Albalawi Yahya, Nikolov Nikola S, Buckley Jim
Department of Computer Science and Information Systems, University of Limerick, Limerick, Ireland.
Department of Computer and Information Sciences, College of Arts and Science, University of Taibah, Al-Ula, Saudi Arabia.
JMIR Form Res. 2022 Jun 29;6(6):e34834. doi: 10.2196/34834.
In recent years, social media has become a major channel for health-related information in Saudi Arabia. Prior health informatics studies have suggested that a large proportion of health-related posts on social media are inaccurate. Given the subject matter and the scale of dissemination of such information, it is important to be able to automatically discriminate between accurate and inaccurate health-related posts in Arabic.
The first aim of this study is to generate a data set of generic health-related tweets in Arabic, labeled as either accurate or inaccurate health information. The second aim is to leverage this data set to train a state-of-the-art deep learning model for detecting the accuracy of health-related tweets in Arabic. In particular, this study aims to train and compare the performance of multiple deep learning models that use pretrained word embeddings and transformer language models.
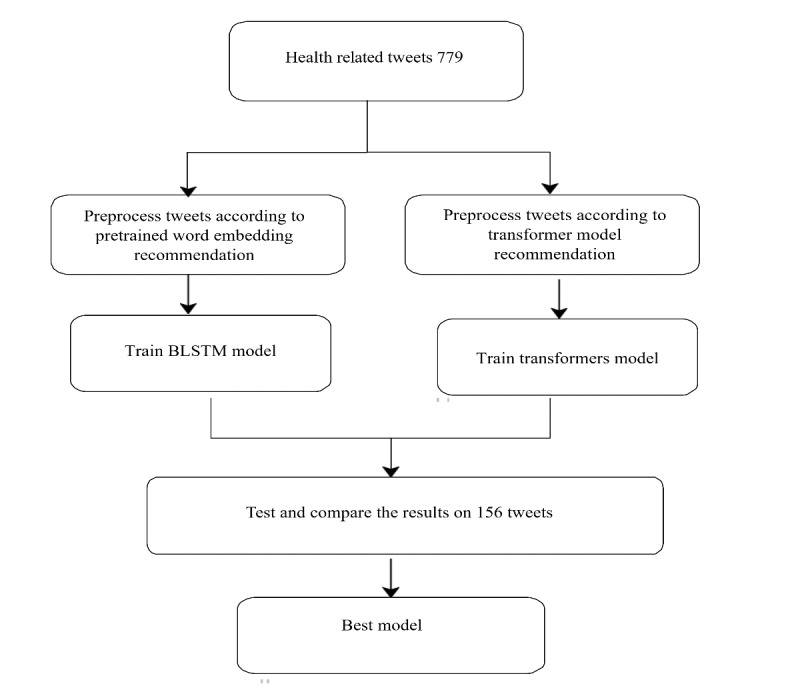
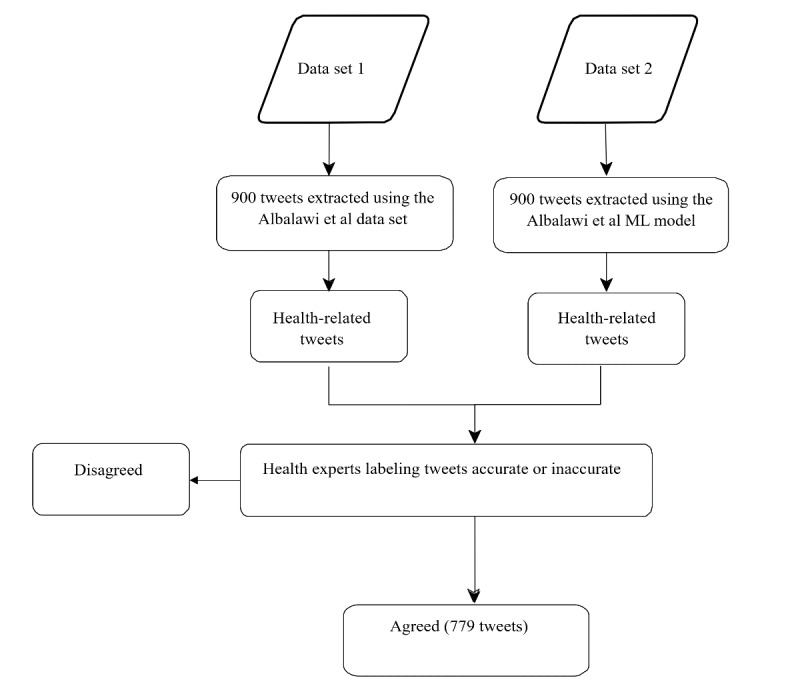
We used 900 health-related tweets from a previously published data set extracted between July 15, 2019, and August 31, 2019. Furthermore, we applied a pretrained model to extract an additional 900 health-related tweets from a second data set collected specifically for this study between March 1, 2019, and April 15, 2019. The 1800 tweets were labeled by 2 physicians as accurate, inaccurate, or unsure. The physicians agreed on 43.3% (779/1800) of tweets, which were thus labeled as accurate or inaccurate. A total of 9 variations of the pretrained transformer language models were then trained and validated on 79.9% (623/779 tweets) of the data set and tested on 20% (156/779 tweets) of the data set. For comparison, we also trained a bidirectional long short-term memory model with 7 different pretrained word embeddings as the input layer on the same data set. The models were compared in terms of their accuracy, precision, recall, F score, and macroaverage of the F score.
