Bruschetta Roberta, Tartarisco Gennaro, Lucca Lucia Francesca, Leto Elio, Ursino Maria, Tonin Paolo, Pioggia Giovanni, Cerasa Antonio
Institute for Biomedical Research and Innovation (IRIB), National Research Council of Italy (CNR), 98164 Messina, Italy.
Department of Engineering, Università Campus Bio-Medico di Roma, Via Alvaro del Portillo 21, 00128 Rome, Italy.
Biomedicines. 2022 Mar 16;10(3):686. doi: 10.3390/biomedicines10030686.
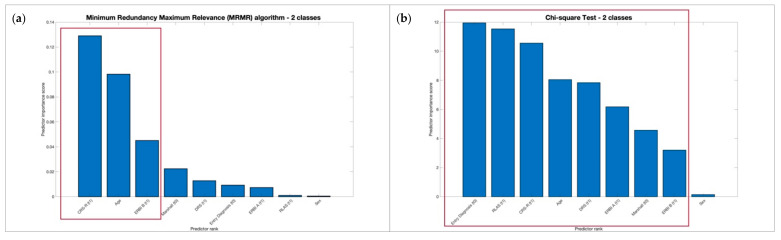
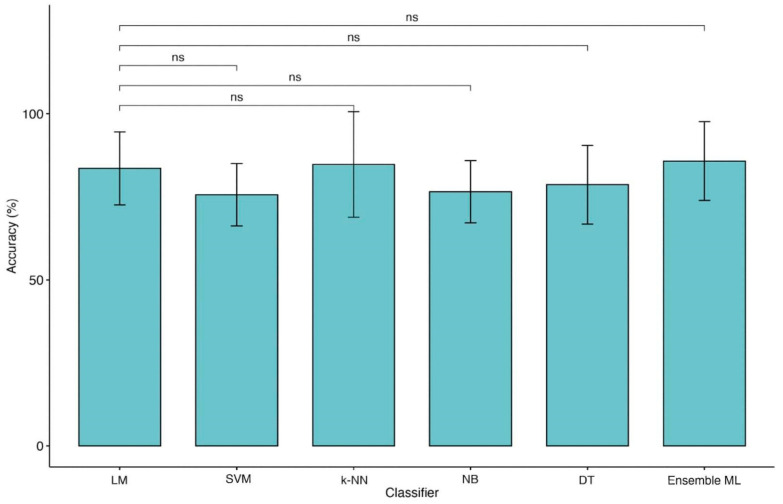
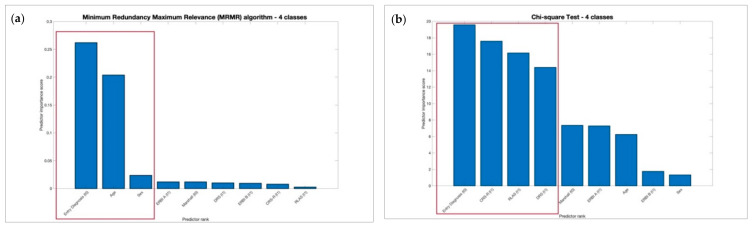
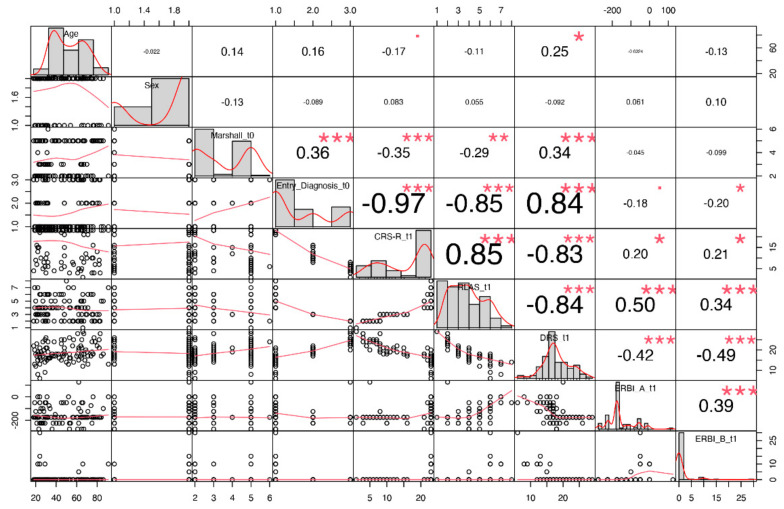
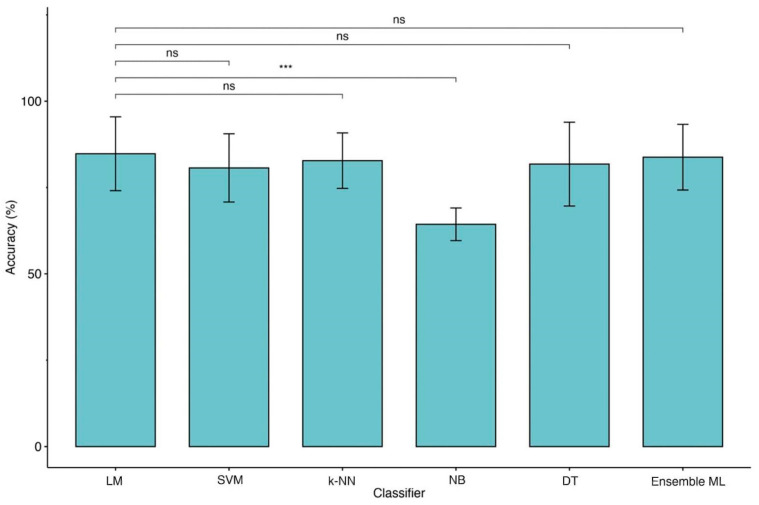
One of the main challenges in traumatic brain injury (TBI) patients is to achieve an early and definite prognosis. Despite the recent development of algorithms based on artificial intelligence for the identification of these prognostic factors relevant for clinical practice, the literature lacks a rigorous comparison among classical regression and machine learning (ML) models. This study aims at providing this comparison on a sample of TBI patients evaluated at baseline (T0), after 3 months