Weinreb Caleb, Pearl Jonah, Lin Sherry, Osman Mohammed Abdal Monium, Zhang Libby, Annapragada Sidharth, Conlin Eli, Hoffman Red, Makowska Sofia, Gillis Winthrop F, Jay Maya, Ye Shaokai, Mathis Alexander, Mathis Mackenzie Weygandt, Pereira Talmo, Linderman Scott W, Datta Sandeep Robert
Department of Neurobiology, Harvard Medical School, Boston, MA, USA.
Department of Electrical Engineering, Stanford University, Stanford, CA, USA.
bioRxiv. 2023 Dec 23:2023.03.16.532307. doi: 10.1101/2023.03.16.532307.
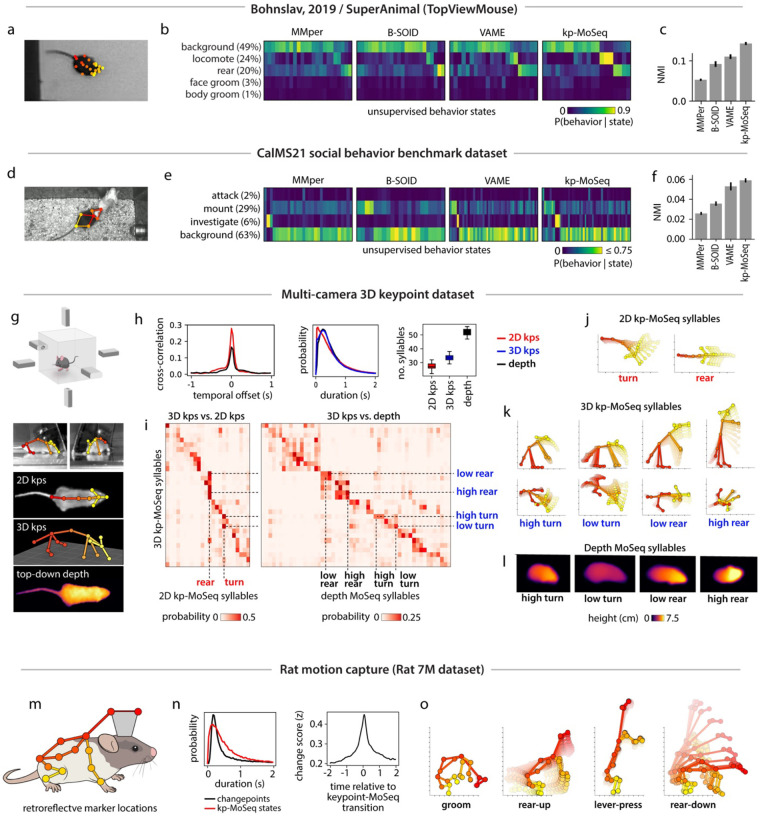
