Ahmad Ahmad Ayid, Polat Huseyin
Computer Engineering Department, Gazi University, Ankara 06560, Turkey.
Information Technology Department, Kirkuk University, Kirkuk 36013, Iraq.
Diagnostics (Basel). 2023 Jul 17;13(14):2392. doi: 10.3390/diagnostics13142392.
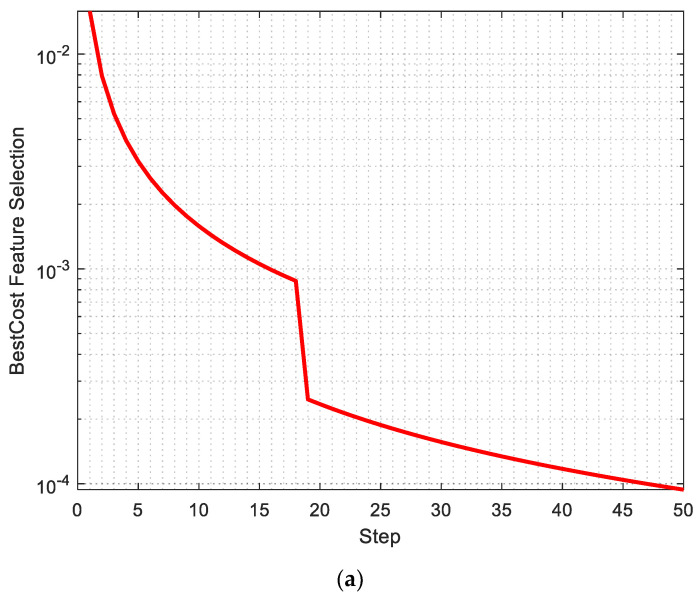
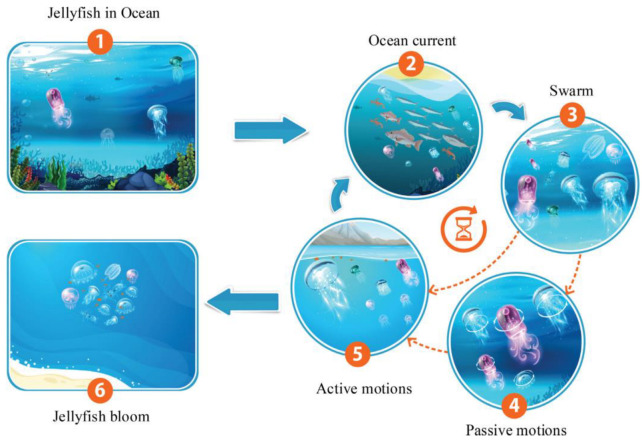
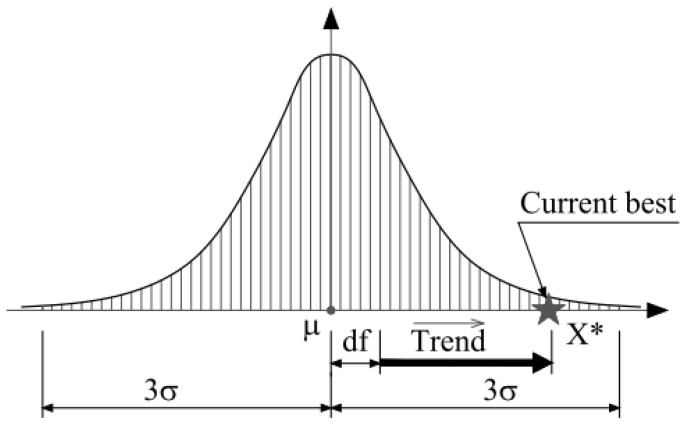
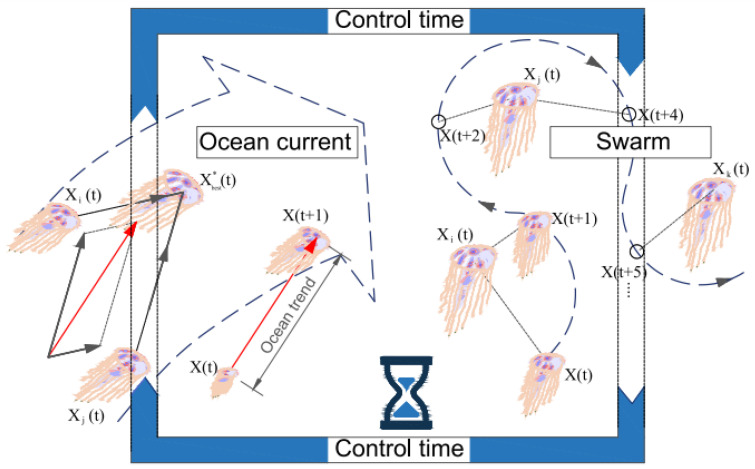
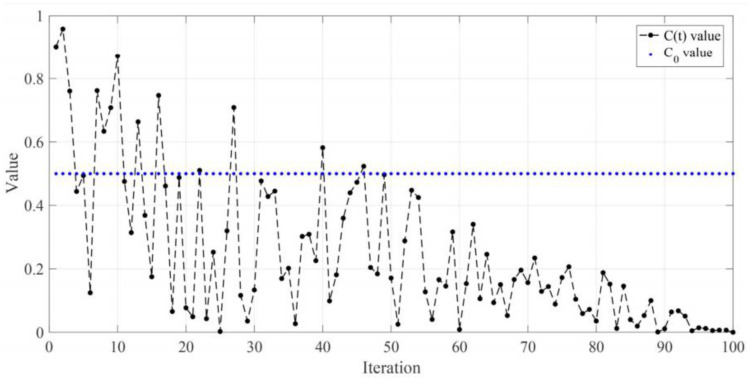
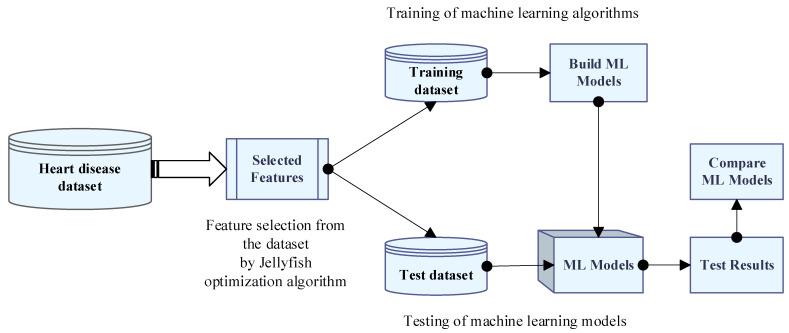
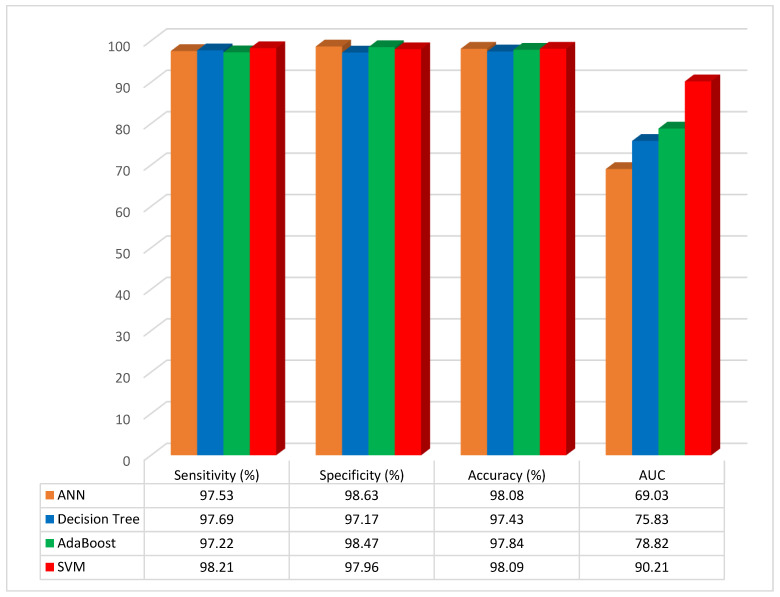
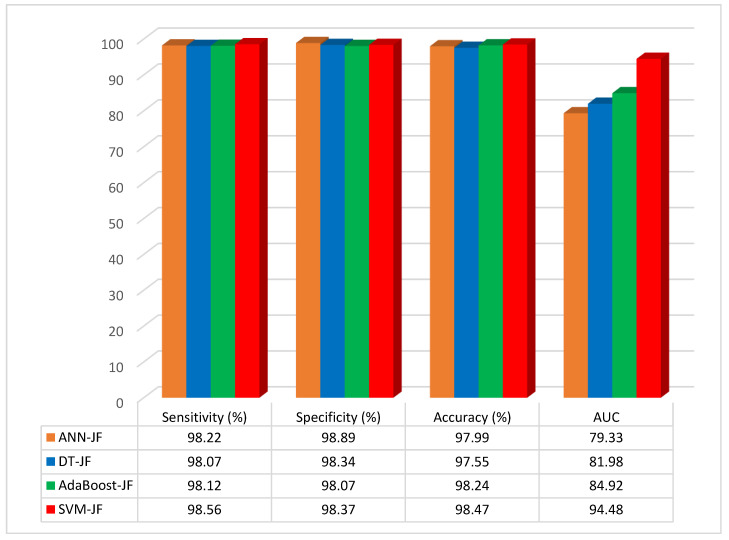
Heart disease is one of the most known and deadly diseases in the world, and many people lose their lives from this disease every year. Early detection of this disease is vital to save people's lives. Machine Learning (ML), an artificial intelligence