SimulaMet, Oslo, Norway.
Oslo Metropolitan University, Oslo, Norway.
PLoS One. 2022 May 2;17(5):e0267976. doi: 10.1371/journal.pone.0267976. eCollection 2022.
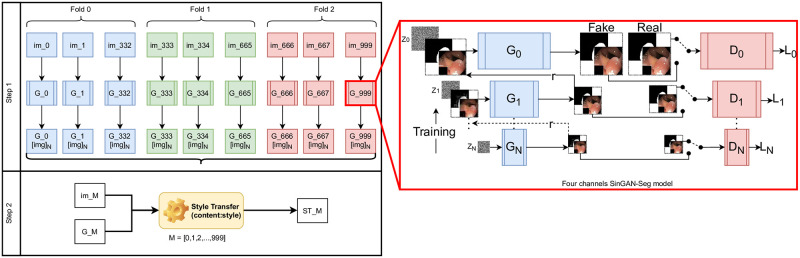
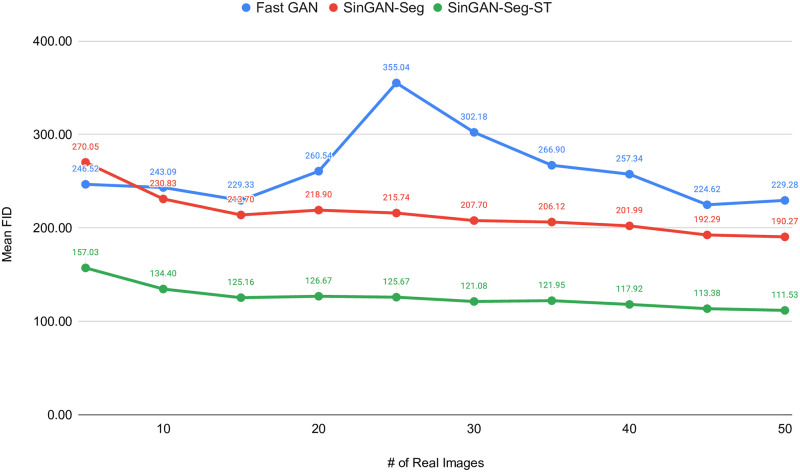
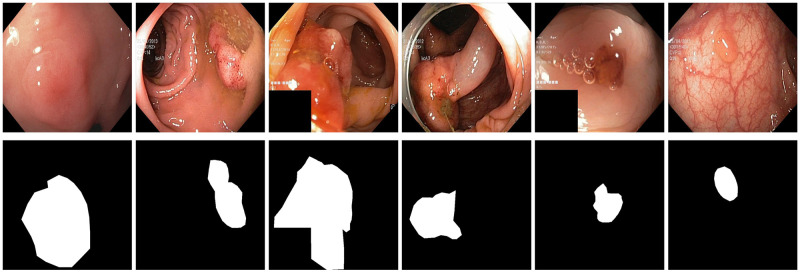
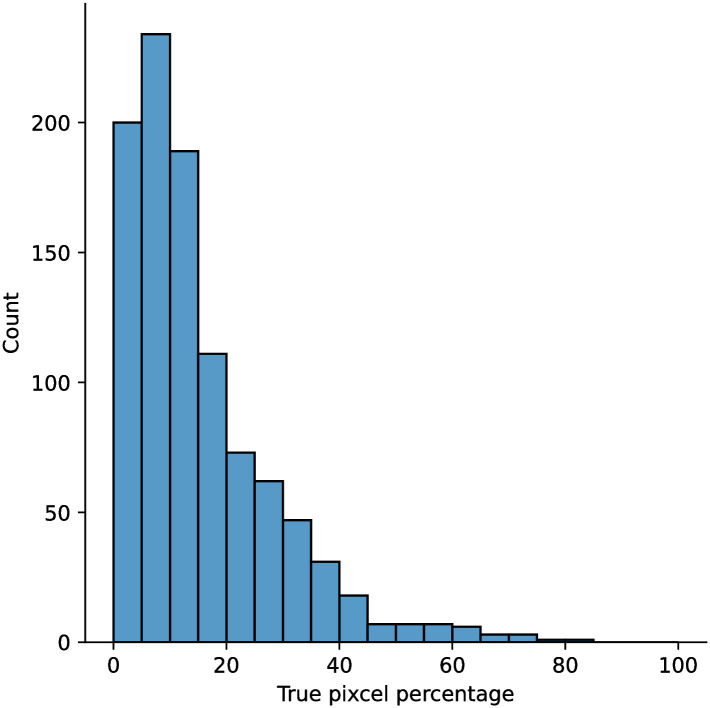
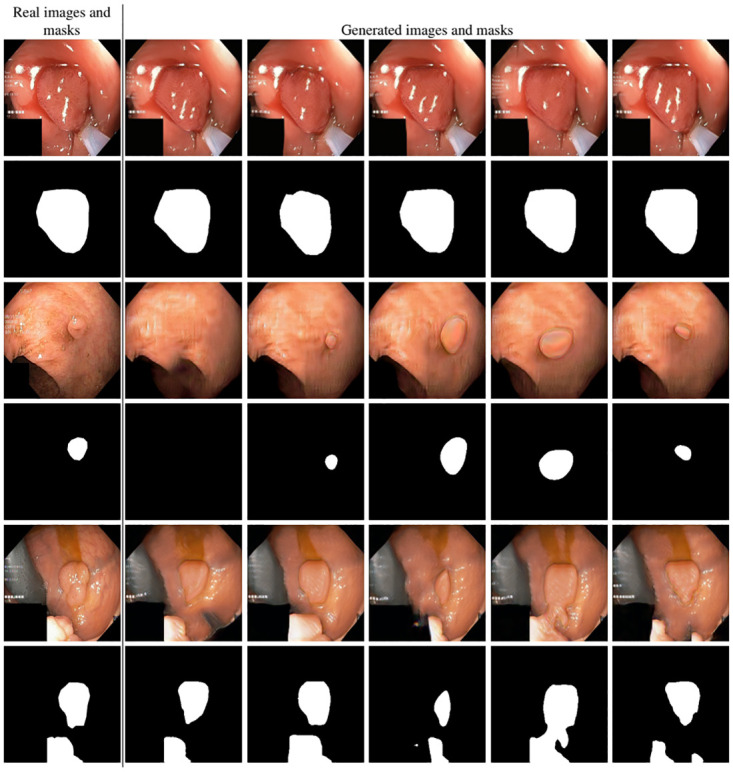
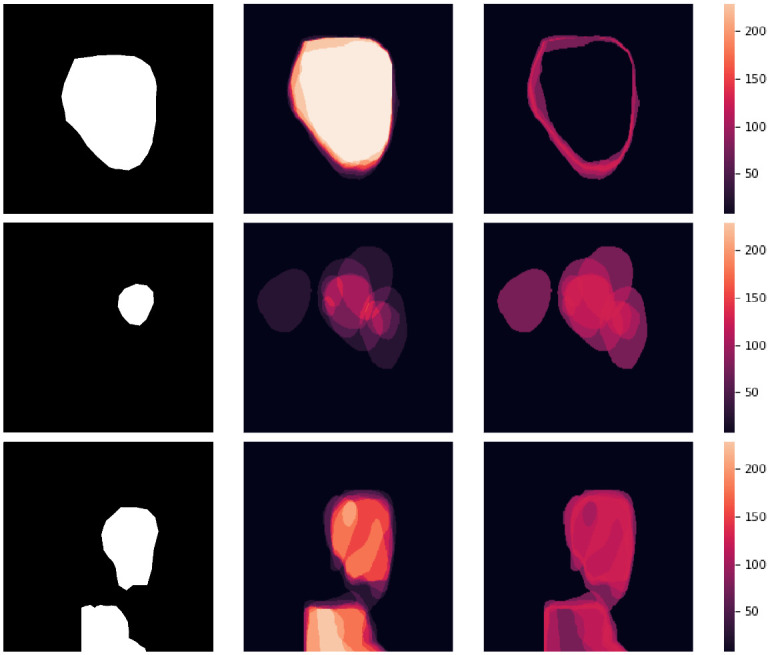
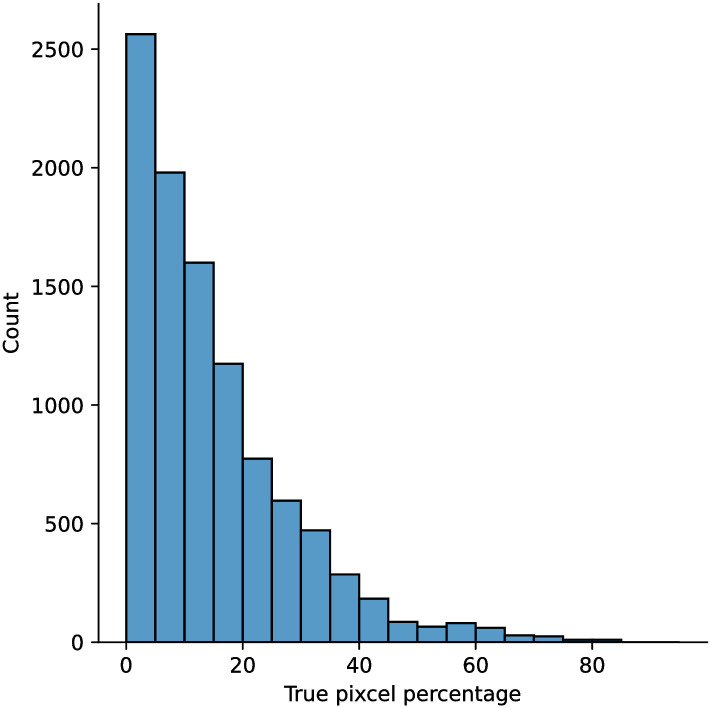
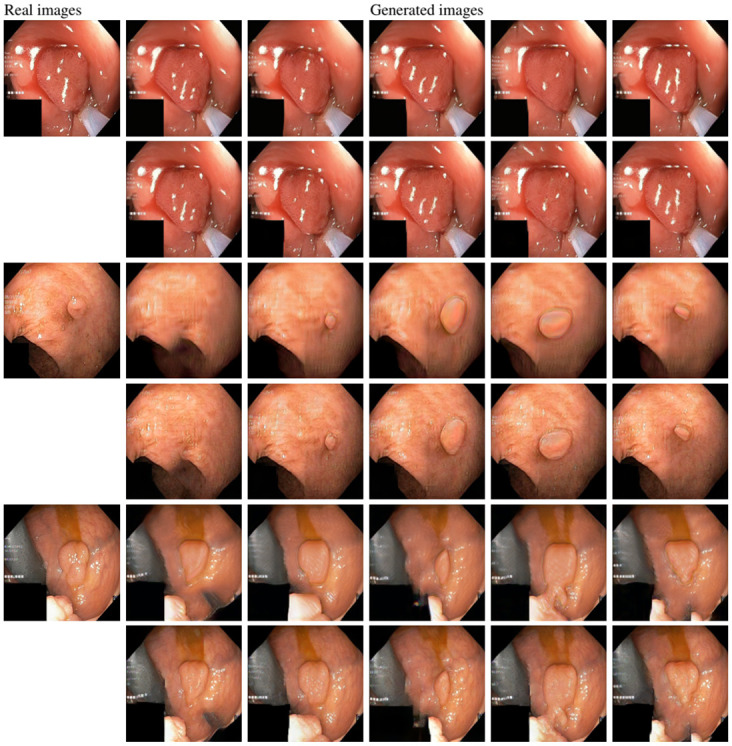
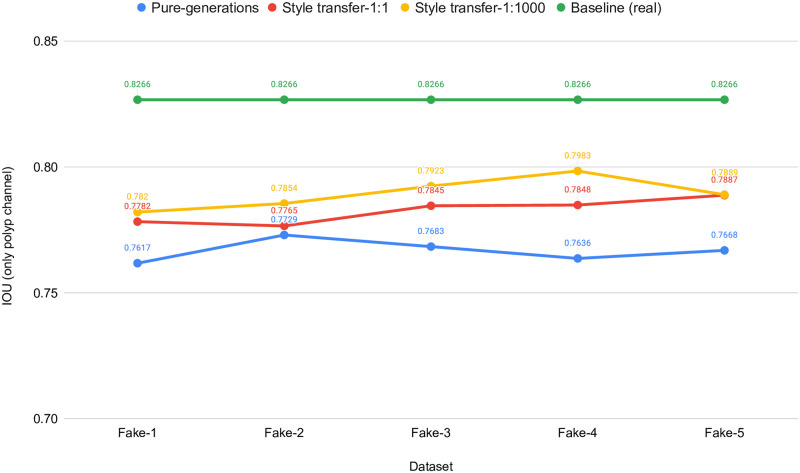
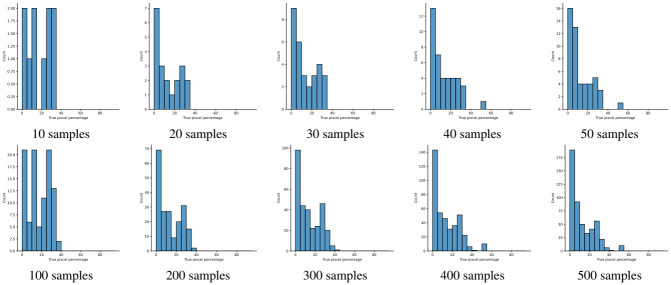
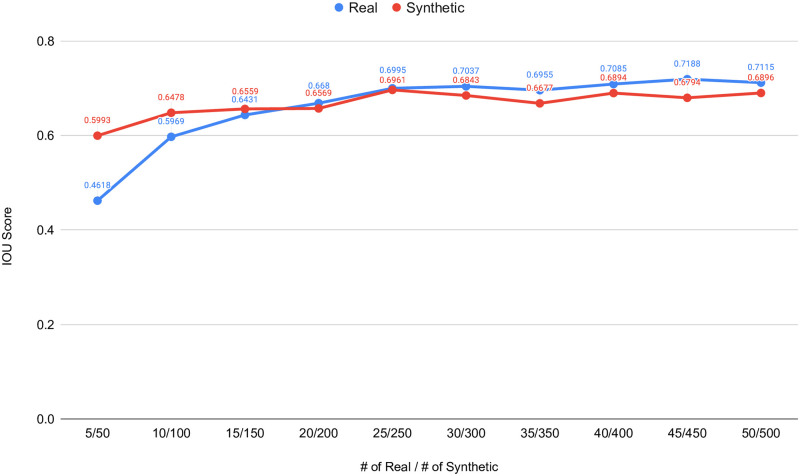
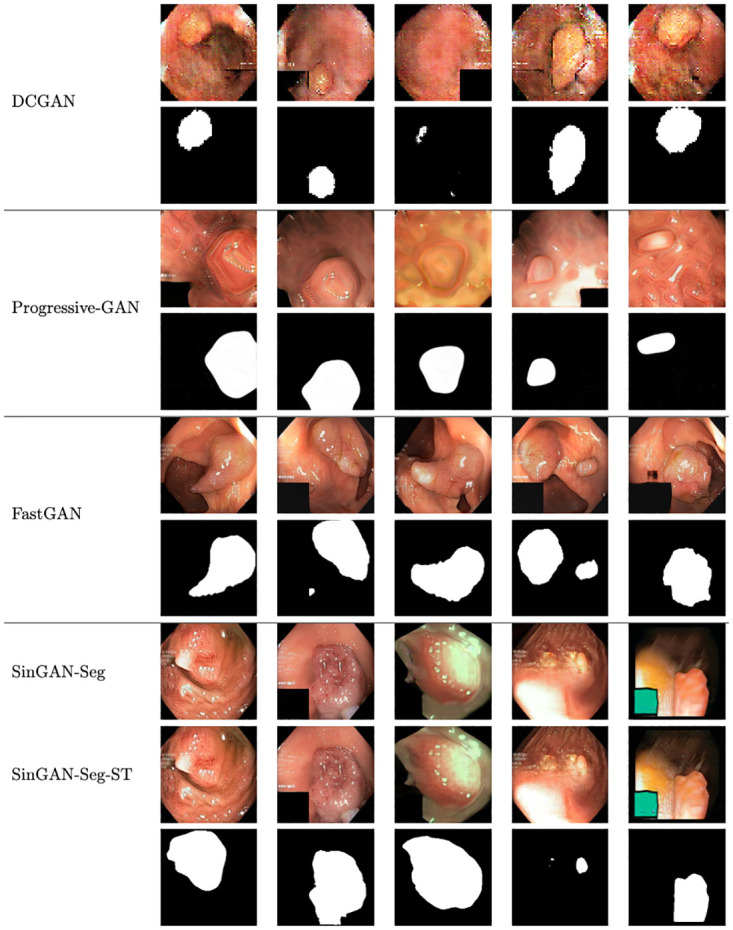
