Department of Biostatistics and Medical Informatics, Faculty of Medicine, Inonu University, 44280, Malatya, Turkey.
Software Engineering Department, King Hussein School for Computing Sciences, Amman, Jordan.
Comput Biol Med. 2023 Mar;154:106619. doi: 10.1016/j.compbiomed.2023.106619. Epub 2023 Feb 1.
COVID-19 has revealed the need for fast and reliable methods to assist clinicians in diagnosing the disease. This article presents a model that applies explainable artificial intelligence (XAI) methods based on machine learning techniques on COVID-19 metagenomic next-generation sequencing (mNGS) samples.
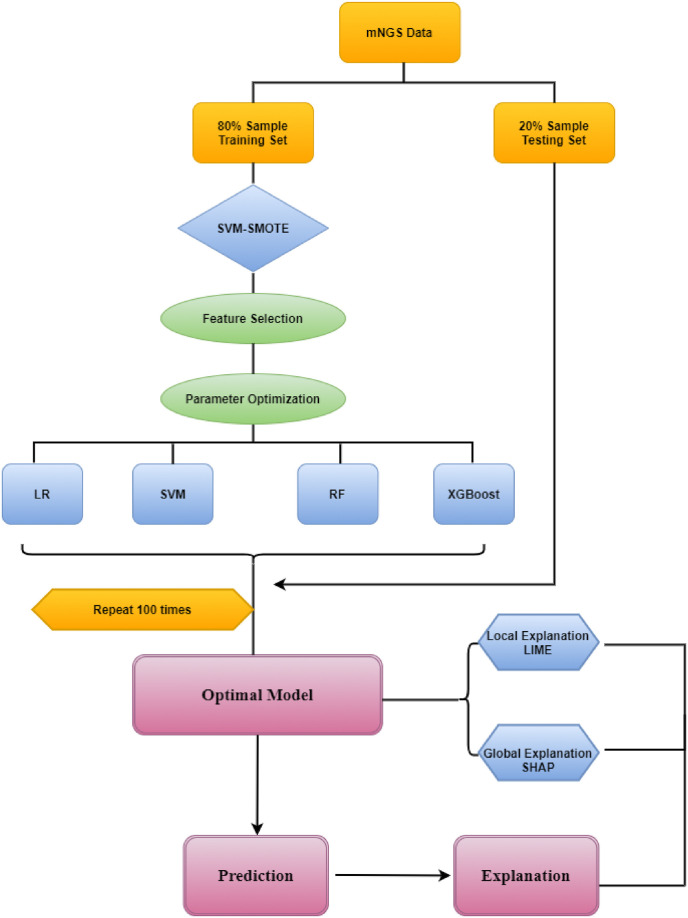
In the data set used in the study, there are 15,979 gene expressions of 234 patients with COVID-19 negative 141 (60.3%) and COVID-19 positive 93 (39.7%). The least absolute shrinkage and selection operator (LASSO) method was applied to select genes associated with COVID-19. Support Vector Machine - Synthetic Minority Oversampling Technique (SVM-SMOTE) method was used to handle the class imbalance problem. Logistics regression (LR), SVM, random forest (RF), and extreme gradient boosting (XGBoost) methods were constructed to predict COVID-19. An explainable approach based on local interpretable model-agnostic explanations (LIME) and SHAPley Additive exPlanations (SHAP) methods was applied to determine COVID-19- associated biomarker candidate genes and improve the final model's interpretability.
