Faculty of Geo-Information Science & Earth Observation, University of Twente, Enschede, The Netherlands.
Department of Social Statistics and Demography, University of Southampton, Southampton, United Kingdom.
PLoS One. 2022 Jul 21;17(7):e0271504. doi: 10.1371/journal.pone.0271504. eCollection 2022.
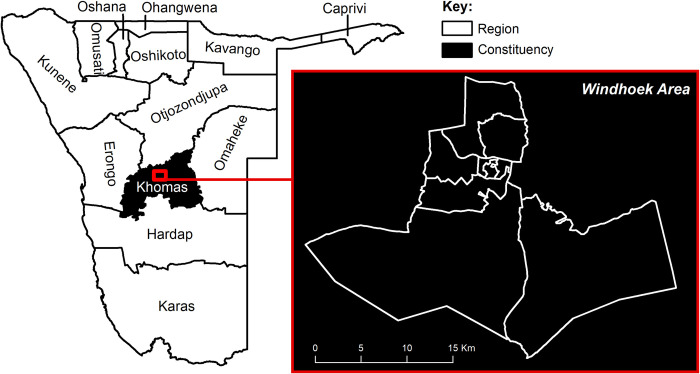
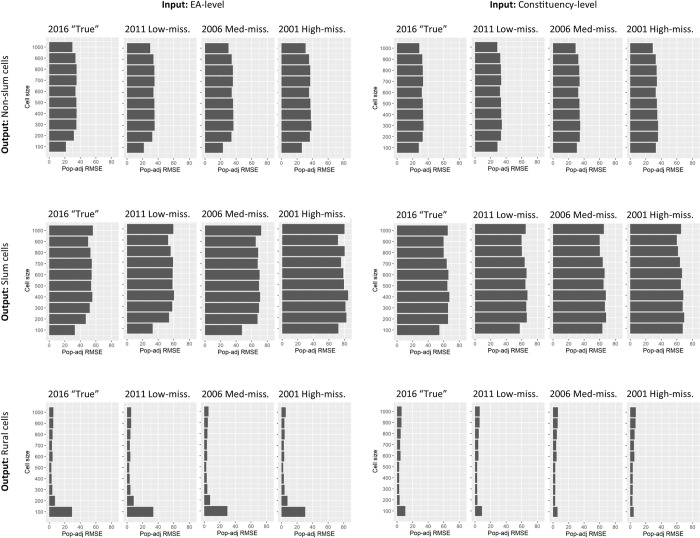
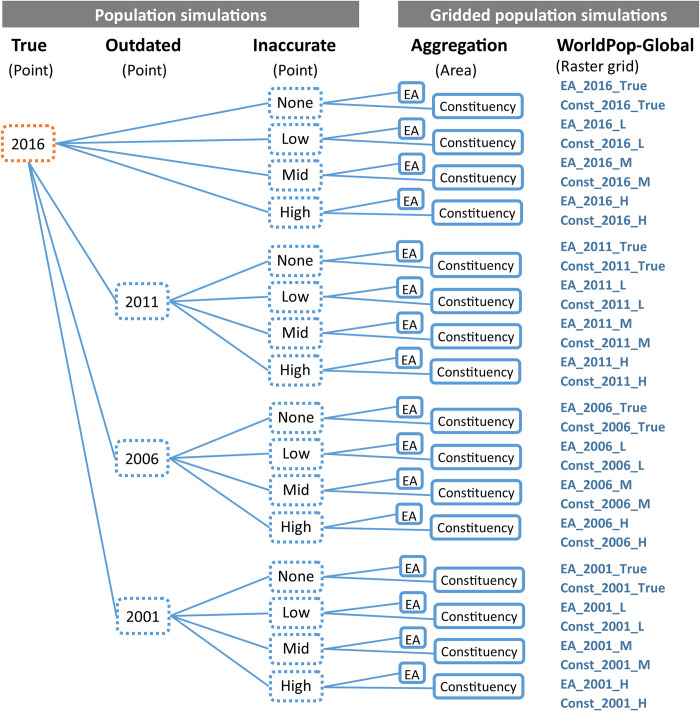
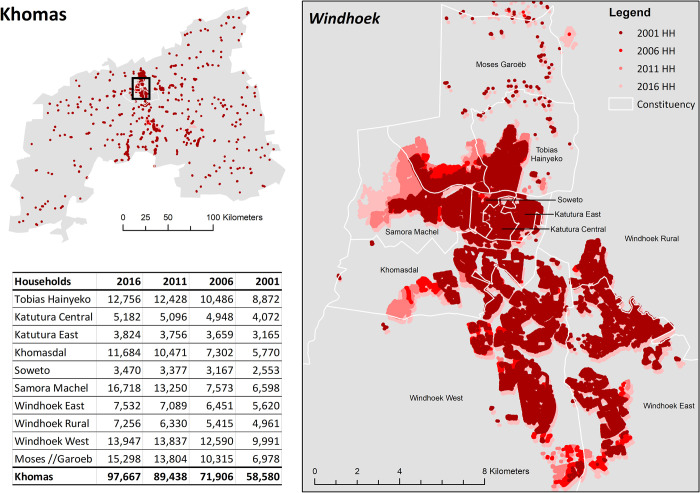
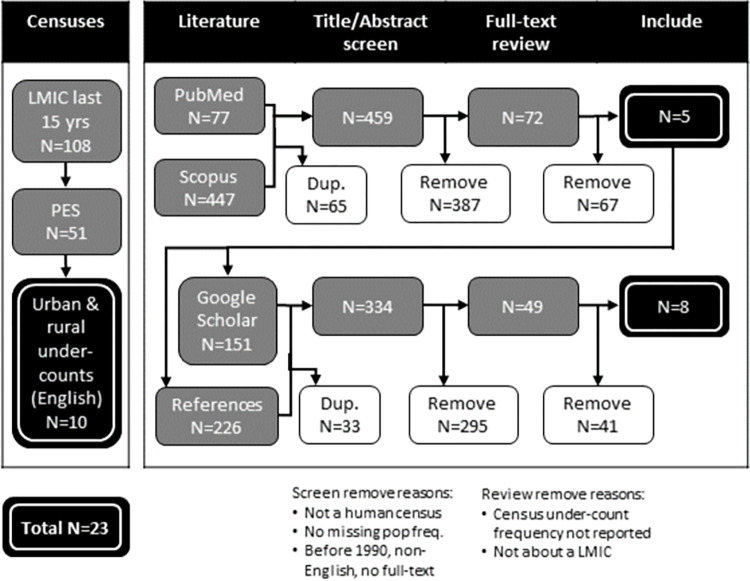
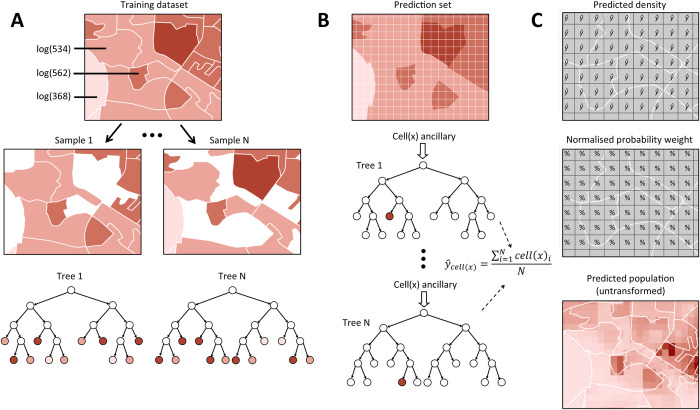
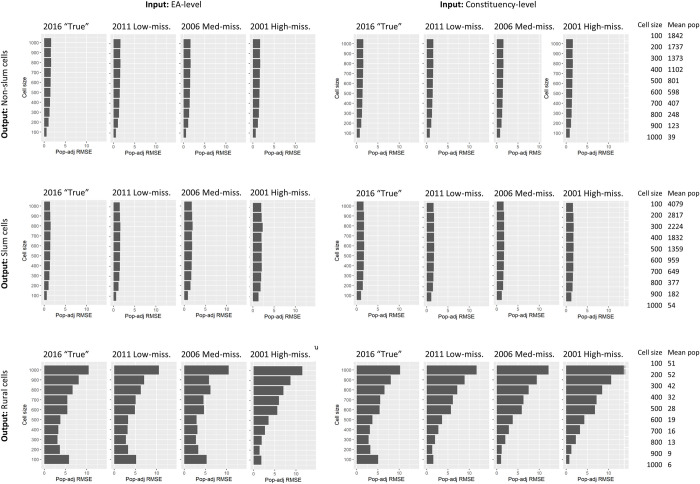
Disaggregated population counts are needed to calculate health, economic, and development indicators in Low- and Middle-Income Countries (LMICs), especially in settings of rapid urbanisation. Censuses are often outdated and inaccurate in LMIC settings, and rarely disaggregated at fine geographic scale. Modelled gridded population datasets derived from census data have become widely used by development researchers and practitioners; however, accuracy in these datasets are evaluated at the spatial scale of model input data which is generally courser