Analyzing medical data to find abnormalities is a time-consuming and costly task, particularly for rare abnormalities, requiring tremendous efforts from medical experts. Therefore, artificial intelligence has become a popular tool for the automatic processing of medical data, acting as a supportive tool for doctors. However, the machine learning models used to build these tools are highly dependent on the data used to train them. Large amounts of data can be difficult to obtain in medicine due to privacy reasons, expensive and time-consuming annotations, and a general lack of data samples for infrequent lesions. In this study, we present a novel synthetic data generation pipeline, called SinGAN-Seg, to produce synthetic medical images with corresponding masks using a single training image. Our method is different from the traditional generative adversarial networks (GANs) because our model needs only a single image and the corresponding ground truth to train. We also show that the synthetic data generation pipeline can be used to produce alternative artificial segmentation datasets with corresponding ground truth masks when real datasets are not allowed to share. The pipeline is evaluated using qualitative and quantitative comparisons between real data and synthetic data to show that the style transfer technique used in our pipeline significantly improves the quality of the generated data and our method is better than other state-of-the-art GANs to prepare synthetic images when the size of training datasets are limited. By training UNet++ using both real data and the synthetic data generated from the SinGAN-Seg pipeline, we show that the models trained on synthetic data have very close performances to those trained on real data when both datasets have a considerable amount of training data. In contrast, we show that synthetic data generated from the SinGAN-Seg pipeline improves the performance of segmentation models when training datasets do not have a considerable amount of data. All experiments were performed using an open dataset and the code is publicly available on GitHub.
