Department of Family Medicine, Kyung Hee University Hospital, Seoul, Republic of Korea.
Department of Electrical and Electronic Engineering, Hanyang University, Ansan, Korea.
Sci Rep. 2022 Feb 10;12(1):2250. doi: 10.1038/s41598-022-06333-1.
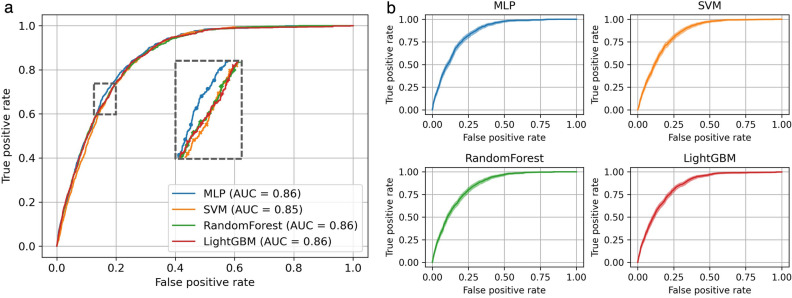
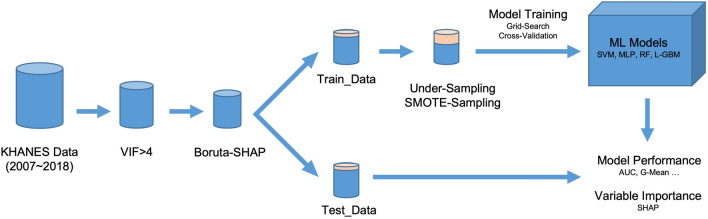
The prevalence of cardiocerebrovascular disease (CVD) is continuously increasing, and it is the leading cause of human death. Since it is difficult for physicians to screen thousands of people, high-accuracy and interpretable methods need to be presented. We developed four machine learning-based CVD classifiers (i.e., multi-layer perceptron, support vector machine, random forest, and light gradient boosting) based on the Korea National Health and Nutrition Examination Survey. We resampled and rebalanced KNHANES data using complex sampling weights such that the rebalanced dataset mimics a uniformly sampled dataset from overall population. For clear risk factor analysis, we removed multicollinearity and CVD-irrelevant variables using VIF-based filtering and the Boruta algorithm. We applied synthetic minority oversampling technique and random undersampling before ML training. We demonstrated that the proposed classifiers achieved excellent performance with AUCs over 0.853. Using Shapley value-based risk factor analysis, we identified that the most significant risk factors of CVD were age, sex, and the prevalence of hypertension. Additionally, we identified that age, hypertension, and BMI were positively correlated with CVD prevalence, while sex (female), alcohol consumption and, monthly income were negative. The results showed that the feature selection and the class balancing technique effectively improve the interpretability of models.
心脑血管疾病(CVD)的患病率不断上升,是人类死亡的主要原因。由于医生难以对数千人进行筛查,因此需要提出高精度且可解释的方法。我们基于韩国国家健康和营养检查调查(KNHANES)开发了四种基于机器学习的 CVD 分类器(即多层感知机、支持向量机、随机森林和轻梯度提升)。我们使用复杂的抽样权重对 KNHANES 数据进行了重采样和再平衡,以使重新平衡的数据集模拟从总体人群中均匀采样的数据集。为了进行明确的风险因素分析,我们使用基于 VIF 的过滤和 Boruta 算法去除了多重共线性和与 CVD 无关的变量。在 ML 训练之前,我们应用了合成少数过采样技术和随机欠采样。我们证明了所提出的分类器具有出色的性能,AUC 超过 0.853。使用基于 Shapley 值的风险因素分析,我们确定 CVD 的最重要风险因素是年龄、性别和高血压的患病率。此外,我们确定年龄、高血压和 BMI 与 CVD 的患病率呈正相关,而性别(女性)、饮酒和月收入呈负相关。结果表明,特征选择和分类平衡技术有效地提高了模型的可解释性。