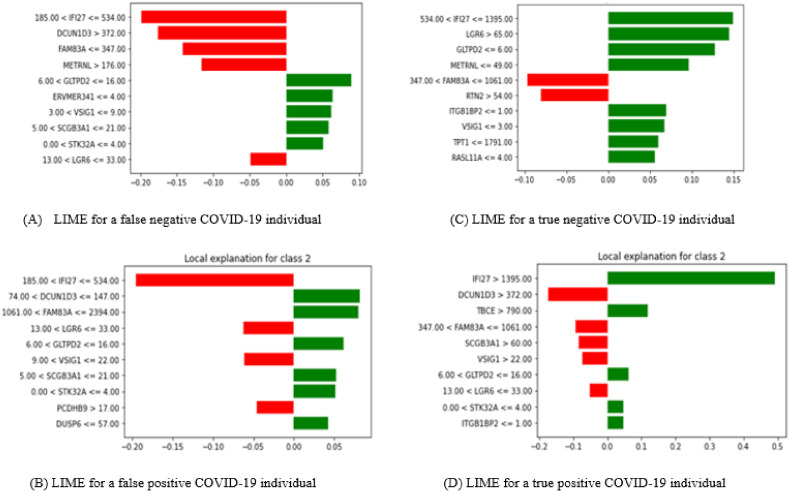
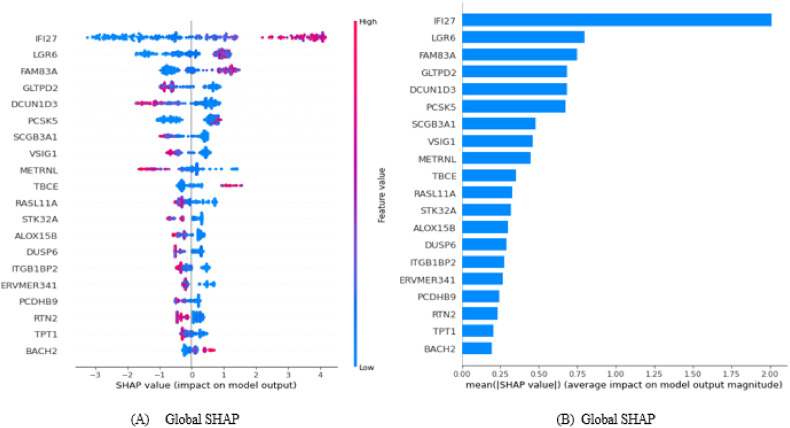
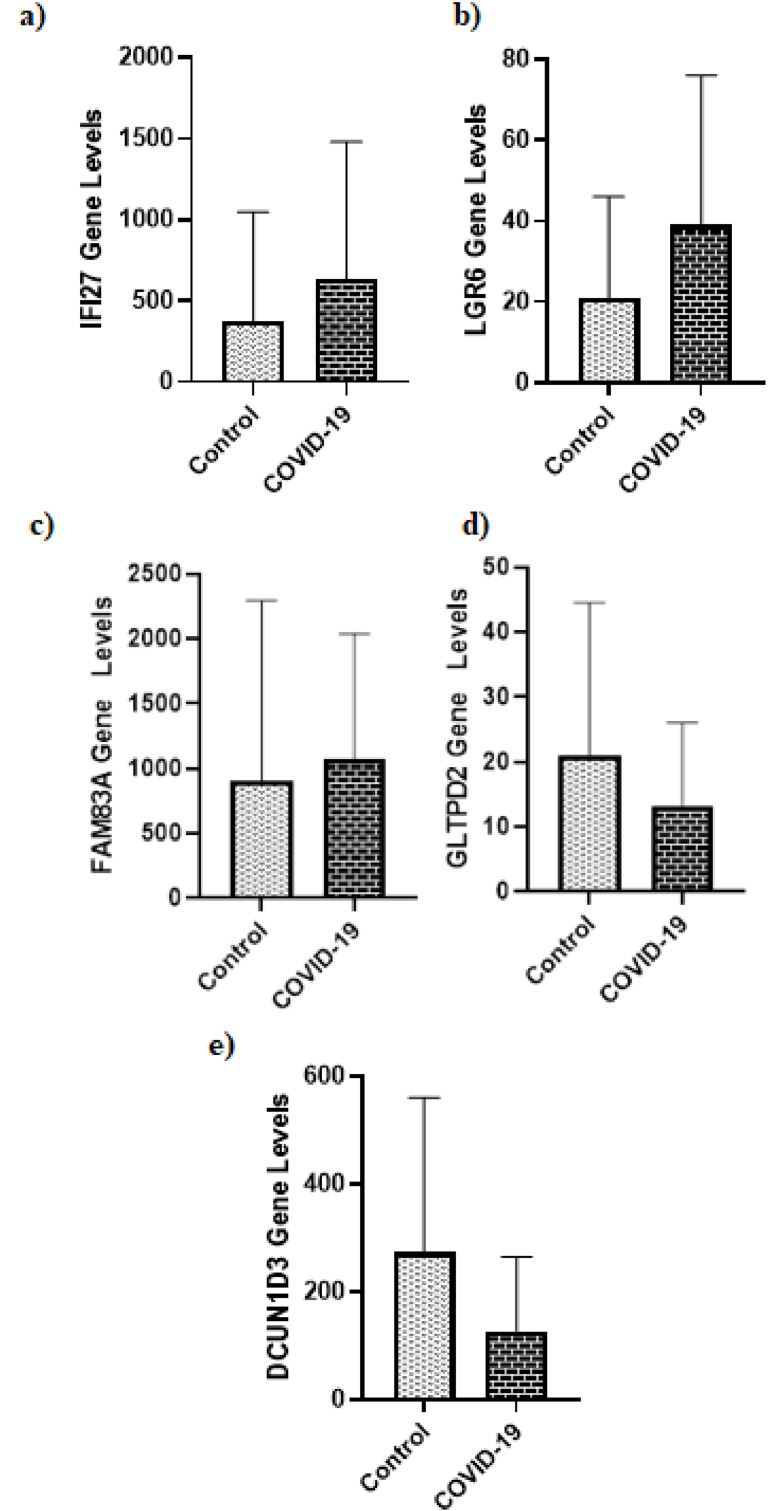
For the diagnosis of COVID-19, the XGBoost (accuracy: 0.930) model outperformed the RF (accuracy: 0.912), SVM (accuracy: 0.877), and LR (accuracy: 0.912) models. As a result of the SHAP, the three most important genes associated with COVID-19 were IFI27, LGR6, and FAM83A. The results of LIME showed that especially the high level of IFI27 gene expression contributed to increasing the probability of positive class.
The proposed model (XGBoost) was able to predict COVID-19 successfully. The results show that machine learning combined with LIME and SHAP can explain the biomarker prediction for COVID-19 and provide clinicians with an intuitive understanding and interpretability of the impact of risk factors in the model.
