Kucharski Rafał, Cats Oded
Faculty of Mathematics and Computer Science, Jagiellonian University, Krakow, Poland.
Delft University of Technology, Delft, the Netherlands.
NPJ Sustain Mobil Transp. 2024;1(1):6. doi: 10.1038/s44333-024-00006-4. Epub 2024 Sep 13.
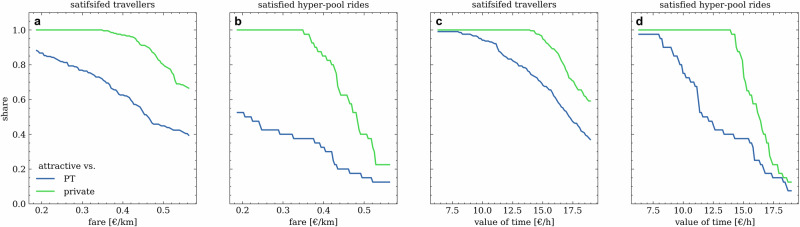
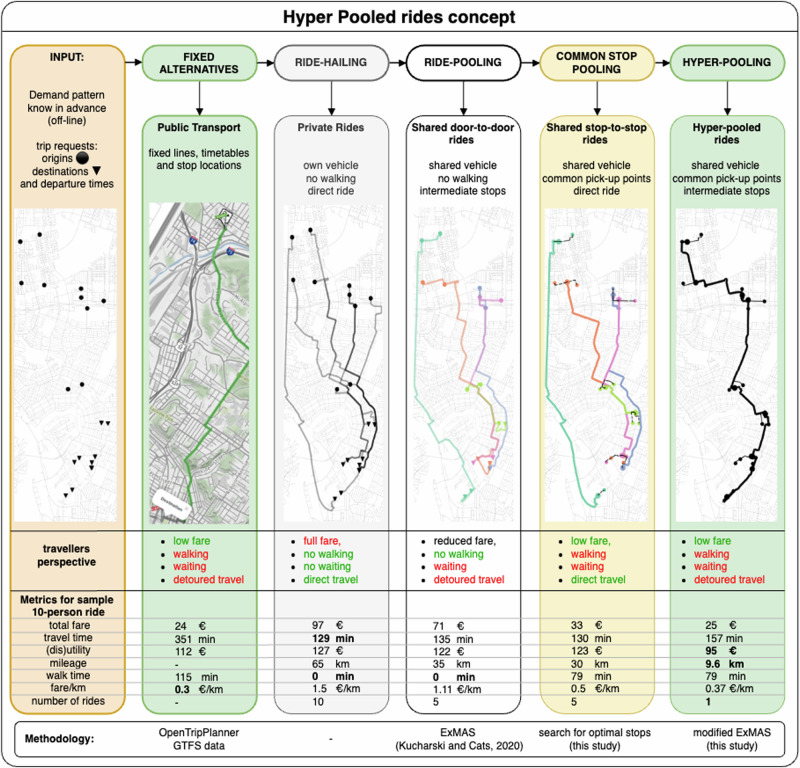
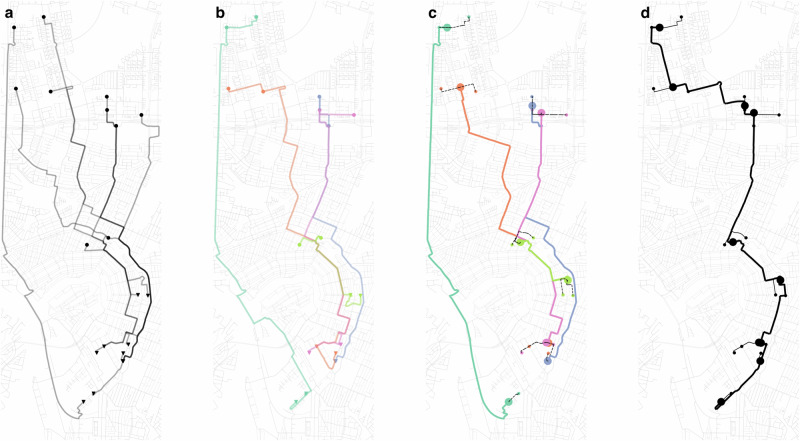
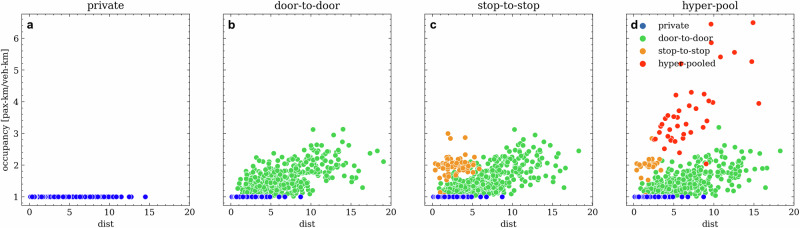
The size of the solution space associated with the trip-matching problem has made the search for high-order ride-pooling prohibitive. We introduce hyper-pooled rides along with a method to identify them within urban demand patterns. Travellers of hyper-pooled rides walk to common pick-up points, travel with a shared vehicle along a sequence of stops and are dropped off at stops from which they walk to their destinations. While closely resembling classical mass transit, hyper-pooled rides are purely demand-driven, with itineraries (stop locations, sequences, timings) optimised for all co-travellers. For 2000 trips in Amsterdam the algorithm generated 40 hyper-pooled rides transporting 225 travellers. They would require 52.5 vehicle hours to travel solo, whereas in the hyper-pooled multi-stop rides, it is reduced sixfold to 9 vehicle hours only. This efficiency gain is made possible by achieving an average occupancy of 5.8 (and a maximum of 14) while remaining attractive for all co-travellers.
与行程匹配问题相关的解空间规模使得寻找高阶拼车变得难以实现。我们引入了超拼车出行方式以及一种在城市出行需求模式中识别它们的方法。超拼车出行的乘客步行至共同的上车点,乘坐共享车辆沿一系列站点行驶,然后在站点下车,再步行至目的地。虽然超拼车出行与传统公共交通非常相似,但它完全由需求驱动,其行程(站点位置、顺序、时间)针对所有同行乘客进行了优化。对于阿姆斯特丹的2000次出行,该算法生成了40次超拼车出行,运送了225名乘客。这些乘客单独出行需要52.5个车辆小时,而在超拼车的多站点出行中,这一数字降至仅9个车辆小时,减少了六倍。通过实现平均载客量为5.8(最高为14),同时对所有同行乘客仍具吸引力,从而实现了这种效率提升。