Institute of Medical Technology and Intelligent Systems, Technische Universitaet Hamburg, Hamburg, Germany.
Int J Comput Assist Radiol Surg. 2024 Oct;19(10):2111-2119. doi: 10.1007/s11548-024-03244-6. Epub 2024 Aug 8.
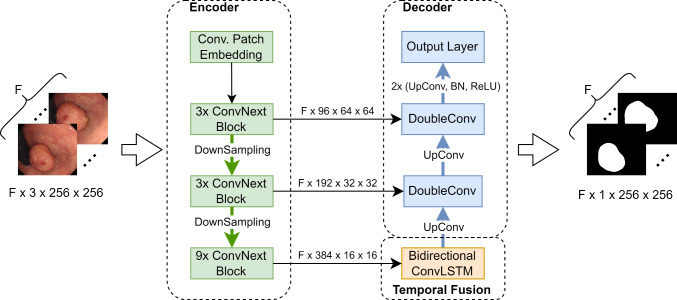
Commonly employed in polyp segmentation, single-image UNet architectures lack the temporal insight clinicians gain from video data in diagnosing polyps. To mirror clinical practices more faithfully, our proposed solution, PolypNextLSTM, leverages video-based deep learning, harnessing temporal information for superior segmentation performance with least parameter overhead, making it possibly suitable for edge devices.
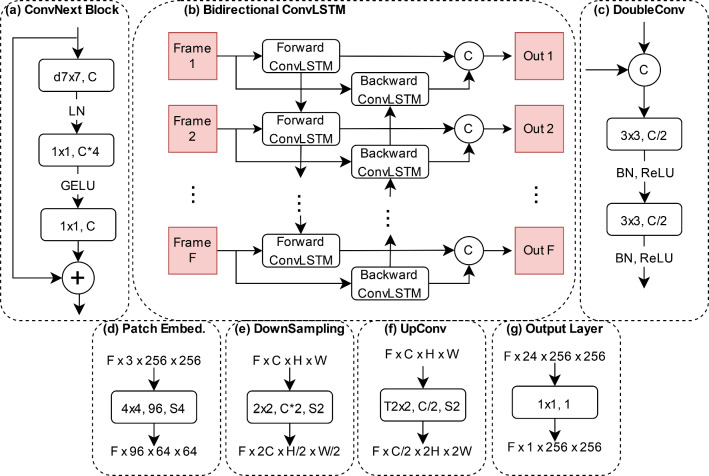
PolypNextLSTM employs a UNet-like structure with ConvNext-Tiny as its backbone, strategically omitting the last two layers to reduce parameter overhead. Our temporal fusion module, a Convolutional Long Short Term Memory (ConvLSTM), effectively exploits temporal features. Our primary novelty lies in PolypNextLSTM, which stands out as the leanest in parameters and the fastest model, surpassing the performance of five state-of-the-art image and video-based deep learning models. The evaluation of the SUN-SEG dataset spans easy-to-detect and hard-to-detect polyp scenarios, along with videos containing challenging artefacts like fast motion and occlusion.
Comparison against 5 image-based and 5 video-based models demonstrates PolypNextLSTM's superiority, achieving a Dice score of 0.7898 on the hard-to-detect polyp test set, surpassing image-based PraNet (0.7519) and video-based PNS+ (0.7486). Notably, our model excels in videos featuring complex artefacts such as ghosting and occlusion.
PolypNextLSTM, integrating pruned ConvNext-Tiny with ConvLSTM for temporal fusion, not only exhibits superior segmentation performance but also maintains the highest frames per speed among evaluated models. Code can be found here: https://github.com/mtec-tuhh/PolypNextLSTM .
常用于息肉分割,单图像 UNet 架构缺乏临床医生从视频数据中诊断息肉获得的时间洞察力。为了更忠实地反映临床实践,我们提出的解决方案 PolypNextLSTM 利用基于视频的深度学习,利用时间信息实现卓越的分割性能,同时参数开销最小,使其可能适用于边缘设备。
PolypNextLSTM 采用类似于 UNet 的结构,以 ConvNext-Tiny 作为其骨干,策略性地省略最后两层以减少参数开销。我们的时间融合模块是一个卷积长短期记忆(ConvLSTM),有效地利用了时间特征。我们的主要创新在于 PolypNextLSTM,它是参数最精简、速度最快的模型,超过了五个最先进的基于图像和视频的深度学习模型的性能。对 SUN-SEG 数据集的评估涵盖了易于检测和难以检测的息肉场景,以及包含快速运动和遮挡等挑战性伪影的视频。
与 5 个基于图像和 5 个基于视频的模型进行比较,证明了 PolypNextLSTM 的优越性,在难以检测的息肉测试集上达到了 0.7898 的骰子分数,超过了基于图像的 PraNet(0.7519)和基于视频的 PNS+(0.7486)。值得注意的是,我们的模型在具有复杂伪影(如重影和遮挡)的视频中表现出色。
PolypNextLSTM 将修剪后的 ConvNext-Tiny 与 ConvLSTM 集成进行时间融合,不仅表现出卓越的分割性能,而且在评估的模型中保持最高的帧率。代码可以在这里找到:https://github.com/mtec-tuhh/PolypNextLSTM。