than the neighbourhood or cell-level scale of many applications. We simulate a realistic synthetic 2016 population in Khomas, Namibia, a majority urban region, and introduce several realistic levels of outdatedness (over 15 years) and inaccuracy in slum, non-slum, and rural areas. We aggregate the synthetic populations by census and administrative boundaries (to mimic census data), resulting in 32 gridded population datasets that are typical of LMIC settings using the WorldPop-Global-Unconstrained gridded population approach. We evaluate the cell-level accuracy of these gridded population datasets using the original synthetic population as a reference. In our simulation, we found large cell-level errors, particularly in slum cells. These were driven by the averaging of population densities in large areal units before model training. Age, accuracy, and aggregation of the input data also played a role in these errors. We suggest incorporating finer-scale training data into gridded population models generally, and WorldPop-Global-Unconstrained in particular (e.g., from routine household surveys or slum community population counts), and use of new building footprint datasets as a covariate to improve cell-level accuracy (as done in some new WorldPop-Global-Constrained datasets). It is important to measure accuracy of gridded population datasets at spatial scales more consistent with how the data are being applied, especially if they are to be used for monitoring key development indicators at neighbourhood scales within cities.
需要对人口进行分类,以计算低收入和中等收入国家(LMICs)的健康、经济和发展指标,特别是在城市化迅速发展的情况下。在 LMIC 环境中,人口普查通常已经过时且不准确,而且很少按精细的地理尺度进行分类。从人口普查数据中派生的建模网格化人口数据集已被发展研究人员和从业者广泛使用;然而,这些数据集的准确性是在模型输入数据的空间尺度上进行评估的,而该尺度通常比许多应用程序的邻里或单元尺度更粗糙。我们模拟了纳米比亚赫马地区的一个现实的 2016 年人口,该地区主要是城市地区,并引入了几个现实的过时程度(超过 15 年)和贫民窟、非贫民窟和农村地区的不准确程度。我们按普查和行政区边界对合成人口进行汇总(模仿人口普查数据),从而使用 WorldPop-Global-Unconstrained 网格化人口方法生成 32 个典型的 LMIC 环境的网格化人口数据集。我们使用原始合成人口作为参考,评估这些网格化人口数据集的单元级准确性。在我们的模拟中,我们发现了较大的单元级误差,特别是在贫民窟单元中。这些误差是由模型训练前在大面积单元中对人口密度进行平均化造成的。输入数据的年龄、准确性和汇总也在这些误差中起作用。我们建议通常将更精细的尺度训练数据纳入网格化人口模型中,特别是 WorldPop-Global-Unconstrained(例如,来自常规家庭调查或贫民窟社区人口普查),并使用新的建筑物足迹数据集作为协变量来提高单元级精度(一些新的 WorldPop-Global-Constrained 数据集已采用此方法)。在评估网格化人口数据集的准确性时,重要的是要使用与数据应用更一致的空间尺度,特别是如果要将其用于监测城市邻里尺度的关键发展指标的话。