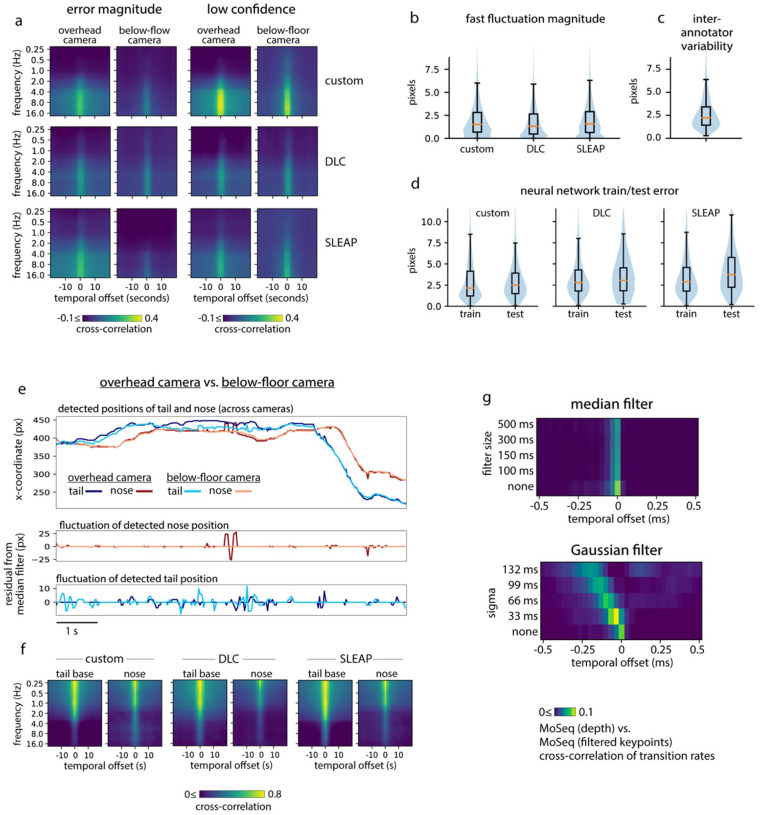
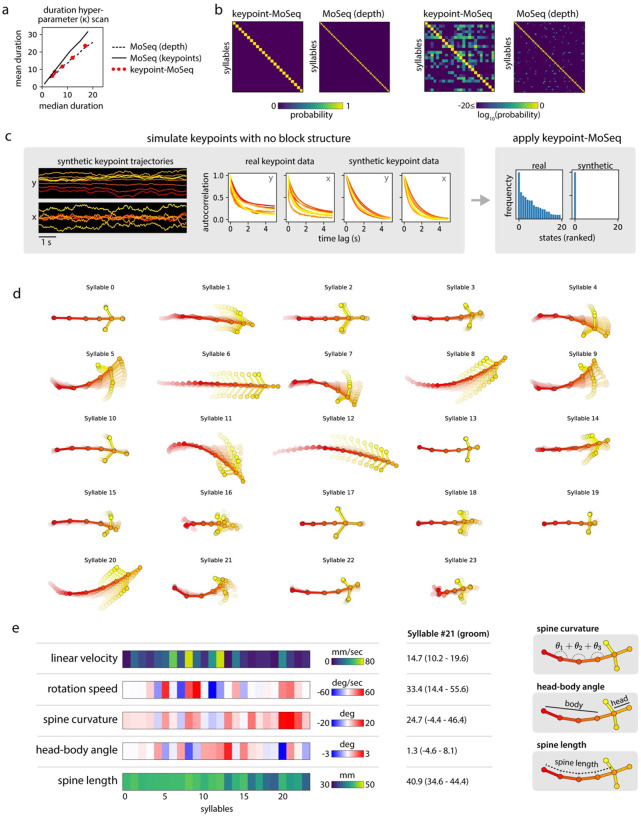
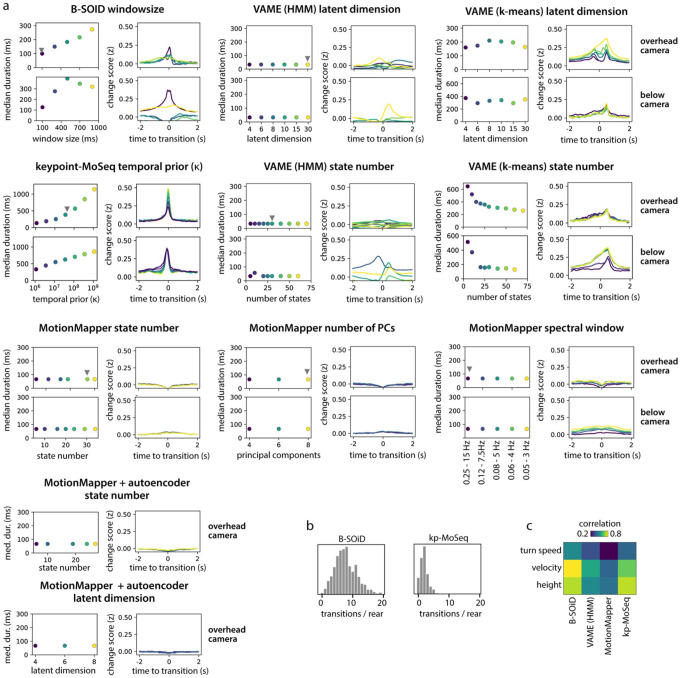
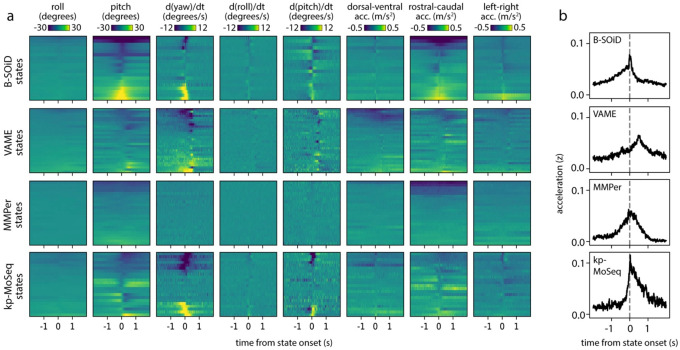
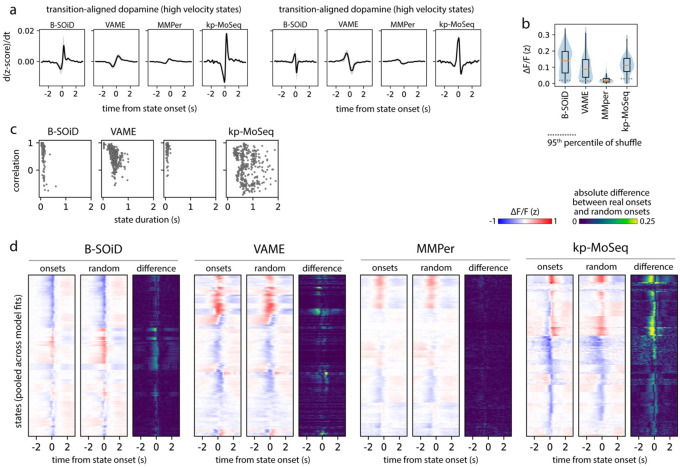
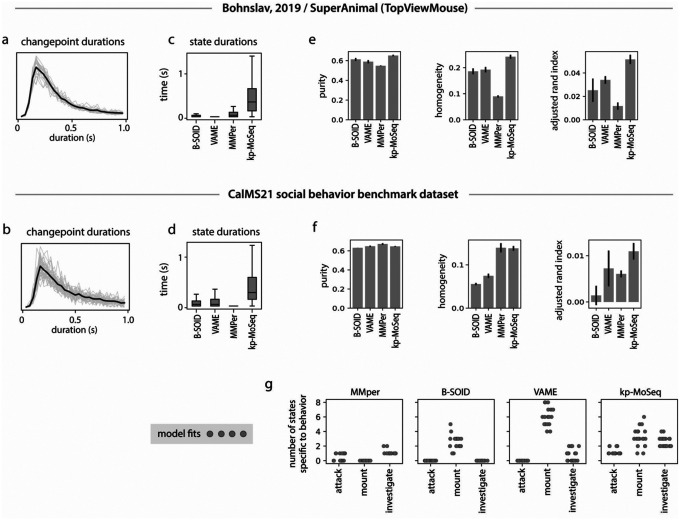
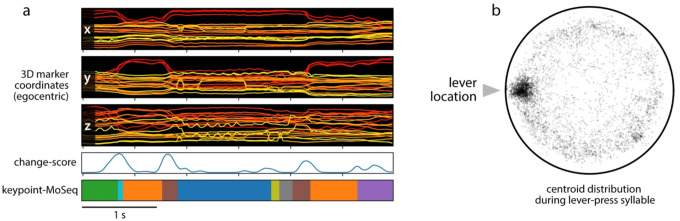
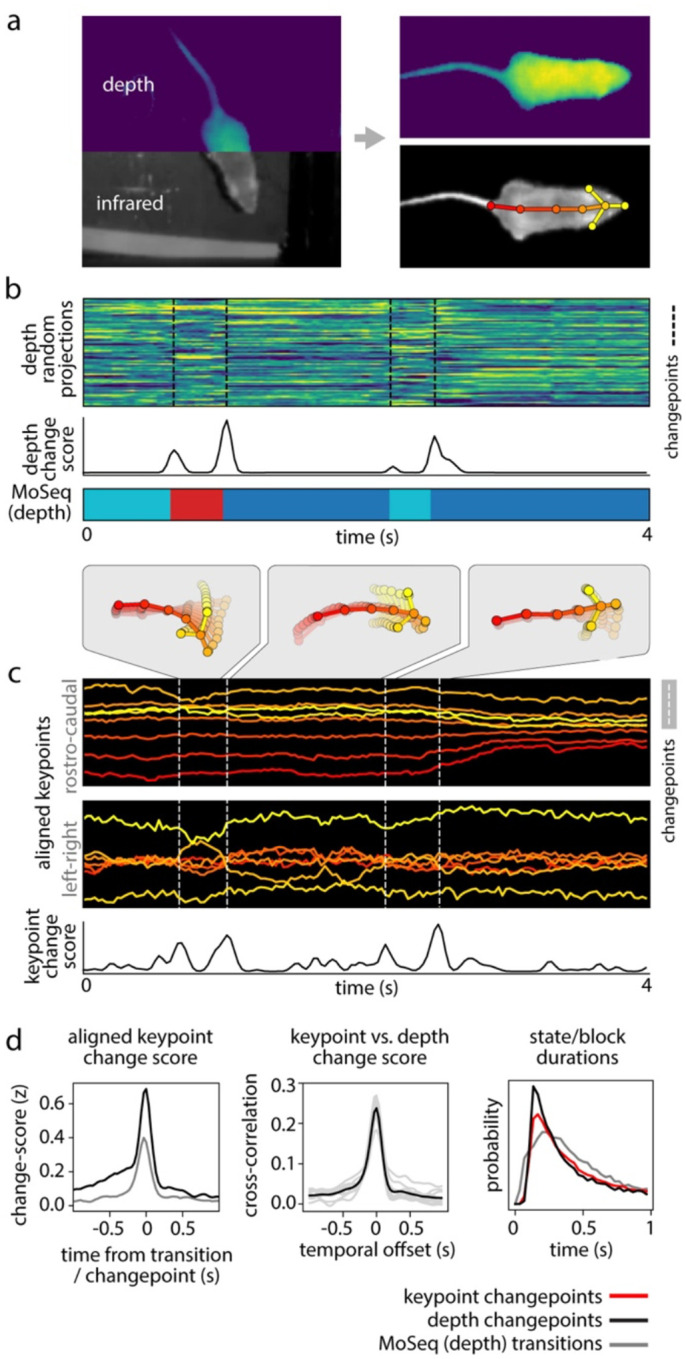
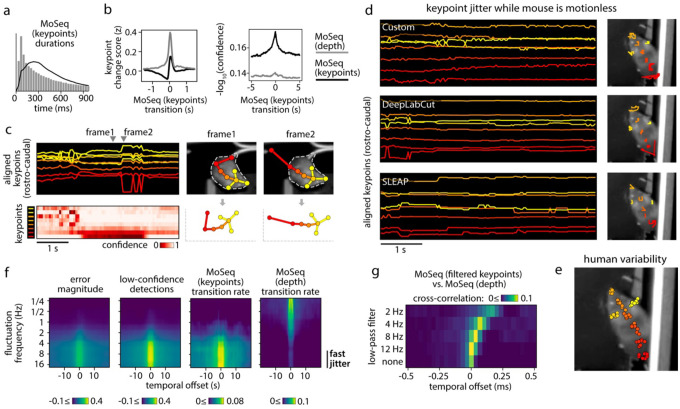
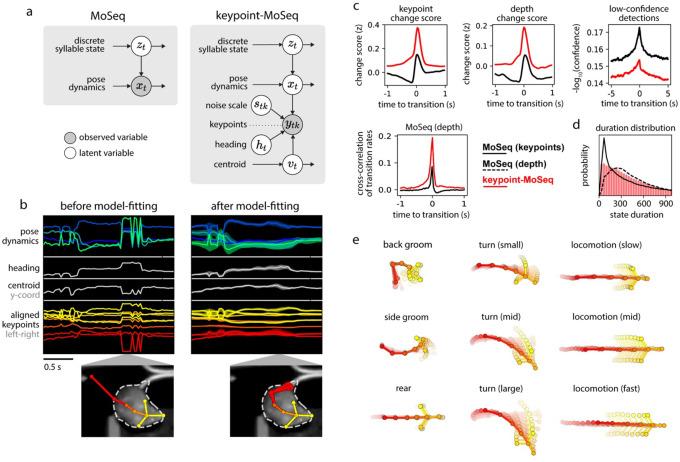
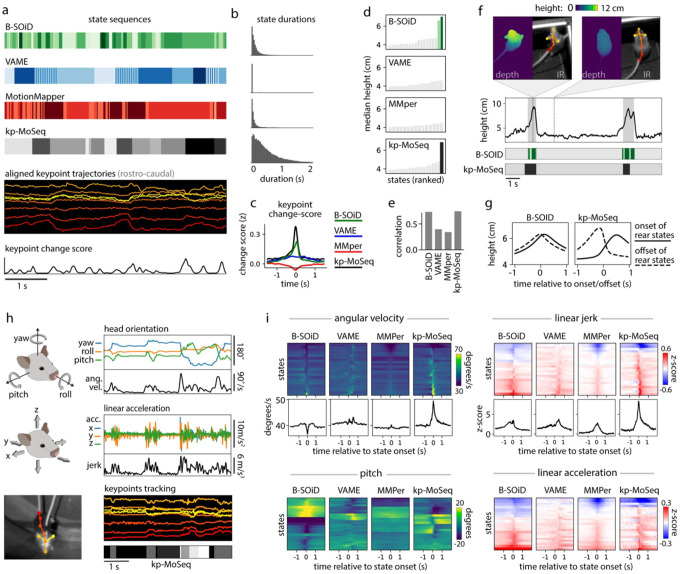
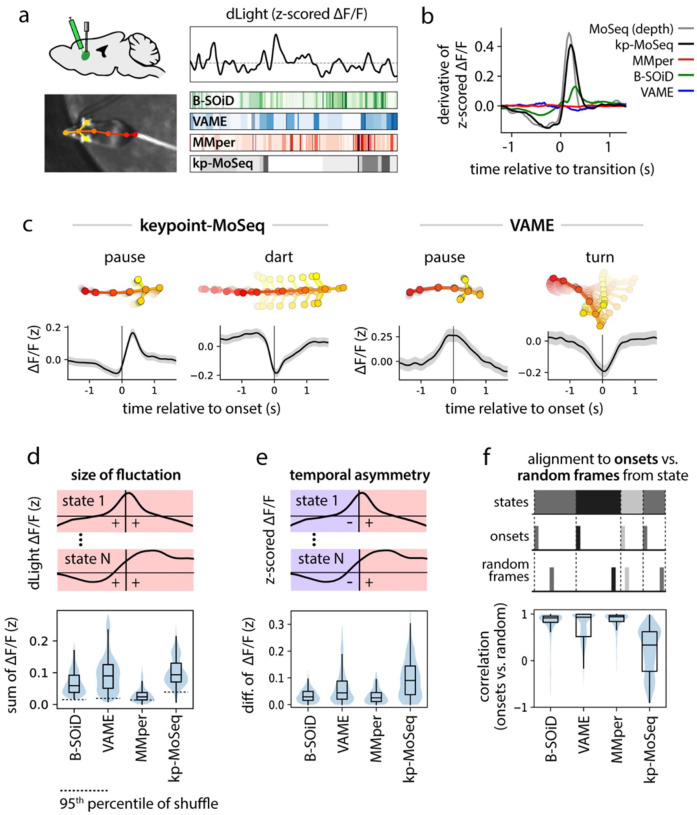
