Serouart Mario, Madec Simon, David Etienne, Velumani Kaaviya, Lopez Lozano Raul, Weiss Marie, Baret Frédéric
Arvalis, Institut du végétal, 228, route de l'aérodrome - CS 40509, 84914 Avignon Cedex 9, France.
INRAE, Avignon Université, UMR EMMAH, UMT CAPTE, 228, route de l'aérodrome - CS 40509, 84914 Avignon Cedex 9, France.
Plant Phenomics. 2022 Oct 11;2022:9803570. doi: 10.34133/2022/9803570. eCollection 2022.
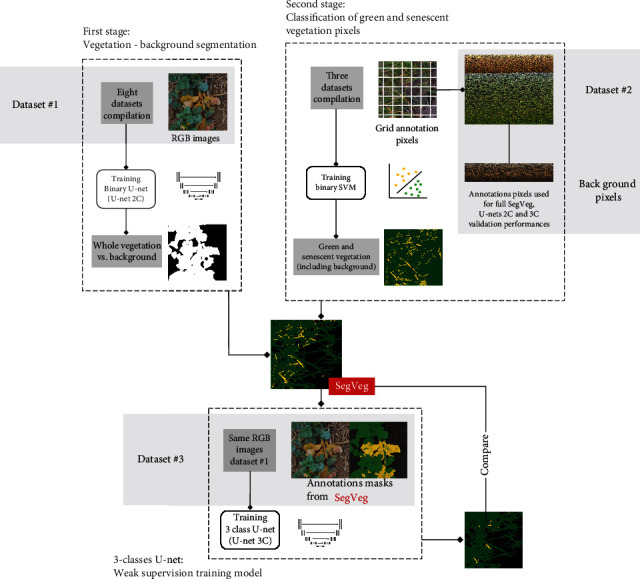
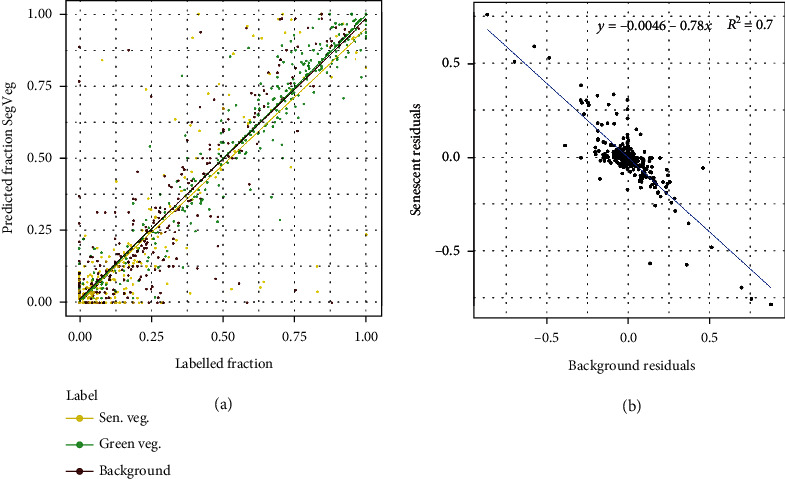
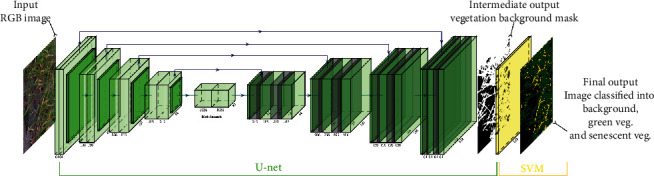
Pixel segmentation of high-resolution RGB images into chlorophyll-active or nonactive vegetation classes is a first step often required before estimating key traits of interest. We have developed the SegVeg approach for semantic segmentation of RGB images into three classes (background, green, and senescent vegetation). This is achieved in two steps: A U-net model is first trained on a very large dataset to separate whole vegetation from background. The green and senescent vegetation pixels are then separated using SVM, a shallow machine learning technique, trained over a selection of pixels extracted from images. The performances of the SegVeg approach is then compared to a 3-class U-net model trained using weak supervision over RGB images segmented with SegVeg as groundtruth masks. Results show that the SegVeg approach allows to segment accurately the three classes. However, some confusion is observed mainly between the background and senescent vegetation, particularly over the dark and bright regions of the images. The U-net model achieves similar performances, with slight degradation over the green vegetation: the SVM pixel-based approach provides more precise delineation of the green and senescent patches as compared to the convolutional nature of U-net. The use of the components of several color spaces allows to better classify the vegetation pixels into green and senescent. Finally, the models are used to predict the fraction of three classes over whole images or regularly spaced grid-pixels. Results show that green fraction is very well estimated ( = 0.94) by the SegVeg model, while the senescent and background fractions show slightly degraded performances ( = 0.70 and 0.73, respectively) with a mean 95% confidence error interval of 2.7% and 2.1% for the senescent vegetation and background, versus 1% for green vegetation. We have made SegVeg publicly available as a ready-to-use script and model, along with the entire annotated grid-pixels dataset. We thus hope to render segmentation accessible to a broad audience by requiring neither manual annotation nor knowledge or, at least, offering a pretrained model for more specific use.
将高分辨率RGB图像像素分割为叶绿素活性或非活性植被类别,是估计感兴趣的关键特征之前通常需要的第一步。我们开发了SegVeg方法,用于将RGB图像语义分割为三类(背景、绿色和衰老植被)。这分两步实现:首先在一个非常大的数据集上训练一个U-net模型,以将整个植被与背景分离。然后使用支持向量机(SVM),一种浅层机器学习技术,对从图像中提取的选定像素进行训练,来分离绿色和衰老植被像素。然后将SegVeg方法的性能与使用弱监督在以SegVeg分割的RGB图像作为地面真值掩码上训练的3类U-net模型进行比较。结果表明,SegVeg方法能够准确地分割这三类。然而,主要在背景和衰老植被之间观察到一些混淆,特别是在图像的暗区和亮区。U-net模型实现了类似的性能,在绿色植被上略有下降:与U-net的卷积性质相比,基于SVM像素的方法能够更精确地描绘绿色和衰老斑块。使用多个颜色空间的组件可以更好地将植被像素分类为绿色和衰老。最后,这些模型用于预测整个图像或规则间隔网格像素上三类的比例。结果表明,SegVeg模型对绿色比例的估计非常好(R = 0.94),而衰老和背景比例的性能略有下降(分别为R = 0.70和0.73),衰老植被和背景的平均95%置信误差区间分别为2.7%和2.1%,而绿色植被为1%。我们已将SegVeg作为一个即用型脚本和模型公开提供,以及整个带注释的网格像素数据集。因此,我们希望通过既不需要手动注释也不需要知识,或者至少提供一个预训练模型以供更具体的使用,使分割对广大受众来说易于实现。