分析医学数据以发现异常是一项耗时且昂贵的任务,尤其是对于罕见的异常情况,需要医学专家付出巨大的努力。因此,人工智能已成为医学数据自动处理的流行工具,可作为医生的辅助工具。但是,用于构建这些工具的机器学习模型高度依赖于用于训练它们的数据。由于隐私原因、昂贵且耗时的注释以及罕见病变的一般缺乏数据样本,医学中大量数据难以获取。在这项研究中,我们提出了一种新颖的合成数据生成管道,称为 SinGAN-Seg,可使用单个训练图像生成具有相应掩模的合成医学图像。我们的方法与传统的生成对抗网络(GAN)不同,因为我们的模型仅需要单个图像和相应的地面实况即可进行训练。我们还表明,当不允许共享真实数据集时,合成数据生成管道可用于生成具有相应地面实况掩模的替代人工分割数据集。通过在真实数据和合成数据之间进行定性和定量比较来评估该管道,以表明我们的管道中使用的样式转移技术可显著提高生成数据的质量,并且当训练数据集较小时,我们的方法比其他最先进的 GAN 更适合准备合成图像。通过在真实数据和从 SinGAN-Seg 管道生成的合成数据上同时训练 UNet++,我们表明,当两个数据集都具有相当数量的训练数据时,在合成数据上训练的模型的性能与在真实数据上训练的模型非常接近。相比之下,我们表明,当训练数据集没有相当数量的数据时,从 SinGAN-Seg 管道生成的合成数据可以提高分割模型的性能。所有实验均使用公开数据集进行,代码可在 GitHub 上公开获取。