from the event (T1), and at discharge (T2). A Classical Linear Regression Model (LM) was compared with independent performances of Support Vector Machine (SVM), k-Nearest Neighbors (k-NN), Naïve Bayes (NB) and Decision Tree (DT) algorithms, together with an ensemble ML approach. The accuracy was similar among LM and ML algorithms on the analyzed sample when two classes of outcome (Positive vs. Negative) approach was used, whereas the NB algorithm showed the worst performance. This study highlights the utility of comparing traditional regression modeling to ML, particularly when using a small number of reliable predictor variables after TBI. The dataset of clinical data used to train ML algorithms will be publicly available to other researchers for future comparisons.
创伤性脑损伤(TBI)患者面临的主要挑战之一是实现早期明确的预后。尽管最近基于人工智能开发了用于识别这些与临床实践相关的预后因素的算法,但文献中缺乏对经典回归模型和机器学习(ML)模型的严格比较。本研究旨在对一组在基线(T0)、事件发生后3个月(T1)和出院时(T2)进行评估的TBI患者样本进行这种比较。将经典线性回归模型(LM)与支持向量机(SVM)、k近邻(k-NN)、朴素贝叶斯(NB)和决策树(DT)算法的独立性能进行比较,并结合一种集成ML方法。当使用两类结果(阳性与阴性)方法时,LM和ML算法在分析样本上的准确性相似,而NB算法表现最差。本研究强调了将传统回归建模与ML进行比较的实用性,特别是在TBI后使用少量可靠预测变量时。用于训练ML算法的临床数据数据集将向其他研究人员公开,以供未来比较。