Department of Bioengineering, Imperial College London, London, UK.
Department of Neurobiology and Anatomy, University of Texas Medical School at Houston, Houston, TX, USA.
Nat Commun. 2024 Jul 12;15(1):5856. doi: 10.1038/s41467-024-50205-3.
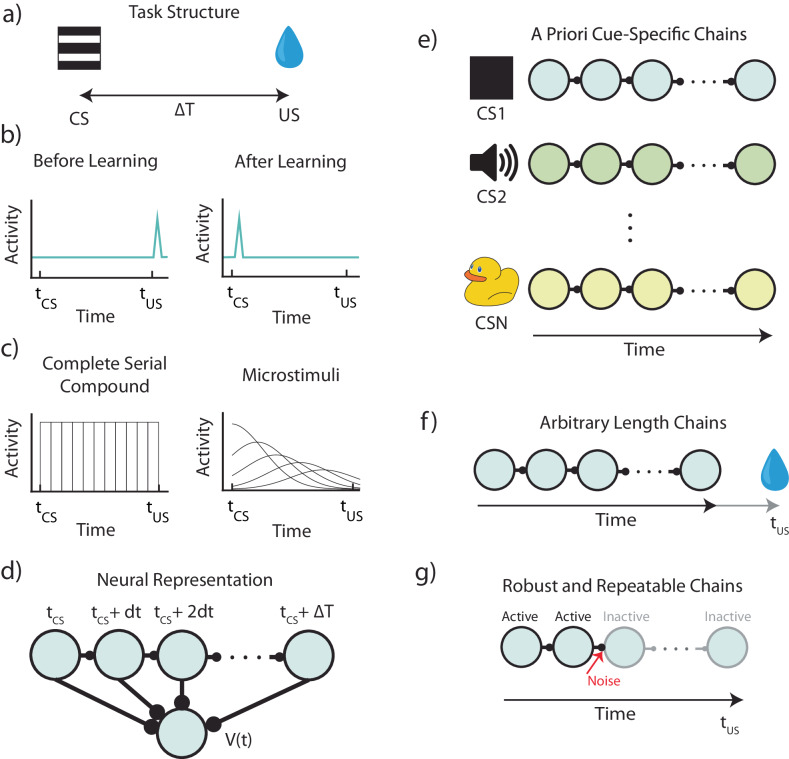
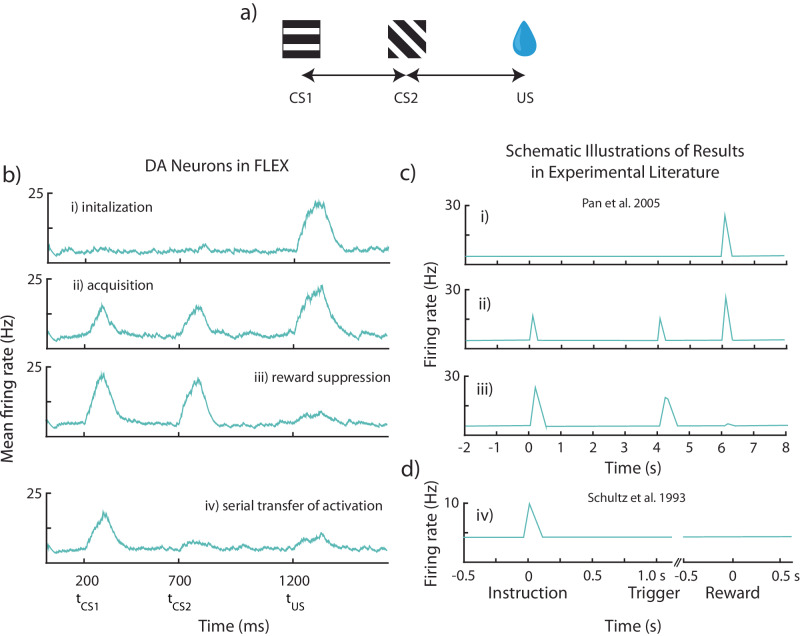
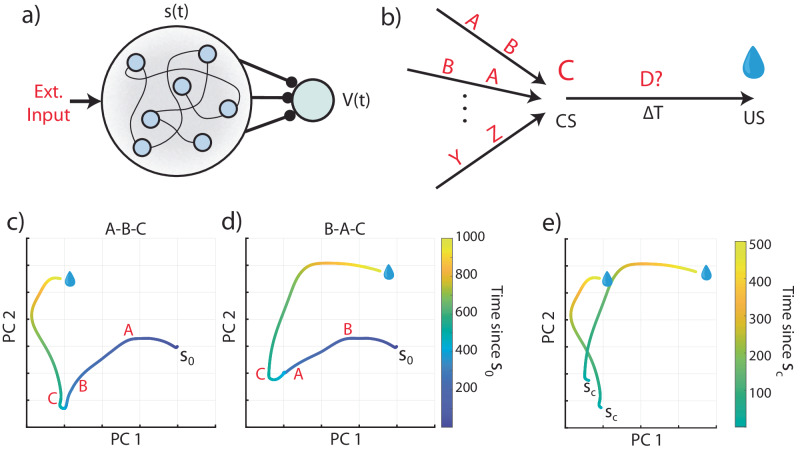
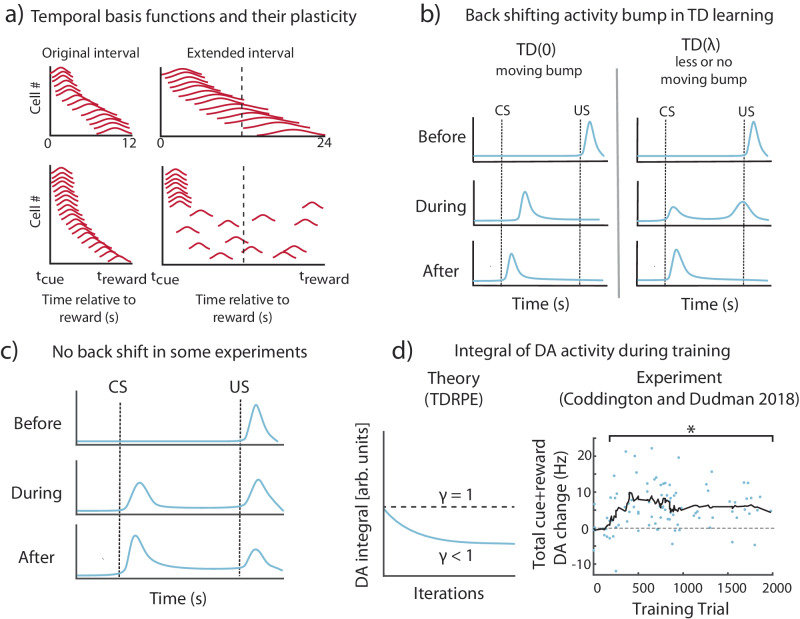
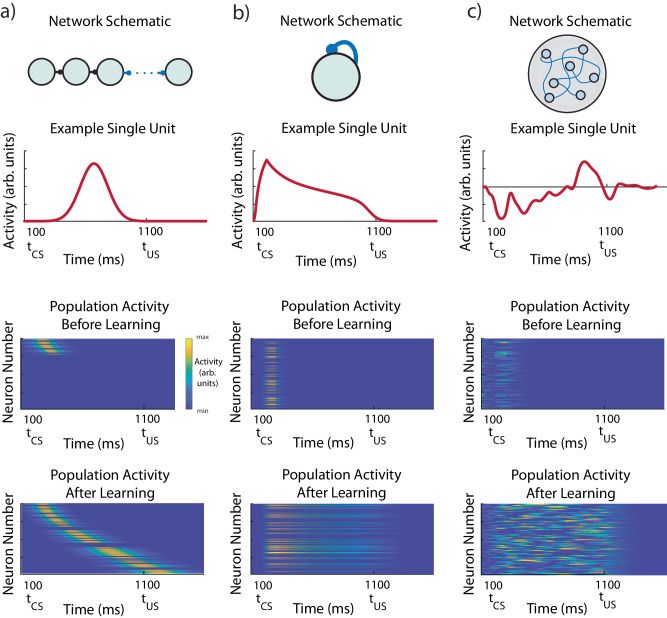
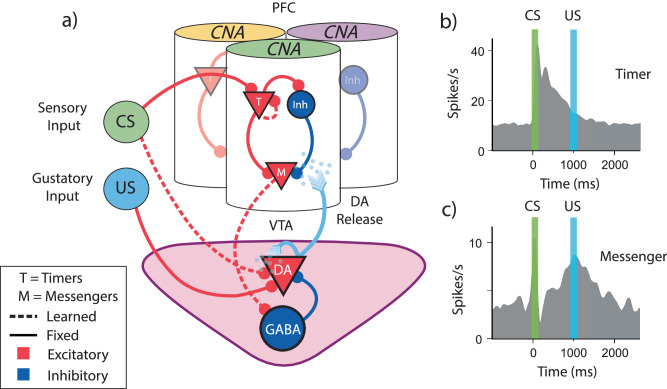
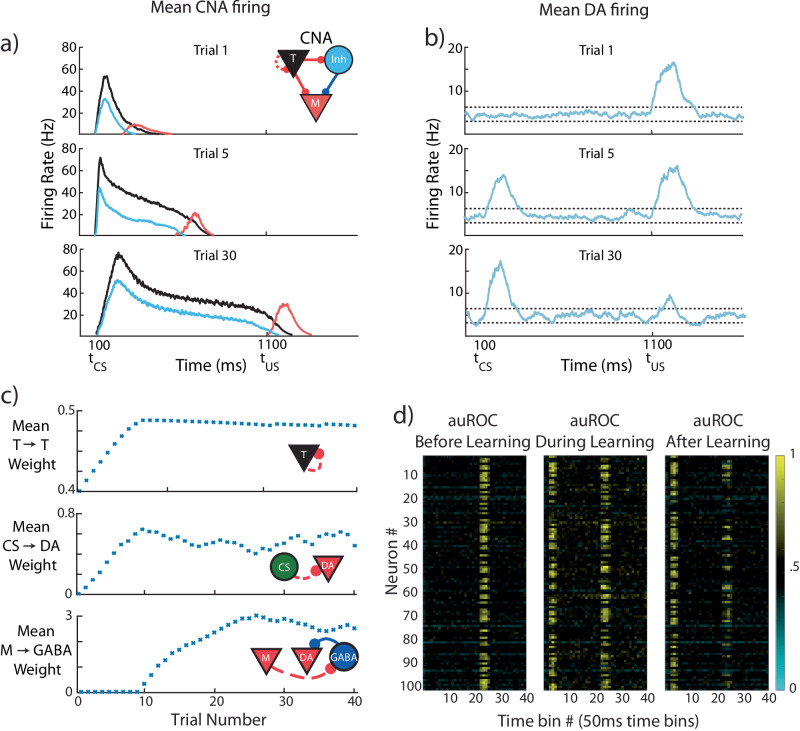
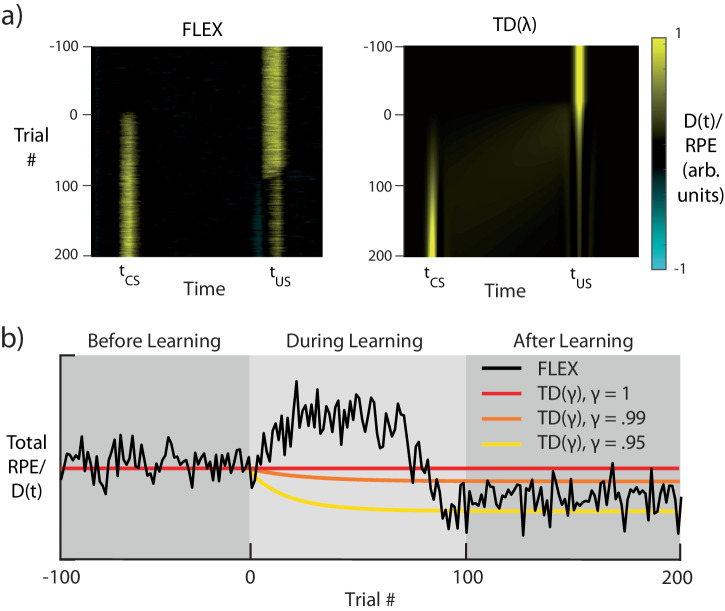
