Institute of Molecular Systems Biology, Department of Biology, ETH Zurich, Zurich 8093, Switzerland.
Inner Medicine I, Faculty of Medicine, University of Tübingen, University Hospital Tübingen, 72074, Germany.
Bioinformatics. 2022 Jun 24;38(Suppl 1):i290-i298. doi: 10.1093/bioinformatics/btac227.
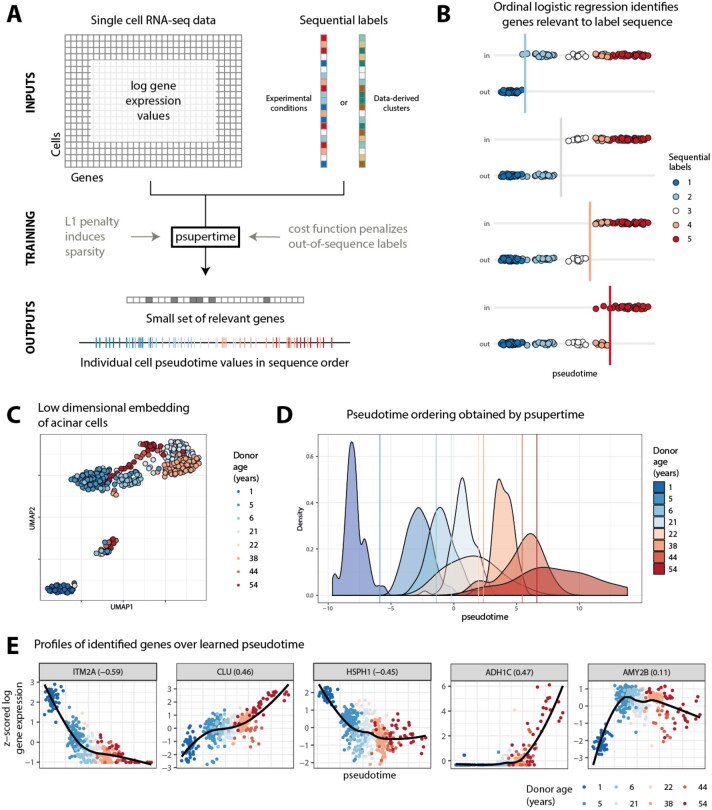
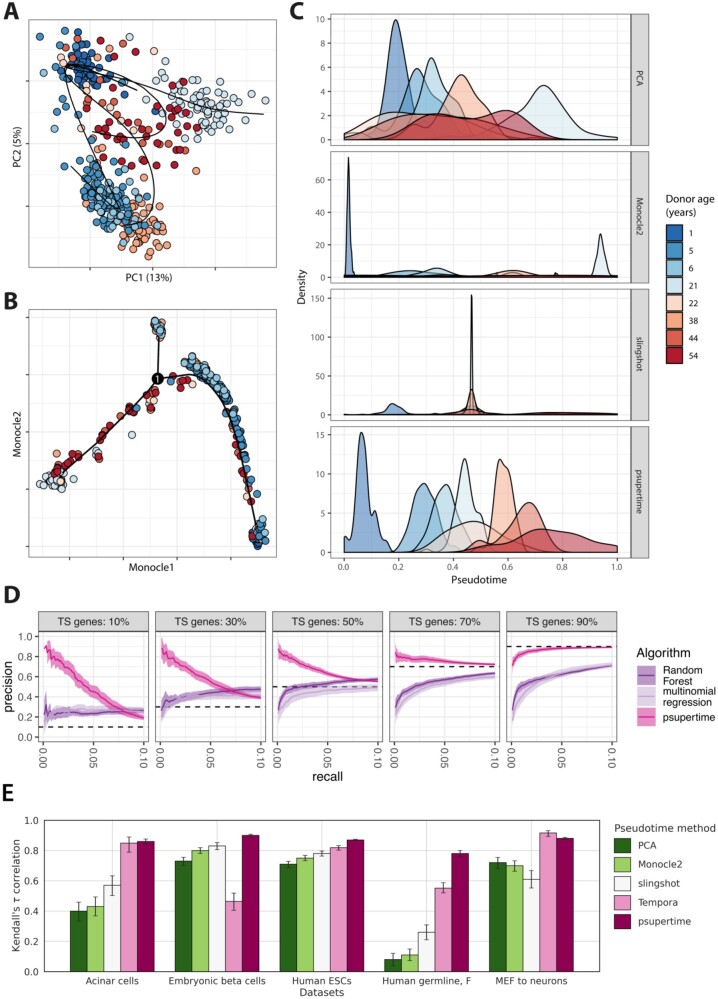
Improvements in single-cell RNA-seq technologies mean that studies measuring multiple experimental conditions, such as time series, have become more common. At present, few computational methods exist to infer time series-specific transcriptome changes, and such studies have therefore typically used unsupervised pseudotime methods. While these methods identify cell subpopulations and the transitions between them, they are not appropriate for identifying the genes that vary coherently along the time series. In addition, the orderings they estimate are based only on the major sources of variation in the data, which may not correspond to the processes related to the time labels.
We introduce psupertime, a supervised pseudotime approach based on a regression model, which explicitly uses time-series labels as input. It identifies genes that vary coherently along a time series, in addition to pseudotime values for individual cells, and a classifier that can be used to estimate labels for new data with unknown or differing labels. We show that psupertime outperforms benchmark classifiers in terms of identifying time-varying genes and provides better individual cell orderings than popular unsupervised pseudotime techniques. psupertime is applicable to any single-cell RNA-seq dataset with sequential labels (e.g. principally time series but also drug dosage and disease progression), derived from either experimental design and provides a fast, interpretable tool for targeted identification of genes varying along with specific biological processes.
R package available at github.com/wmacnair/psupertime and code for results reproduction at github.com/wmacnair/psupplementary.
Supplementary data are available at Bioinformatics online.
单细胞 RNA-seq 技术的改进意味着,测量多个实验条件(例如时间序列)的研究变得更加普遍。目前,很少有计算方法可以推断特定于时间序列的转录组变化,因此此类研究通常使用无监督的伪时间方法。虽然这些方法可以识别细胞亚群及其之间的转换,但它们不适合识别沿着时间序列一致变化的基因。此外,它们估计的排序仅基于数据中主要的变化来源,而这些来源可能与时间标签相关的过程不对应。
我们引入了 psupertime,这是一种基于回归模型的有监督伪时间方法,它明确地将时间序列标签用作输入。它除了为单个细胞识别伪时间值之外,还可以识别沿着时间序列一致变化的基因,以及可以用于估计具有未知或不同标签的新数据标签的分类器。我们表明,psupertime 在识别时变基因方面优于基准分类器,并提供了比流行的无监督伪时间技术更好的单个细胞排序。psupertime 适用于具有顺序标签的任何单细胞 RNA-seq 数据集(例如主要是时间序列,但也有药物剂量和疾病进展),源自实验设计,并为靶向识别与特定生物过程一起变化的基因提供了快速、可解释的工具。
可在 github.com/wmacnair/psupertime 上获得 R 包,并在 github.com/wmacnair/psupplementary 上获得结果重现的代码。
补充数据可在生物信息学在线获得。