Poonia Ramesh Chandra, Gupta Mukesh Kumar, Abunadi Ibrahim, Albraikan Amani Abdulrahman, Al-Wesabi Fahd N, Hamza Manar Ahmed, B Tulasi
Department of Computer Science, CHRIST (Deemed to be University), Bangalore 560029, India.
Department of Computer Science & Engineering, Swami Keshvanand Institute of Technology, Management & Gramothan (SKIT), Jaipur 302017, India.
Healthcare (Basel). 2022 Feb 14;10(2):371. doi: 10.3390/healthcare10020371.
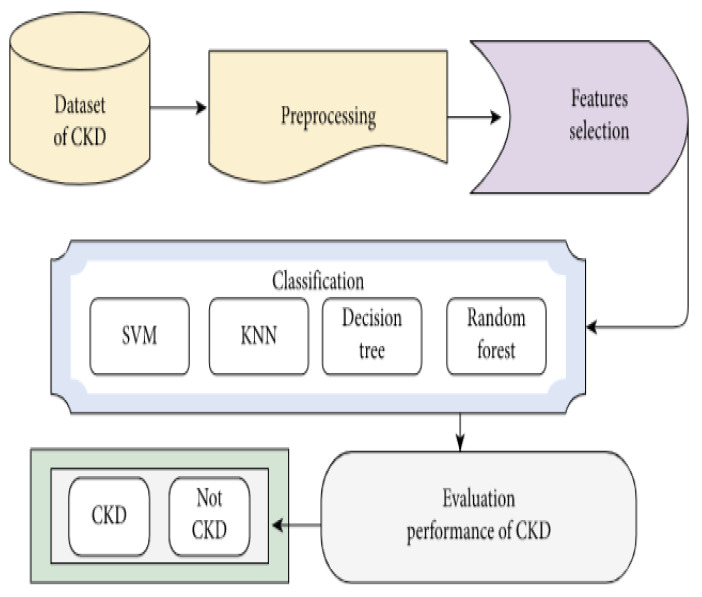
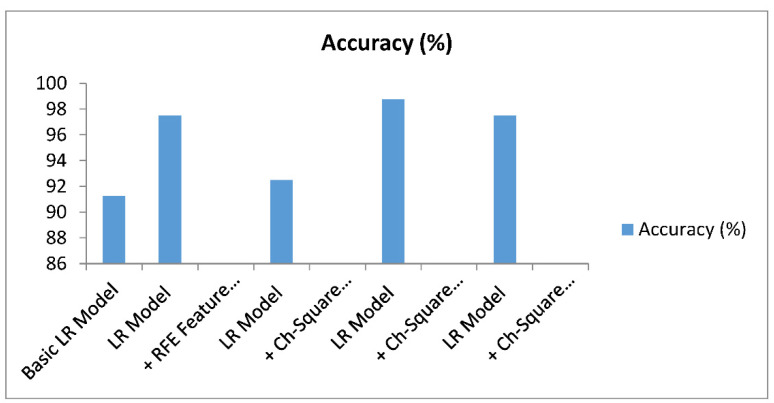
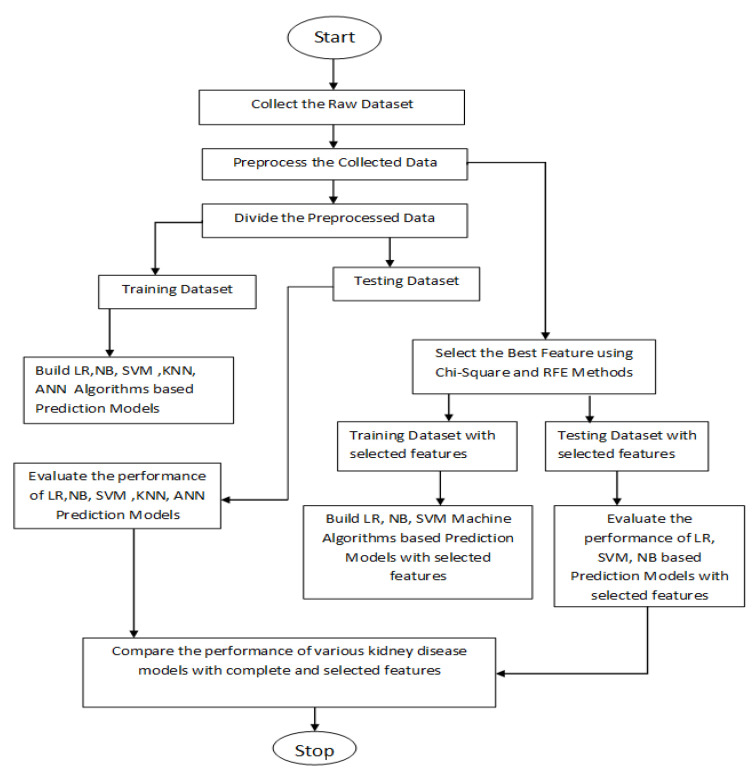
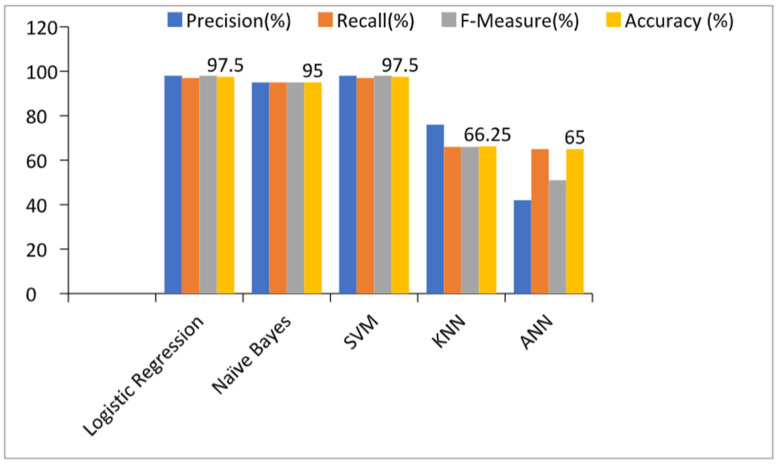
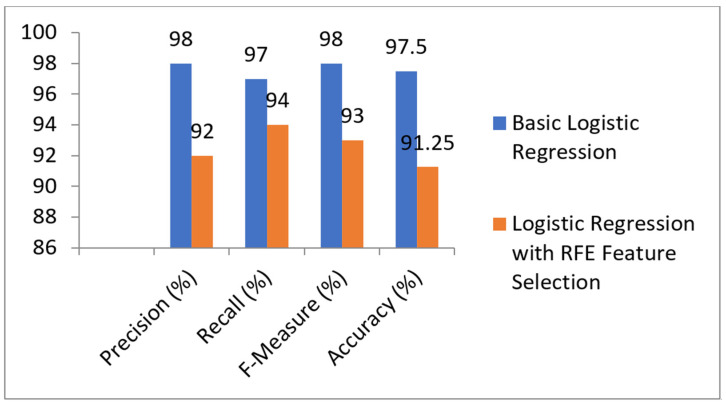
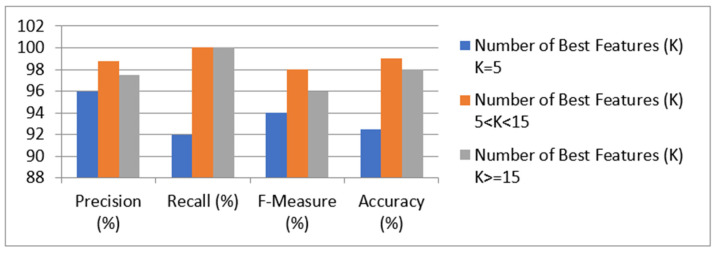
Kidney disease is a major public health concern that has only recently emerged. Toxins are removed from the body by the kidneys through urine. In the early stages of the condition, the patient has no problems, but recovery is difficult in the later stages. Doctors must be able to recognize this condition early in order to save the lives of their patients. To detect this illness early on, researchers have used a variety of methods. Prediction analysis based on machine learning has been shown to be more accurate than other methodologies. This research can help us to better understand global disparities in kidney disease, as well as what we can do to address them and coordinate our efforts to achieve global kidney health equity. This study