COVID-19 凸显了需要快速可靠的方法来帮助临床医生诊断疾病。本文提出了一种模型,该模型应用基于机器学习技术的可解释人工智能 (XAI) 方法对 COVID-19 宏基因组下一代测序 (mNGS) 样本进行分析。
在研究中使用的数据集包含 234 名 COVID-19 患者的 15979 个基因表达,其中 COVID-19 阴性患者 141 例(60.3%),COVID-19 阳性患者 93 例(39.7%)。应用最小绝对收缩和选择算子 (LASSO) 方法选择与 COVID-19 相关的基因。应用支持向量机-合成少数过采样技术 (SVM-SMOTE) 方法处理类别不平衡问题。构建逻辑回归 (LR)、支持向量机 (SVM)、随机森林 (RF) 和极端梯度提升 (XGBoost) 方法来预测 COVID-19。应用基于局部可解释模型无关解释 (LIME) 和 SHAPley 加性解释 (SHAP) 方法的可解释方法来确定与 COVID-19 相关的生物标志物候选基因,并提高最终模型的可解释性。
对于 COVID-19 的诊断,XGBoost(准确性:0.930)模型优于 RF(准确性:0.912)、SVM(准确性:0.877)和 LR(准确性:0.912)模型。根据 SHAP 的结果,与 COVID-19 相关的三个最重要的基因是 IFI27、LGR6 和 FAM83A。LIME 的结果表明,IFI27 基因表达水平较高尤其有助于增加阳性类别的概率。
所提出的模型(XGBoost)能够成功预测 COVID-19。结果表明,机器学习与 LIME 和 SHAP 相结合可以解释 COVID-19 的生物标志物预测,并为临床医生提供对模型中风险因素影响的直观理解和可解释性。