Rajamani Kumar T, Rani Priya, Siebert Hanna, ElagiriRamalingam Rajkumar, Heinrich Mattias P
Philips Research, Bangalore, India.
Applied Artificial Intelligence Institute, Deakin University, Burwood, VIC 3125 Australia.
Signal Image Video Process. 2023;17(4):981-989. doi: 10.1007/s11760-022-02302-3. Epub 2022 Jul 25.
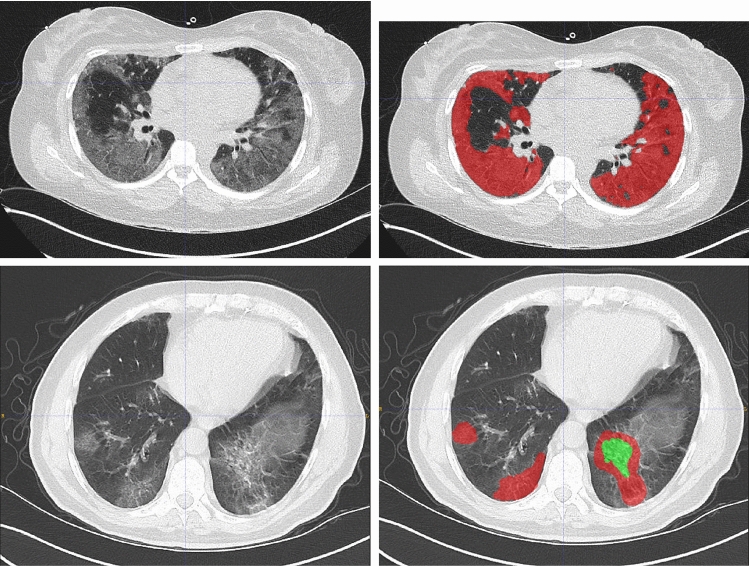
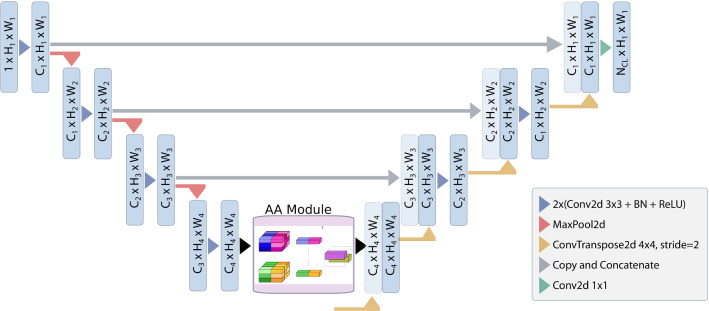
Deep learning-based image segmentation models rely strongly on capturing sufficient spatial context without requiring complex models that are hard to train with limited labeled data. For COVID-19 infection segmentation on CT images, training data are currently scarce. Attention models, in particular the most recent self-attention methods, have shown to help gather contextual information within deep networks and benefit semantic segmentation tasks. The recent attention-augmented convolution model aims to capture long range interactions by concatenating self-attention and convolution feature maps. This work proposes a novel attention-augmented convolution U-Net (AA-U-Net) that enables a more accurate spatial aggregation of contextual information by integrating attention-augmented convolution in the bottleneck of an encoder-decoder segmentation architecture. A deep segmentation network (U-Net) with this attention mechanism significantly improves the performance of semantic segmentation tasks on challenging COVID-19 lesion segmentation. The validation experiments show that the performance gain of the attention-augmented U-Net comes from their ability to capture dynamic and precise (wider) attention context. The AA-U-Net achieves Dice scores of 72.3% and 61.4% for ground-glass opacity and consolidation lesions for COVID-19 segmentation and improves the accuracy by 4.2% points against a baseline U-Net and 3.09% points compared to a baseline U-Net with matched parameters.
The online version contains supplementary material available at 10.1007/s11760-022-02302-3.
基于深度学习的图像分割模型在不依赖难以用有限标注数据进行训练的复杂模型的情况下,强烈依赖于捕获足够的空间上下文信息。对于CT图像上的新冠肺炎感染分割,目前训练数据稀缺。注意力模型,特别是最新的自注意力方法,已被证明有助于在深度网络中收集上下文信息,并有益于语义分割任务。最近的注意力增强卷积模型旨在通过拼接自注意力和卷积特征图来捕获长距离交互。这项工作提出了一种新颖的注意力增强卷积U-Net(AA-U-Net),通过在编码器-解码器分割架构的瓶颈中集成注意力增强卷积,实现上下文信息更准确的空间聚合。具有这种注意力机制的深度分割网络(U-Net)在具有挑战性的新冠肺炎病变分割上显著提高了语义分割任务的性能。验证实验表明,注意力增强U-Net的性能提升来自于其捕获动态和精确(更广泛)注意力上下文的能力。对于新冠肺炎分割,AA-U-Net在磨玻璃影和实变病变上的Dice分数分别达到72.3%和61.4%,相对于基线U-Net提高了4.2个百分点,相对于具有匹配参数的基线U-Net提高了3.09个百分点。
在线版本包含可在10.1007/s11760-022-02302-3获取的补充材料。