Computer Science Program, Computer, Electrical and Mathematical Sciences and Engineering Division (CEMSE), King Abdullah University of Science and Technology (KAUST), Thuwal, Saudi Arabia.
Computational Bioscience Research Center (CBRC), King Abdullah University of Science and Technology (KAUST), Thuwal, Saudi Arabia.
Sci Rep. 2023 Mar 27;13(1):4979. doi: 10.1038/s41598-023-30904-5.
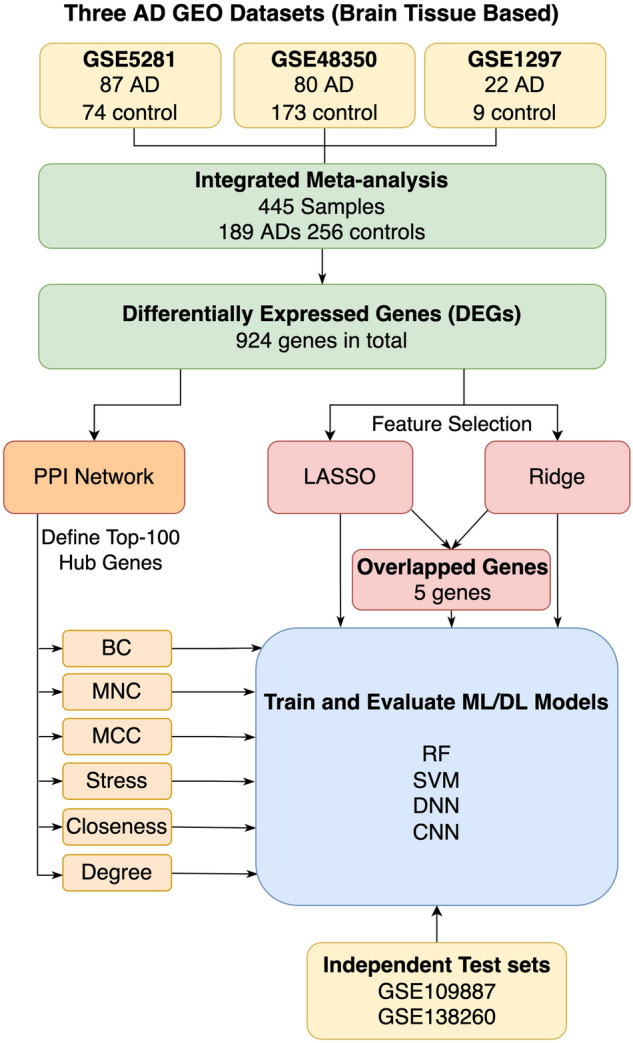
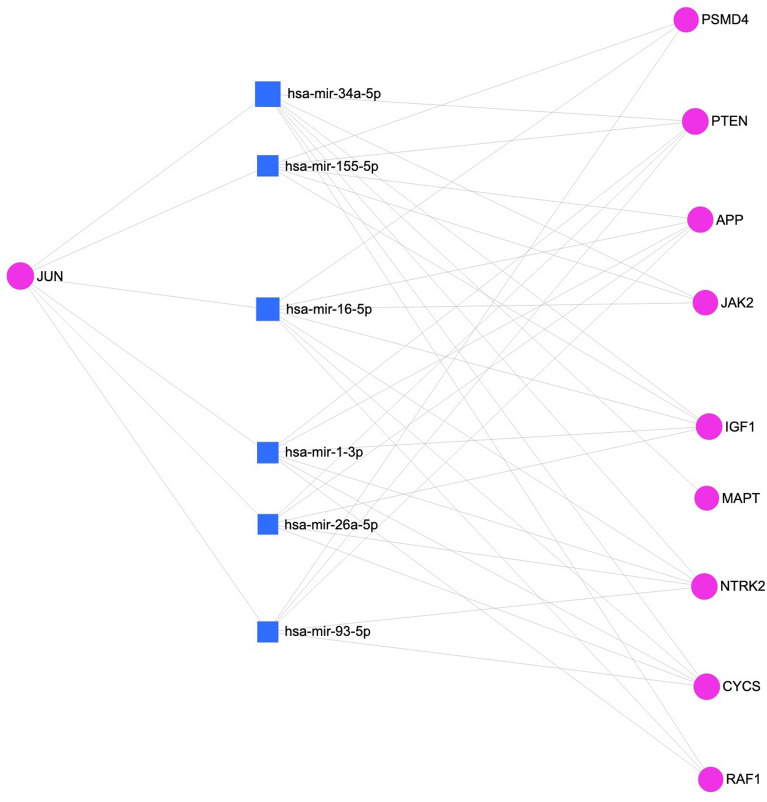
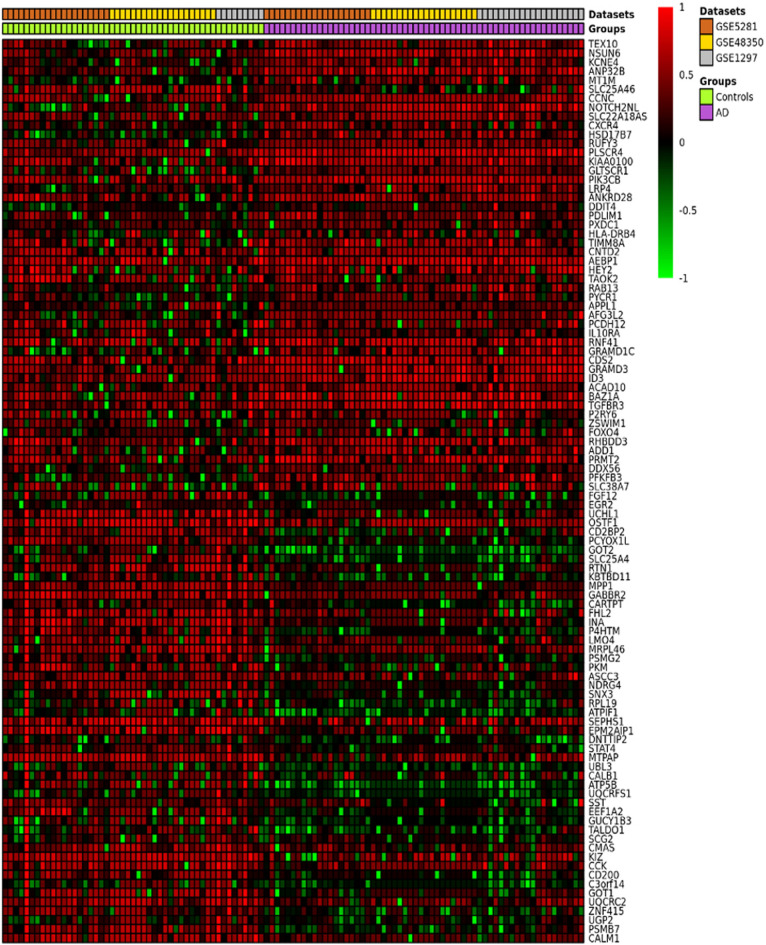
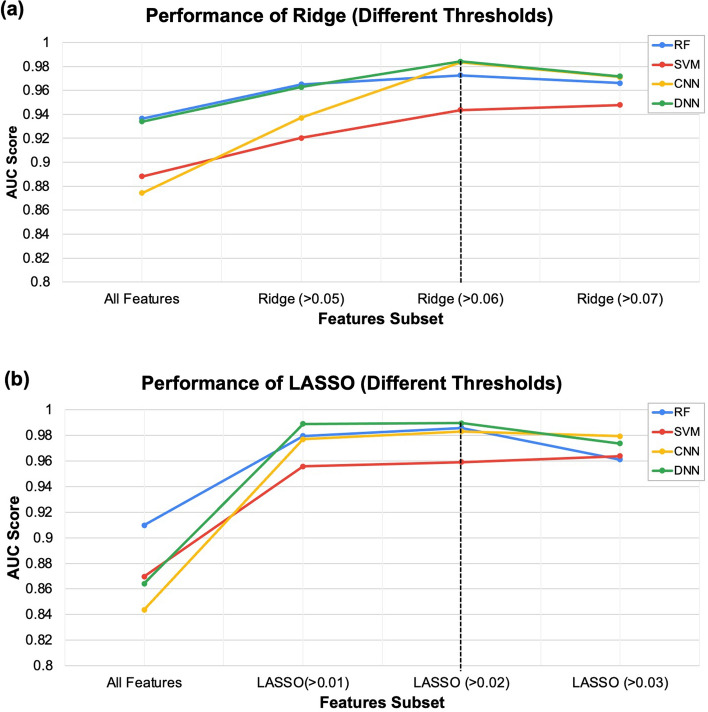
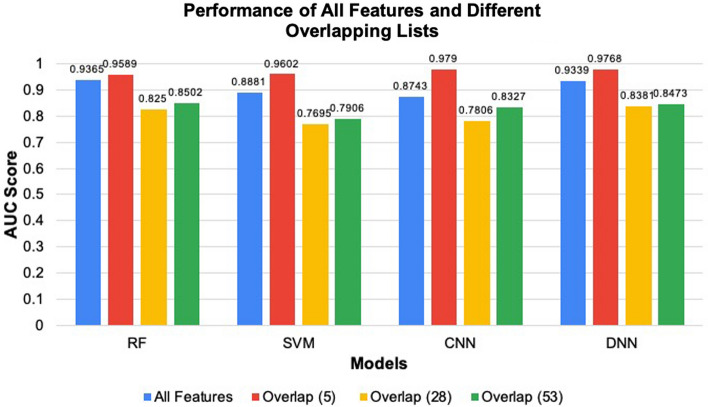
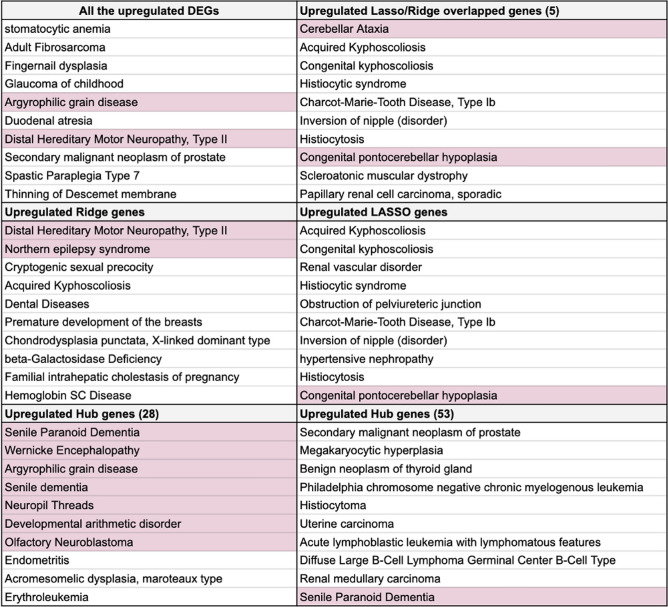
We still do not have an effective treatment for Alzheimer's disease (AD) despite it being the most common cause of dementia and impaired cognitive function. Thus, research endeavors are directed toward identifying AD biomarkers and targets. In this regard, we designed a computational method that exploits multiple hub gene ranking methods and feature selection methods with machine learning and deep learning