Keypoint tracking algorithms have revolutionized the analysis of animal behavior, enabling investigators to flexibly quantify behavioral dynamics from conventional video recordings obtained in a wide variety of settings. However, it remains unclear how to parse continuous keypoint data into the modules out of which behavior is organized. This challenge is particularly acute because keypoint data is susceptible to high frequency jitter that clustering algorithms can mistake for transitions between behavioral modules. Here we present keypoint-MoSeq, a machine learning-based platform for identifying behavioral modules ("syllables") from keypoint data without human supervision. Keypoint-MoSeq uses a generative model to distinguish keypoint noise from behavior, enabling it to effectively identify syllables whose boundaries correspond to natural sub-second discontinuities inherent to mouse behavior. Keypoint-MoSeq outperforms commonly used alternative clustering methods at identifying these transitions, at capturing correlations between neural activity and behavior, and at classifying either solitary or social behaviors in accordance with human annotations. Keypoint-MoSeq therefore renders behavioral syllables and grammar accessible to the many researchers who use standard video to capture animal behavior.
关键点跟踪算法彻底改变了动物行为分析方式,使研究人员能够灵活地从在各种环境中获取的传统视频记录中量化行为动态。然而,目前尚不清楚如何将连续的关键点数据解析为构成行为的模块。这一挑战尤为严峻,因为关键点数据容易受到高频抖动的影响,聚类算法可能会将其误认为是行为模块之间的转换。在此,我们介绍了keypoint-MoSeq,这是一个基于机器学习的平台,用于在无需人工监督的情况下从关键点数据中识别行为模块(“音节”)。Keypoint-MoSeq使用生成模型来区分关键点噪声和行为,从而能够有效地识别其边界对应于小鼠行为固有的自然亚秒级间断的音节。在识别这些转换、捕捉神经活动与行为之间的相关性以及根据人类注释对单独或社交行为进行分类方面,Keypoint-MoSeq优于常用的替代聚类方法。因此,Keypoint-MoSeq使许多使用标准视频捕捉动物行为的研究人员能够了解行为音节和语法。