Department of Computer Science, Ulm University of Applied Science, Albert-Einstein-Allee 55, 89081, Ulm, Baden-Wurttemberg, Germany.
Institute of Databases and Information Systems, Ulm University, James-Franck-Ring, 89081, Ulm, Baden-Wurttemberg, Germany.
Sci Rep. 2023 Oct 25;13(1):18299. doi: 10.1038/s41598-023-45532-2.
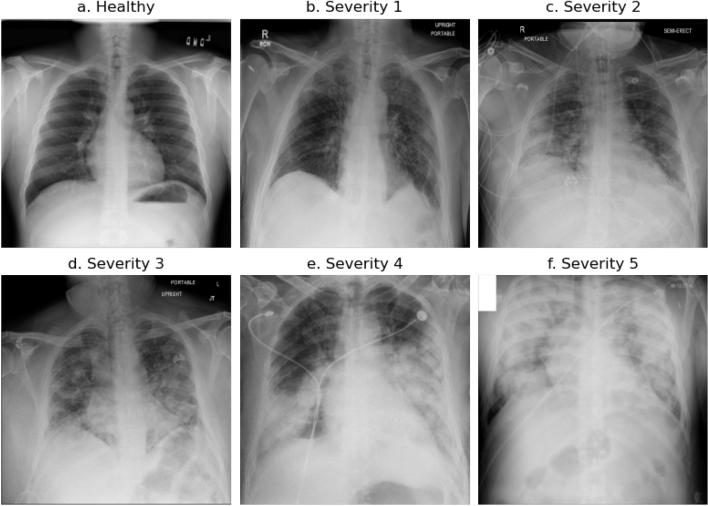
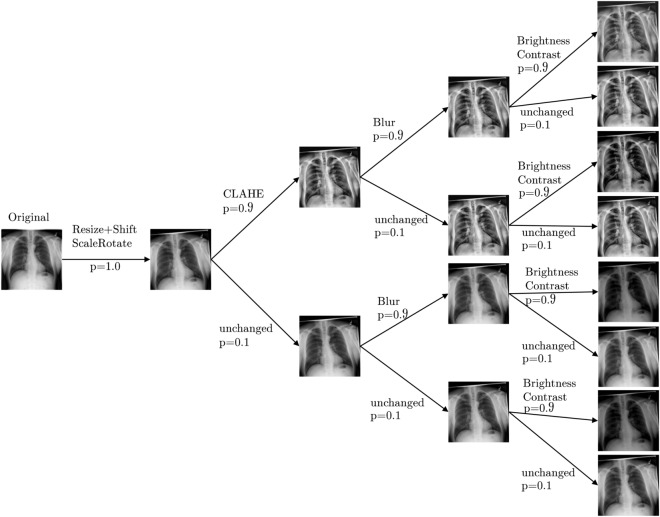
Since the beginning of the COVID-19 pandemic, many different machine learning models have been developed to detect and verify COVID-19 pneumonia based on chest X-ray images. Although promising, binary models have only limited implications for medical treatment, whereas the prediction of disease severity suggests more suitable and specific treatment options. In this study, we publish severity scores for the 2358 COVID-19 positive images in the COVIDx8B dataset, creating one of the largest collections of publicly available COVID-19 severity data. Furthermore, we train and evaluate deep learning models on the newly created dataset to provide a first benchmark for the severity classification task. One of the main challenges of this dataset is the skewed class distribution, resulting in undesirable model performance for the most severe cases. We therefore propose and examine different augmentation strategies, specifically targeting majority and minority classes. Our augmentation strategies show significant improvements in precision and recall values for the rare and most severe cases. While the models might not yet fulfill medical requirements, they serve as an appropriate starting point for further research with the proposed dataset to optimize clinical resource allocation and treatment.
自 COVID-19 大流行开始以来,已经开发出许多不同的机器学习模型,以便基于胸部 X 射线图像来检测和验证 COVID-19 肺炎。尽管有希望,但二进制模型对医疗的影响有限,而对疾病严重程度的预测则表明了更合适和具体的治疗选择。在这项研究中,我们发布了 COVIDx8B 数据集中 2358 张 COVID-19 阳性图像的严重程度评分,创建了最大的 COVID-19 严重程度公开数据之一。此外,我们在新创建的数据集上训练和评估深度学习模型,为严重程度分类任务提供了第一个基准。该数据集的主要挑战之一是类分布不平衡,导致对最严重病例的模型性能不理想。因此,我们提出并检查了不同的扩充策略,特别是针对多数类和少数类。我们的扩充策略显著提高了稀有和最严重病例的精度和召回率值。虽然这些模型可能还不符合医疗要求,但它们为使用所提出的数据集进行进一步研究提供了适当的起点,以优化临床资源分配和治疗。