Department of Biotechnology and Food Science, NTNU- Norwegian University of Science and Technology, Trondheim, Norway.
K.G. Jebsen Center for Genetic Epidemiology, Department of Public Health and General Practice, NTNU- Norwegian University of Science and Technology, Trondheim, Norway.
BMC Bioinformatics. 2022 Feb 19;23(1):79. doi: 10.1186/s12859-022-04605-1.
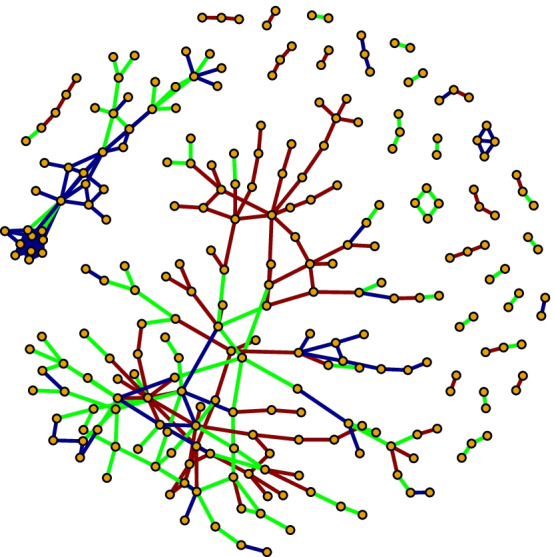
Differential co-expression network analysis has become an important tool to gain understanding of biological phenotypes and diseases. The CSD algorithm is a method to generate differential co-expression networks by comparing gene co-expressions from two different conditions. Each of the gene pairs is assigned conserved (C), specific (S) and differentiated (D) scores based on the co-expression of the gene pair between the two conditions. The result of the procedure is a network where the nodes are genes and the links are the gene pairs with the highest C-, S-, and D-scores. However, the existing CSD-implementations suffer from poor computational performance, difficult user procedures and lack of documentation.
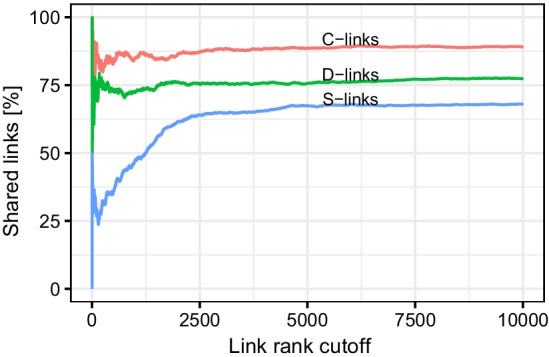
We created the R-package csdR aimed at reaching good performance together with ease of use, sufficient documentation, and with the ability to play well with other tools for data analysis. csdR was benchmarked on a realistic dataset with 20,645 genes. After verifying that the chosen number of iterations gave sufficient robustness, we tested the performance against the two existing CSD implementations. csdR was superior in performance to one of the implementations, whereas the other did not run. Our implementation can utilize multiple processing cores. However, we were unable to achieve more than [Formula: see text]2.7 parallel speedup with saturation reached at about 10 cores.
The results suggest that csdR is a useful tool for differential co-expression analysis and is able to generate robust results within a workday on datasets of realistic sizes when run on a workstation or compute server.
差异共表达网络分析已成为理解生物表型和疾病的重要工具。CSD 算法是一种通过比较两种不同条件下的基因共表达来生成差异共表达网络的方法。根据基因对在两种条件下的共表达情况,每个基因对都被分配了保守(C)、特异(S)和差异(D)分数。该过程的结果是一个网络,其中节点是基因,链接是具有最高 C-、S-和 D-分数的基因对。然而,现有的 CSD 实现存在计算性能差、用户程序复杂和缺乏文档等问题。
我们创建了 R 包 csdR,旨在实现良好的性能、易用性、充足的文档,并能够与其他数据分析工具很好地配合使用。csdR 在一个包含 20645 个基因的真实数据集上进行了基准测试。在验证所选迭代次数具有足够的稳健性之后,我们针对现有的两个 CSD 实现对性能进行了测试。csdR 在性能上优于其中一个实现,而另一个实现则无法运行。我们的实现可以利用多个处理核心。然而,我们无法在工作站或计算服务器上达到超过 [Formula: see text]2.7 的并行加速比,并且在大约 10 个核心时达到饱和。
结果表明,csdR 是差异共表达分析的有用工具,当在工作站或计算服务器上运行时,它能够在一个工作日内生成稳健的结果,并且能够处理真实大小的数据集。