to identify biomarkers and targets. First, we used three AD gene expression datasets to identify 1/ hub genes based on six ranking algorithms (Degree, Maximum Neighborhood Component (MNC), Maximal Clique Centrality (MCC), Betweenness Centrality (BC), Closeness Centrality, and Stress Centrality), 2/ gene subsets based on two feature selection methods (LASSO and Ridge). Then, we developed machine learning and deep learning models to determine the gene subset that best distinguishes AD samples from the healthy controls. This work shows that feature selection methods achieve better prediction performances than the hub gene sets. Beyond this, the five genes identified by both feature selection methods (LASSO and Ridge algorithms) achieved an AUC = 0.979. We further show that 70% of the upregulated hub genes (among the 28 overlapping hub genes) are AD targets based on a literature review and six miRNA (hsa-mir-16-5p, hsa-mir-34a-5p, hsa-mir-1-3p, hsa-mir-26a-5p, hsa-mir-93-5p, hsa-mir-155-5p) and one transcription factor, JUN, are associated with the upregulated hub genes. Furthermore, since 2020, four of the six microRNA were also shown to be potential AD targets. To our knowledge, this is the first work showing that such a small number of genes can distinguish AD samples from healthy controls with high accuracy and that overlapping upregulated hub genes can narrow the search space for potential novel targets.
尽管阿尔茨海默病(AD)是痴呆和认知功能障碍的最常见原因,但我们仍然没有有效的治疗方法。因此,研究工作旨在确定 AD 的生物标志物和靶点。在这方面,我们设计了一种计算方法,该方法利用了多种基于机器学习和深度学习的核心基因排名方法和特征选择方法来识别生物标志物和靶点。首先,我们使用三个 AD 基因表达数据集,基于六种排名算法(Degree、最大邻域成分(MNC)、最大团中心度(MCC)、介数中心度(BC)、接近中心度和压力中心度),确定了 1/ 核心基因;基于两种特征选择方法(LASSO 和 Ridge)确定了 2/ 基因子集。然后,我们开发了机器学习和深度学习模型,以确定最佳区分 AD 样本和健康对照的基因子集。这项工作表明,特征选择方法比核心基因集具有更好的预测性能。除此之外,两种特征选择方法(LASSO 和 Ridge 算法)确定的 5 个基因的 AUC 值为 0.979。我们进一步表明,基于文献综述和六种 miRNA(hsa-mir-16-5p、hsa-mir-34a-5p、hsa-mir-1-3p、hsa-mir-26a-5p、hsa-mir-93-5p、hsa-mir-155-5p)和一个转录因子 JUN,上调的核心基因中有 70%是 AD 靶点。此外,自 2020 年以来,其中 4 个 microRNA 也被证明是潜在的 AD 靶点。据我们所知,这是第一项表明如此少量的基因可以以高精度区分 AD 样本和健康对照的工作,并且重叠的上调核心基因可以缩小潜在新靶点的搜索空间。