We constructed a data set of labeled tweets, 38% (296/779) of which were labeled as inaccurate health information, and 62% (483/779) of which were labeled as accurate health information. We suggest that this was highly efficacious as we did not include any tweets in which the physician annotators were unsure or in disagreement. Among the investigated deep learning models, the Transformer-based Model for Arabic Language Understanding version 0.2 (AraBERTv0.2)-large model was the most accurate, with an F score of 87%, followed by AraBERT version 2-large and AraBERTv0.2-base.
Our results indicate that the pretrained language model AraBERTv0.2 is the best model for classifying tweets as carrying either inaccurate or accurate health information. Future studies should consider applying ensemble learning to combine the best models as it may produce better results.
近年来,社交媒体已成为沙特阿拉伯健康相关信息的主要传播渠道。先前的健康信息学研究表明,社交媒体上很大一部分与健康相关的帖子是不准确的。鉴于此类信息的主题和传播规模,能够自动区分阿拉伯语中准确和不准确的健康相关帖子非常重要。
本研究的首要目标是生成一个阿拉伯语通用健康相关推文的数据集,标记为准确或不准确的健康信息。第二个目标是利用该数据集训练一个先进的深度学习模型,用于检测阿拉伯语健康相关推文的准确性。具体而言,本研究旨在训练和比较多个使用预训练词嵌入和Transformer语言模型的深度学习模型的性能。
我们使用了先前发布的数据集中在2019年7月15日至2019年8月31日期间提取的900条与健康相关的推文。此外,我们应用一个预训练模型从专门为本研究收集的第二个数据集中提取另外900条与健康相关的推文,该数据集收集于2019年3月1日至2019年4月15日。这1800条推文由2名医生标记为准确、不准确或不确定。医生们对43.3%(779/1800)的推文达成了一致,这些推文因此被标记为准确或不准确。然后,在数据集的79.9%(623/779条推文)上训练并验证了预训练Transformer语言模型的9种变体,并在数据集的20%(156/779条推文)上进行了测试。为了进行比较,我们还在同一数据集上训练了一个双向长短期记忆模型,以7种不同的预训练词嵌入作为输入层。根据模型的准确率、精确率、召回率、F分数和F分数的宏平均对这些模型进行了比较。
我们构建了一个带标签推文的数据集,其中38%(296/779)被标记为不准确的健康信息,62%(483/779)被标记为准确的健康信息。我们认为这非常有效,因为我们没有纳入任何医生注释者不确定或存在分歧的推文。在研究的深度学习模型中,基于Transformer的阿拉伯语语言理解模型版本0.2(AraBERTv0.2)-大型模型最准确,F分数为87%,其次是AraBERT版本2-大型和AraBERTv0.2-基础模型。
我们的结果表明,预训练语言模型AraBERTv0.2是将推文分类为携带不准确或准确健康信息的最佳模型。未来的研究应考虑应用集成学习来组合最佳模型,因为这可能会产生更好的结果。