provides an excellent feature-based prediction model for detecting kidney disease. Various machine learning algorithms, including k-nearest neighbors algorithm (KNN), artificial neural networks (ANN), support vector machines (SVM), naive bayes (NB), and others, as well as Re-cursive Feature Elimination (RFE) and Chi-Square test feature-selection techniques, were used to build and analyze various prediction models on a publicly available dataset of healthy and kidney disease patients. The studies found that a logistic regression-based prediction model with optimal features chosen using the Chi-Square technique had the highest accuracy of 98.75 percent. White Blood Cell Count (Wbcc), Blood Glucose Random (bgr), Blood Urea (Bu), Serum Creatinine (Sc), Packed Cell Volume (Pcv), Albumin (Al), Hemoglobin (Hemo), Age, Sugar (Su), Hypertension (Htn), Diabetes Mellitus (Dm), and Blood Pressure (Bp) are examples of these traits.
肾脏疾病是一个主要的公共卫生问题,直到最近才出现。毒素通过尿液由肾脏从体内排出。在该病症的早期阶段,患者没有问题,但在后期阶段恢复困难。医生必须能够尽早识别这种病症,以便挽救患者的生命。为了尽早检测出这种疾病,研究人员使用了多种方法。基于机器学习的预测分析已被证明比其他方法更准确。这项研究可以帮助我们更好地了解肾脏疾病的全球差异,以及我们可以采取哪些措施来解决这些差异,并协调我们的努力以实现全球肾脏健康公平。这项研究为检测肾脏疾病提供了一个出色的基于特征的预测模型。使用了各种机器学习算法,包括k近邻算法(KNN)、人工神经网络(ANN)、支持向量机(SVM)、朴素贝叶斯(NB)等,以及递归特征消除(RFE)和卡方检验特征选择技术,在一个公开可用的健康和肾脏疾病患者数据集上构建和分析各种预测模型。研究发现,使用卡方技术选择最优特征的基于逻辑回归的预测模型具有最高的准确率,为98.75%。这些特征的例子包括白细胞计数(Wbcc)、随机血糖(bgr)、血尿素(Bu)、血清肌酐(Sc)、红细胞压积(Pcv)、白蛋白(Al)、血红蛋白(Hemo)、年龄、血糖(Su)、高血压(Htn)、糖尿病(Dm)和血压(Bp)。