Sulc Jonathan, Sjaarda Jennifer, Kutalik Zoltán
University Center for Primary Care and Public Health, University of Lausanne, Lausanne, Switzerland.
Swiss Institute of Bioinformatics, Lausanne, Switzerland.
HGG Adv. 2022 Jun 22;3(3):100124. doi: 10.1016/j.xhgg.2022.100124. eCollection 2022 Jul 14.
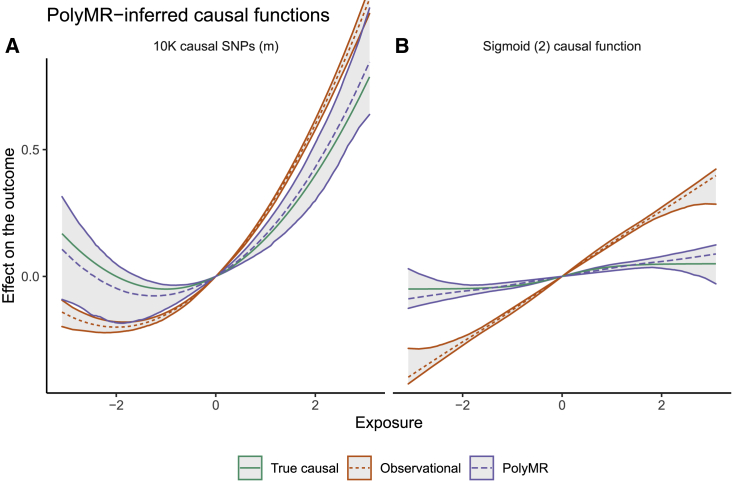
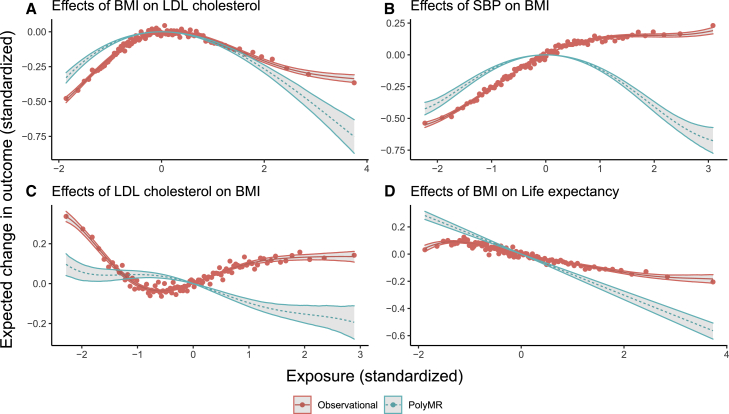
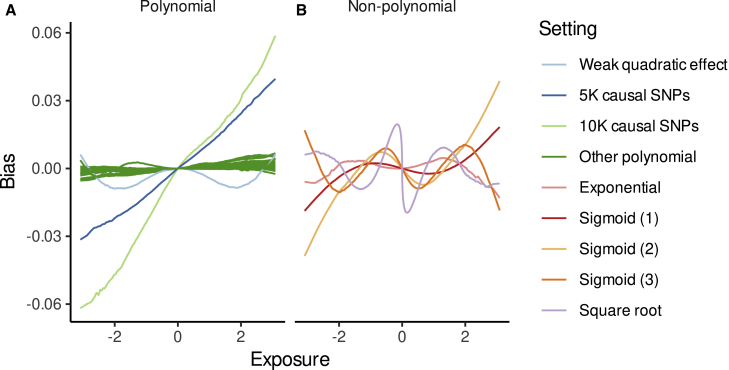
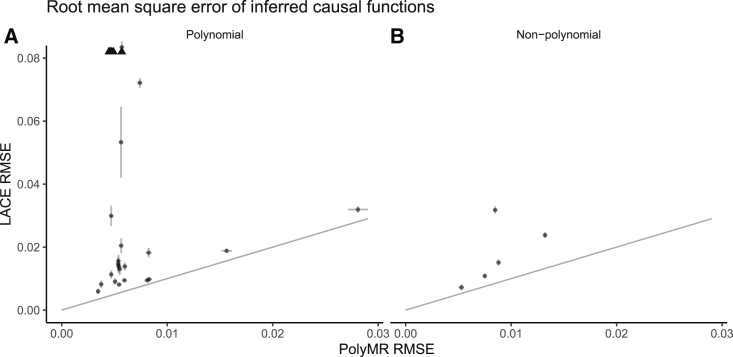
Causal inference is a critical step in improving our understanding of biological processes, and Mendelian randomization (MR) has emerged as one of the foremost methods to efficiently interrogate diverse hypotheses using large-scale, observational data from biobanks. Although many extensions have been developed to address the three core assumptions of MR-based causal inference (relevance, exclusion restriction, and exchangeability), most approaches implicitly assume that any putative causal effect is linear. Here, we propose PolyMR, an MR-based method that provides a polynomial approximation of an (arbitrary) causal function between an exposure and an outcome. We show that this method provides accurate inference of the shape and magnitude of causal functions with greater accuracy than existing methods. We applied this method to data from the UK Biobank, testing for effects between anthropometric traits and continuous health-related phenotypes, and found most of these (84%) to have causal effects that deviate significantly from linear. These deviations ranged from slight attenuation at the extremes of the exposure distribution, to large changes in the magnitude of the effect across the range of the exposure (e.g., a 1 kg/m change in BMI having stronger effects on glucose levels if the initial BMI was higher), to non-monotonic causal relationships (e.g., the effects of BMI on cholesterol forming an inverted U shape). Finally, we show that the linearity assumption of the causal effect may lead to the misinterpretation of health risks at the individual level or heterogeneous effect estimates when using cohorts with differing average exposure levels.
因果推断是增进我们对生物过程理解的关键一步,孟德尔随机化(MR)已成为利用生物样本库的大规模观测数据有效探究各种假设的首要方法之一。尽管已经开发了许多扩展方法来解决基于MR的因果推断的三个核心假设(相关性、排除限制和可交换性),但大多数方法都隐含地假设任何假定的因果效应都是线性的。在这里,我们提出了PolyMR,一种基于MR的方法,它提供了暴露与结果之间(任意)因果函数的多项式近似。我们表明,该方法能够比现有方法更准确地推断因果函数的形状和大小。我们将此方法应用于英国生物样本库的数据,测试人体测量特征与连续健康相关表型之间的效应,发现其中大部分(84%)的因果效应显著偏离线性。这些偏差范围从暴露分布极端处的轻微衰减,到暴露范围内效应大小的巨大变化(例如,如果初始BMI较高,BMI每变化1kg/m对血糖水平的影响更强),再到非单调因果关系(例如,BMI对胆固醇的影响呈倒U形)。最后,我们表明,因果效应的线性假设可能会导致在个体层面上对健康风险的误解,或者在使用平均暴露水平不同的队列时导致异质性效应估计。