Institute for Medical Informatics, Statistics and Documentation, Medical University of Graz, Graz, Austria.
CBmed GmbH - Center for Biomarker Research in Medicine, Graz, Austria.
BMC Med Inform Decis Mak. 2024 Jan 31;24(1):29. doi: 10.1186/s12911-024-02425-2.
Oxygen saturation, a key indicator of COVID-19 severity, poses challenges, especially in cases of silent hypoxemia. Electronic health records (EHRs) often contain supplemental oxygen information within clinical narratives. Streamlining patient identification based on oxygen levels is crucial for COVID-19 research, underscoring the need for automated classifiers in discharge summaries to ease the manual review burden on physicians.
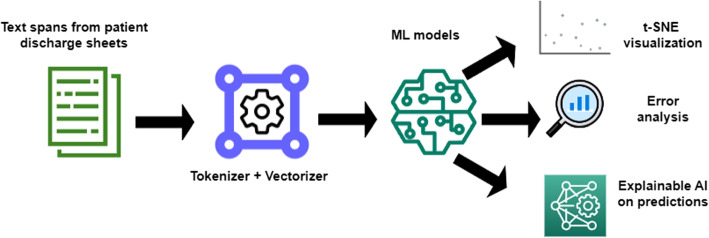
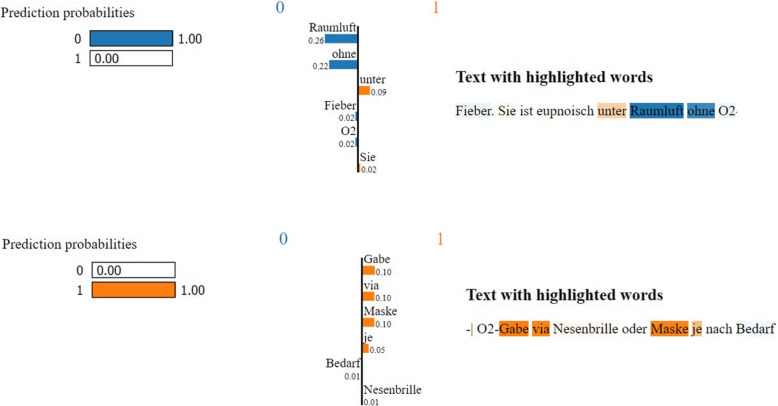
We analysed text lines extracted from anonymised COVID-19 patient discharge summaries in German to perform a binary classification task, differentiating patients who received oxygen supplementation and those who did not. Various machine learning (ML) algorithms, including classical ML to deep learning (DL) models, were compared. Classifier decisions were explained using Local Interpretable Model-agnostic Explanations (LIME), which visualize the model decisions.
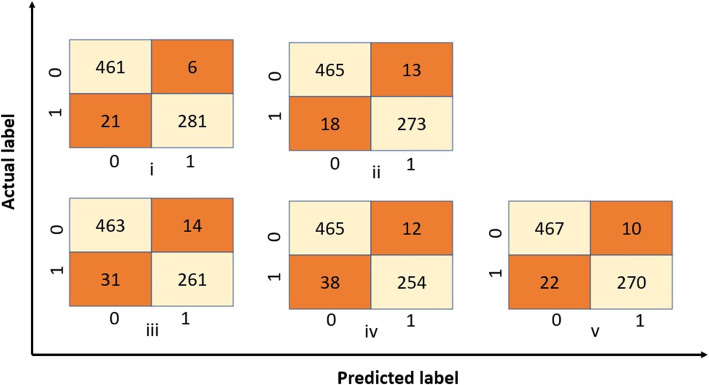
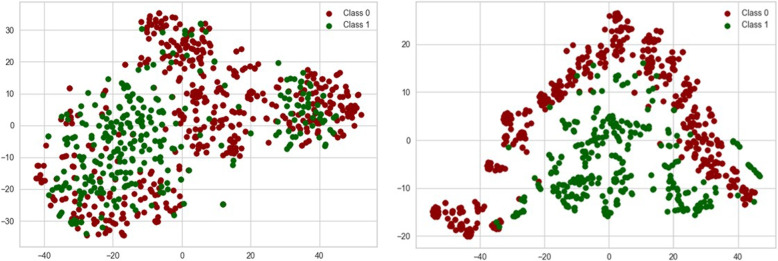
Classical ML to DL models achieved comparable performance in classification, with an F-measure varying between 0.942 and 0.955, whereas the classical ML approaches were faster. Visualisation of embedding representation of input data reveals notable variations in the encoding patterns between classic and DL encoders. Furthermore, LIME explanations provide insights into the most relevant features at token level that contribute to these observed differences.
Despite a general tendency towards deep learning, these use cases show that classical approaches yield comparable results at lower computational cost. Model prediction explanations using LIME in textual and visual layouts provided a qualitative explanation for the model performance.
氧气饱和度是 COVID-19 严重程度的关键指标,但在静默性低氧血症的情况下,其检测存在挑战。电子健康记录(EHR)中经常包含临床叙述中的补充氧气信息。根据氧气水平精简患者识别对于 COVID-19 研究至关重要,这突显了在出院总结中使用自动化分类器来减轻医生手动审查负担的必要性。
我们分析了从匿名 COVID-19 患者出院总结中提取的文本行,以执行二进制分类任务,区分接受氧气补充和未接受氧气补充的患者。比较了各种机器学习(ML)算法,包括经典 ML 到深度学习(DL)模型。使用局部可解释模型不可知解释(LIME)解释器来解释分类器决策,该解释器可可视化模型决策。
经典 ML 到 DL 模型在分类方面的性能相当,F 度量在 0.942 到 0.955 之间变化,而经典 ML 方法更快。输入数据嵌入表示的可视化揭示了经典和 DL 编码器之间在编码模式上的显著差异。此外,LIME 解释提供了有关在令牌级别对这些观察到的差异有贡献的最相关特征的见解。
尽管普遍倾向于深度学习,但这些用例表明,经典方法在计算成本较低的情况下可以产生相当的结果。使用 LIME 在文本和可视化布局中的模型预测解释为模型性能提供了定性解释。