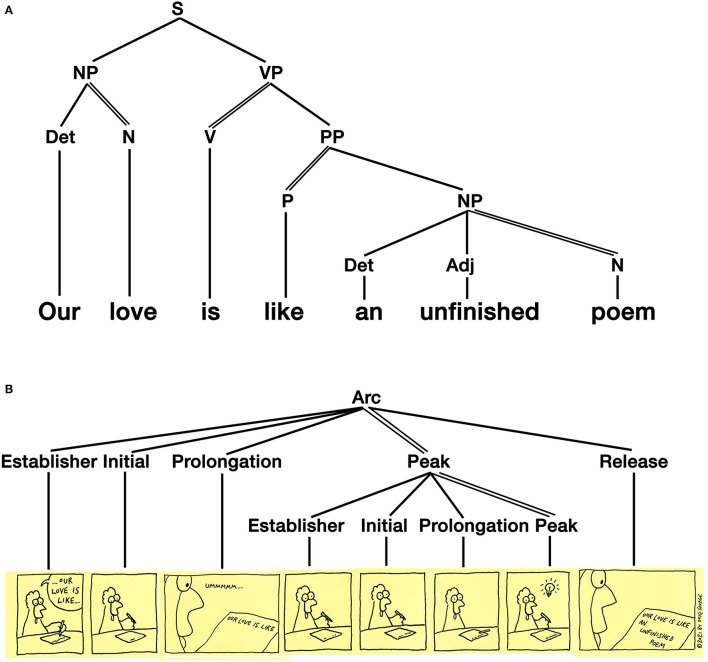
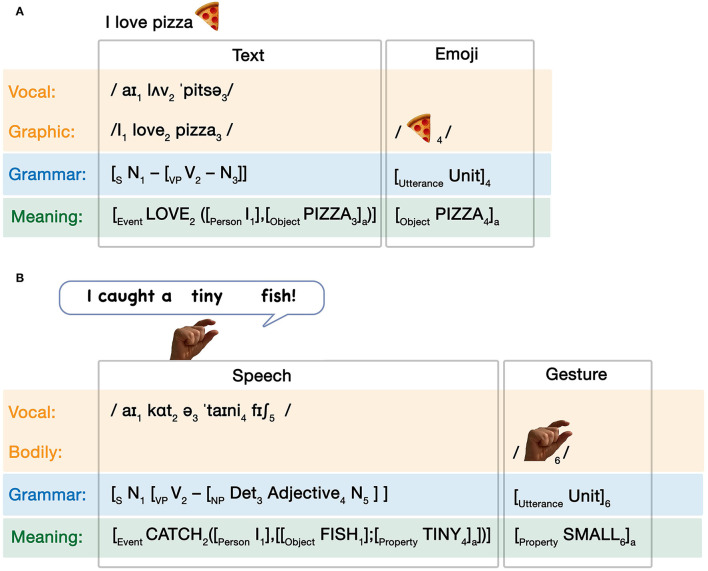
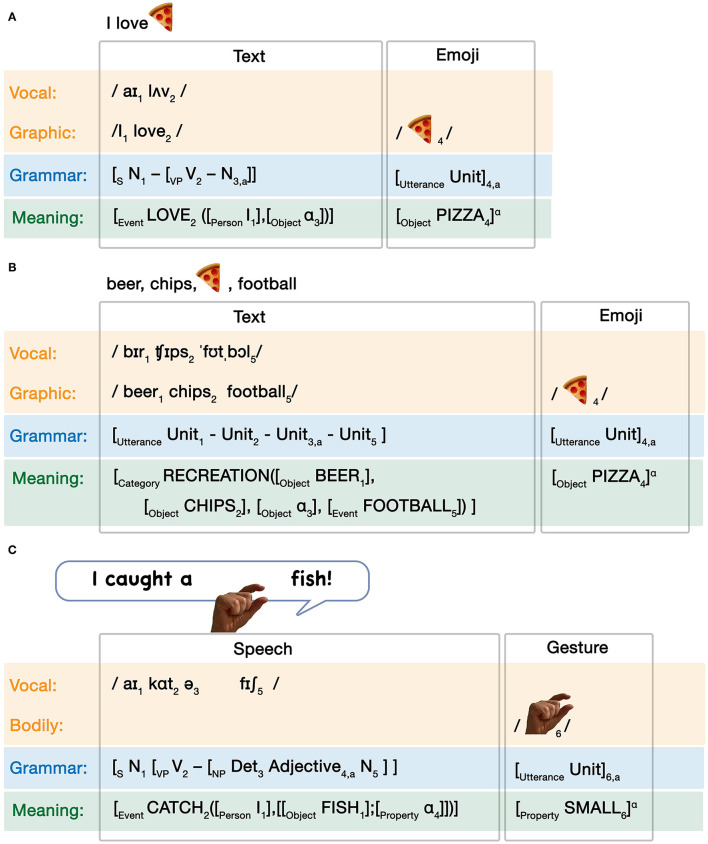
Language is typically embedded in multimodal communication, yet models of linguistic competence do not often incorporate this complexity. Meanwhile, speech, gesture, and/or pictures are each considered as indivisible components of multimodal messages. Here, we argue that multimodality should not be characterized by whole interacting behaviors, but by interactions of similar substructures which permeate across expressive behaviors. These structures comprise a unified architecture and align within Jackendoff's Parallel Architecture: a modality, meaning, and grammar. Because this tripartite architecture persists across modalities, interactions can manifest within each of these substructures. Interactions between modalities alone create correspondences in time (ex. speech with gesture) or space (ex. writing with pictures) of the sensory signals, while multimodal meaning-making balances how modalities carry "semantic weight" for the gist of the whole expression. Here we focus primarily on interactions between grammars, which contrast across two variables: symmetry, related to the complexity of the grammars, and allocation, related to the relative independence of interacting grammars. While independent allocations keep grammars separate, substitutive allocation inserts expressions from one grammar into those of another. We show that substitution operates in interactions between all three natural modalities (vocal, bodily, graphic), and also in unimodal contexts within and between languages, as in codeswitching. Altogether, we argue that unimodal and multimodal expressions arise as emergent interactive states from a unified cognitive architecture, heralding a reconsideration of the "language faculty" itself.
语言通常嵌入在多模态交流中,然而语言能力模型往往没有纳入这种复杂性。与此同时,言语、手势和/或图片都被视为多模态信息中不可分割的组成部分。在此,我们认为多模态不应以整体的交互行为来表征,而应以渗透于各种表达行为中的相似子结构的交互来表征。这些结构构成一个统一的架构,并与杰肯多夫的并行架构相一致:一种模态、意义和语法。由于这种三方架构在各模态中都存在,交互可以在这些子结构的每一个中体现出来。模态之间的交互仅在感觉信号的时间(例如言语与手势)或空间(例如书写与图片)上产生对应关系,而多模态意义构建则平衡各模态如何为整个表达的主旨承载“语义权重”。在此我们主要关注语法之间的交互,这种交互在两个变量上形成对比:对称性,与语法的复杂性相关;分配,与交互语法的相对独立性相关。虽然独立分配使语法保持分离,但替代分配会将一个语法中的表达式插入到另一个语法的表达式中。我们表明,替代操作在所有三种自然模态(语音、身体动作、图形)之间的交互中起作用,也在语言内部和语言之间的单模态语境中起作用,如语码转换。总之,我们认为单模态和多模态表达是从一个统一的认知架构中作为涌现的交互状态而产生的,这预示着对“语言官能”本身的重新思考。