Department of Genetics, Stanford University, Stanford, CA 94305, USA.
Illumina Artificial Intelligence Laboratory, Illumina Inc., San Diego, CA 92122, USA.
Bioinformatics. 2022 Aug 2;38(15):3802-3811. doi: 10.1093/bioinformatics/btac403.
Longitudinal studies increasingly collect rich 'omics' data sampled frequently over time and across large cohorts to capture dynamic health fluctuations and disease transitions. However, the generation of longitudinal omics data has preceded the development of analysis tools that can efficiently extract insights from such data. In particular, there is a need for statistical frameworks that can identify not only which omics features are differentially regulated between groups but also over what time intervals. Additionally, longitudinal omics data may have inconsistencies, including non-uniform sampling intervals, missing data points, subject dropout and differing numbers of samples per subject.
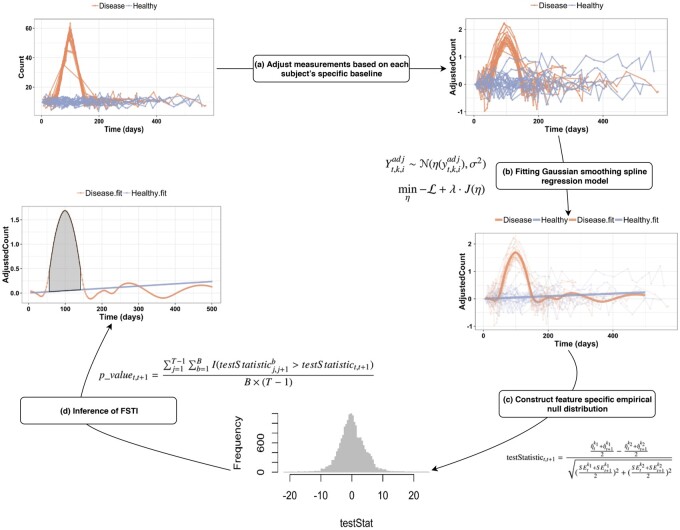
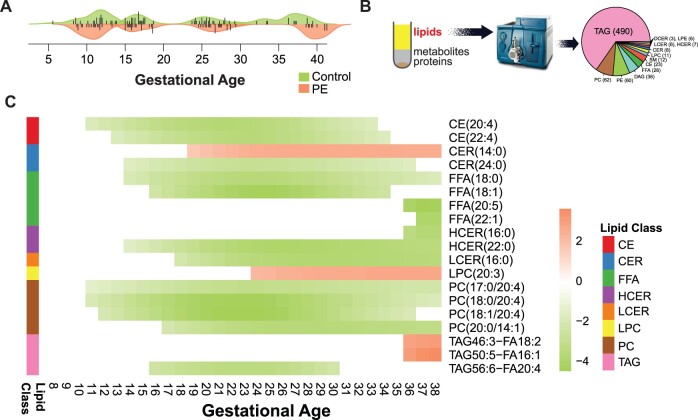
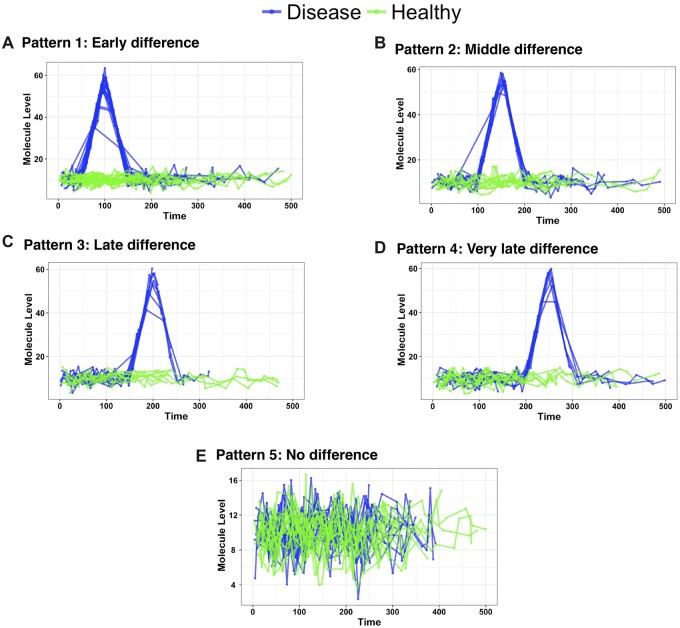
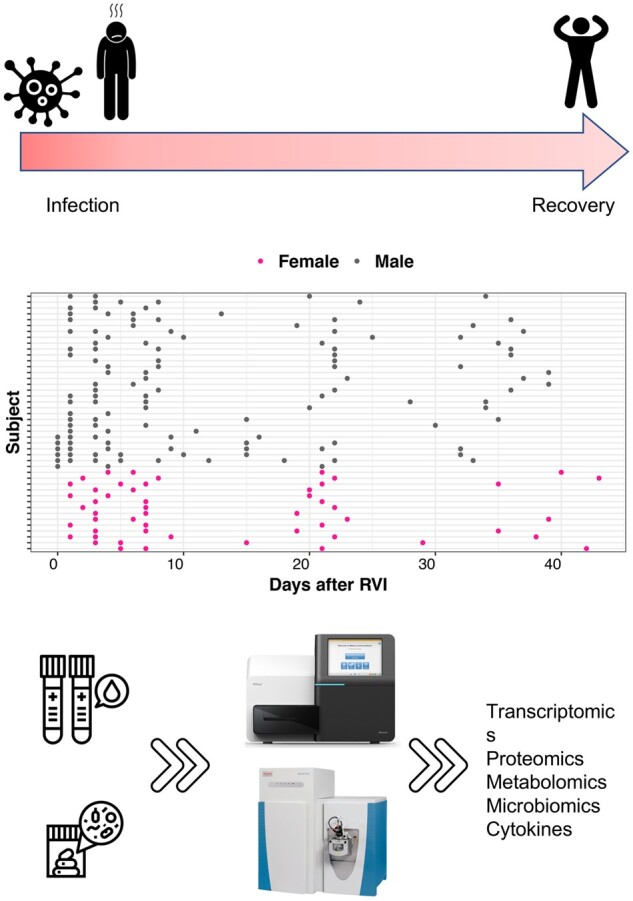
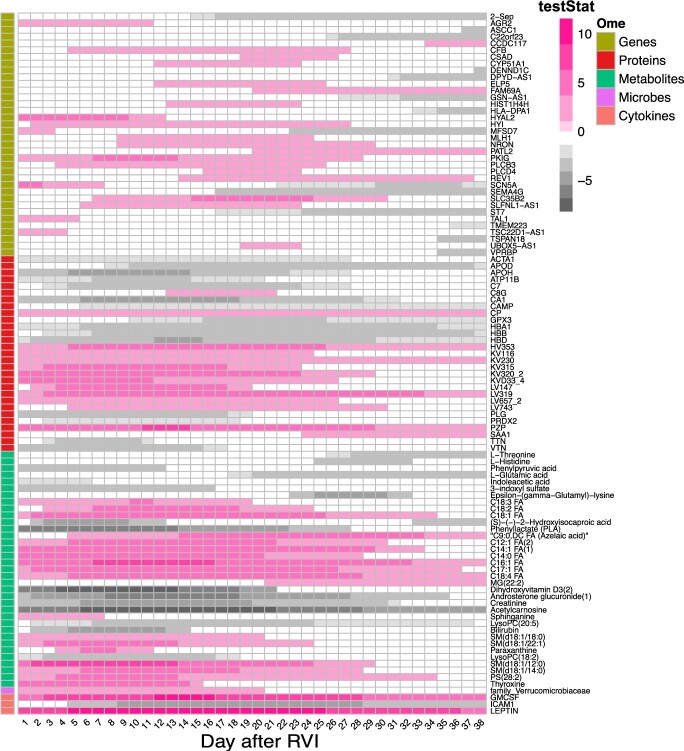
In this work, we developed OmicsLonDA, a statistical method that provides robust identification of time intervals of temporal omics biomarkers. OmicsLonDA is based on a semi-parametric approach, in which we use smoothing splines to model longitudinal data and infer significant time intervals of omics features based on an empirical