technology, is one of the most convenient, fastest, and low-cost ways to detect disease. In this study, we aim to obtain an ML model that can predict heart disease with the highest possible performance using the Cleveland heart disease dataset. The features in the dataset used to train the model and the selection of the ML algorithm have a significant impact on the performance of the model. To avoid overfitting (due to the curse of dimensionality) due to the large number of features in the Cleveland dataset, the dataset was reduced to a lower dimensional subspace using the Jellyfish optimization algorithm. The Jellyfish algorithm has a high convergence speed and is flexible to find the best features. The models obtained by training the feature-selected dataset with different ML algorithms were tested, and their performances were compared. The highest performance was obtained for the SVM classifier model trained on the dataset with the Jellyfish algorithm, with Sensitivity, Specificity, Accuracy, and Area Under Curve of 98.56%, 98.37%, 98.47%, and 94.48%, respectively. The results show that the combination of the Jellyfish optimization algorithm and SVM classifier has the highest performance for use in heart disease prediction.
心脏病是世界上最广为人知且致命的疾病之一,每年都有许多人死于这种疾病。早期检测这种疾病对于挽救人们的生命至关重要。机器学习(ML)作为一种人工智能技术,是检测疾病最便捷、快速且低成本的方法之一。在本研究中,我们旨在使用克利夫兰心脏病数据集获得一个能够以尽可能高的性能预测心脏病的ML模型。用于训练模型的数据集中的特征以及ML算法的选择对模型的性能有重大影响。为避免由于克利夫兰数据集中特征数量众多而导致的过拟合(由于维度诅咒),使用水母优化算法将数据集降维到一个更低维度的子空间。水母算法具有很高的收敛速度,并且能够灵活地找到最佳特征。对使用不同ML算法训练特征选择后的数据集所获得的模型进行了测试,并比较了它们的性能。在使用水母算法处理的数据集上训练的支持向量机(SVM)分类器模型获得了最高性能,其灵敏度、特异性、准确率和曲线下面积分别为98.56%、98.37%、98.47%和94.48%。结果表明,水母优化算法和SVM分类器的组合在心脏病预测中具有最高性能。