The dominant theoretical framework to account for reinforcement learning in the brain is temporal difference learning (TD) learning, whereby certain units signal reward prediction errors (RPE). The TD algorithm has been traditionally mapped onto the dopaminergic system, as firing properties of dopamine neurons can resemble RPEs. However, certain predictions of TD learning are inconsistent with experimental results, and previous implementations of the algorithm have made unscalable assumptions regarding stimulus-specific fixed temporal bases. We propose an alternate framework to describe dopamine signaling in the brain, FLEX (Flexibly Learned Errors in Expected Reward). In FLEX, dopamine release is similar, but not identical to RPE, leading to predictions that contrast to those of TD. While FLEX itself is a general theoretical framework, we describe a specific, biophysically plausible implementation, the results of which are consistent with a preponderance of both existing and reanalyzed experimental data.
解释学习在大脑中的主要理论框架是时间差分学习(TD)学习,通过这种学习,某些单元会发出奖励预测误差(RPE)信号。传统上,TD 算法被映射到多巴胺能系统,因为多巴胺神经元的发射特性可以类似于 RPE。然而,TD 学习的某些预测与实验结果不一致,并且该算法的先前实现对刺激特异性固定时间基础做出了不可扩展的假设。我们提出了一个替代框架来描述大脑中的多巴胺信号,即 FLEX(灵活学习的预期奖励中的误差)。在 FLEX 中,多巴胺释放类似于但不完全等同于 RPE,这导致了与 TD 预测相反的预测。虽然 FLEX 本身是一个通用的理论框架,但我们描述了一个具体的、生物物理上合理的实现,其结果与大量现有的和重新分析的实验数据一致。