distribution constructed through a permutation procedure. We benchmarked OmicsLonDA on five simulated datasets with diverse temporal patterns, and the method showed specificity greater than 0.99 and sensitivity greater than 0.87. Applying OmicsLonDA to the iPOP cohort revealed temporal patterns of genes, proteins, metabolites and microbes that are differentially regulated in male versus female subjects following a respiratory infection. In addition, we applied OmicsLonDA to a longitudinal multi-omics dataset of pregnant women with and without preeclampsia, and OmicsLonDA identified potential lipid markers that are temporally significantly different between the two groups.
We provide an open-source R package (https://bioconductor.org/packages/OmicsLonDA), to enable widespread use.
Supplementary data are available at Bioinformatics online.
越来越多的纵向研究收集了丰富的“组学”数据,这些数据在时间和大样本量上进行频繁采样,以捕捉动态的健康波动和疾病转变。然而,纵向组学数据的产生先于能够从这些数据中有效提取见解的分析工具的发展。特别是,需要有统计框架,不仅能够识别组间差异调节的组学特征,还能够识别在什么时间间隔上。此外,纵向组学数据可能存在不一致性,包括非均匀采样间隔、缺失数据点、受试者脱落和每个受试者的样本数量不同。
在这项工作中,我们开发了 OmicsLonDA,这是一种提供稳健识别时间组学生物标志物时间间隔的统计方法。OmicsLonDA 基于半参数方法,我们使用平滑样条来对纵向数据进行建模,并根据通过置换过程构建的经验分布来推断组学特征的显著时间间隔。我们在五个具有不同时间模式的模拟数据集上对 OmicsLonDA 进行了基准测试,该方法的特异性大于 0.99,灵敏度大于 0.87。将 OmicsLonDA 应用于 iPOP 队列揭示了在呼吸道感染后男性与女性受试者之间差异调节的基因、蛋白质、代谢物和微生物的时间模式。此外,我们将 OmicsLonDA 应用于患有和不患有先兆子痫的孕妇的纵向多组学数据集,OmicsLonDA 确定了两组之间在时间上显著不同的潜在脂质标志物。
我们提供了一个开源的 R 包(https://bioconductor.org/packages/OmicsLonDA),以实现广泛使用。
补充数据可在 Bioinformatics 在线获取。