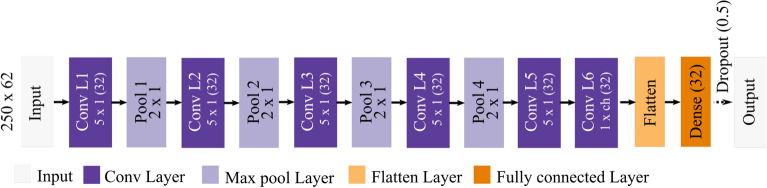
Noninvasive Brain-Machine Interface System Laboratory, Department of Electrical and Computer Engineering, University of Houston, Houston, 77204, USA.
IUCRC BRAIN, University of Houston, Houston, 77204, USA.
Sci Rep. 2023 Oct 18;13(1):17709. doi: 10.1038/s41598-023-43871-8.
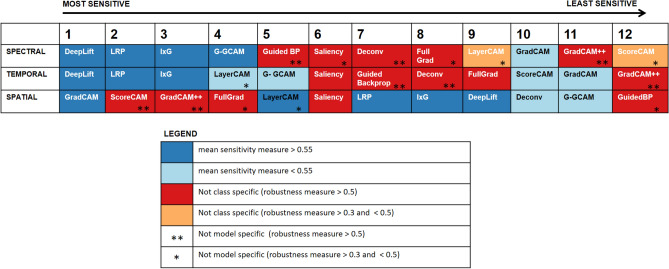
Recent advancements in machine learning and deep learning (DL) based neural decoders have significantly improved decoding capabilities using scalp electroencephalography (EEG). However, the interpretability of DL models remains an under-explored area. In this study, we compared multiple model explanation methods to identify the most suitable method for EEG and understand when some of these approaches might fail. A simulation framework was developed to evaluate the robustness and sensitivity of twelve back-propagation-based visualization methods by comparing to ground truth features. Multiple methods tested here showed reliability issues after randomizing either model weights or labels: e.g., the saliency approach, which is the most used visualization technique in EEG, was not class or model-specific. We found that DeepLift was consistently accurate as well as robust to detect the three key attributes tested here (temporal, spatial, and spectral precision). Overall, this study provides a review of model explanation methods for DL-based neural decoders and recommendations to understand when some of these methods fail and what they can capture in EEG.
近年来,基于机器学习和深度学习(DL)的神经解码器的进展显著提高了使用头皮脑电图(EEG)进行解码的能力。然而,DL 模型的可解释性仍然是一个未充分探索的领域。在这项研究中,我们比较了多种模型解释方法,以确定最适合 EEG 的方法,并了解在某些情况下这些方法可能会失败。我们开发了一个模拟框架,通过与地面真实特征进行比较,来评估基于反向传播的十二种可视化方法的稳健性和敏感性。在此测试的多种方法在随机化模型权重或标签后都显示出可靠性问题:例如,显着性方法是 EEG 中最常用的可视化技术,但它不是特定于类或模型的。我们发现 DeepLift 始终准确无误,并且能够检测到这里测试的三个关键属性(时间、空间和频谱精度)。总的来说,这项研究为基于 DL 的神经解码器的模型解释方法提供了一个综述,并为理解何时这些方法会失败以及它们可以在 EEG 中捕获哪些信息提供了建议。