Department of Clinical Medicine, Xinjiang Medical University, Urumqi, 830017, China.
Department of Geriatric integrative, Second Affiliated Hospital of Xinjiang Medical University, NO.38, South Lake East Road North Second Lane, Shuimogou District, Urumqi, 830063, Xinjiang, China.
Sci Rep. 2024 Sep 27;14(1):22281. doi: 10.1038/s41598-024-73733-w.
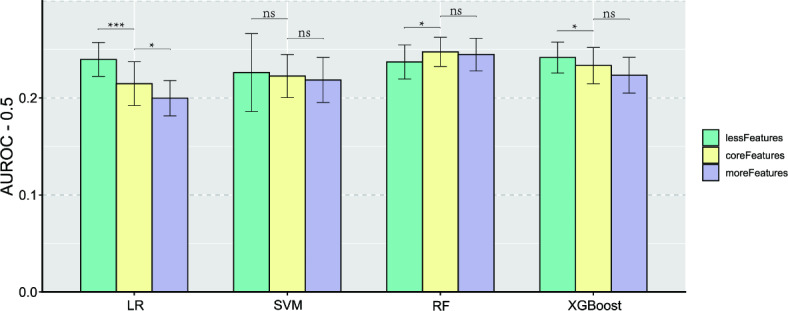
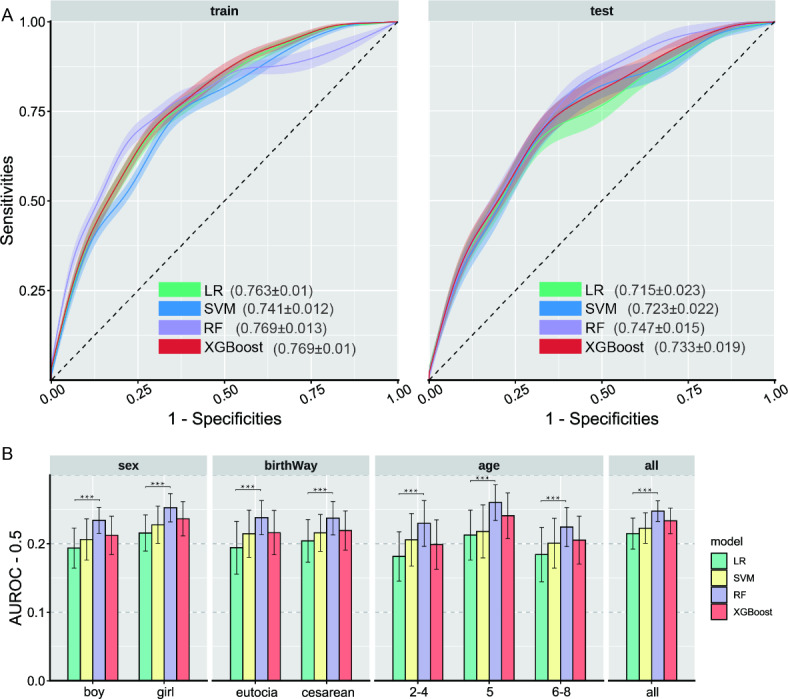
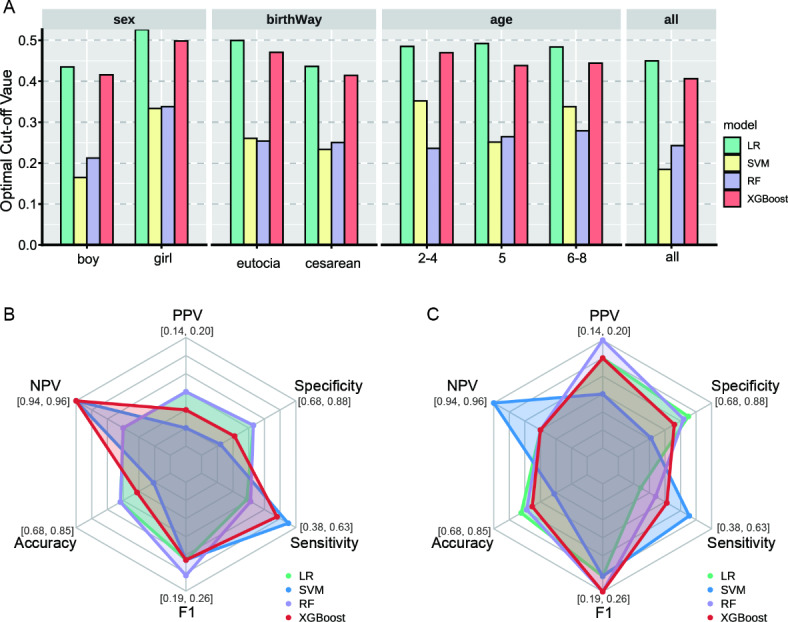
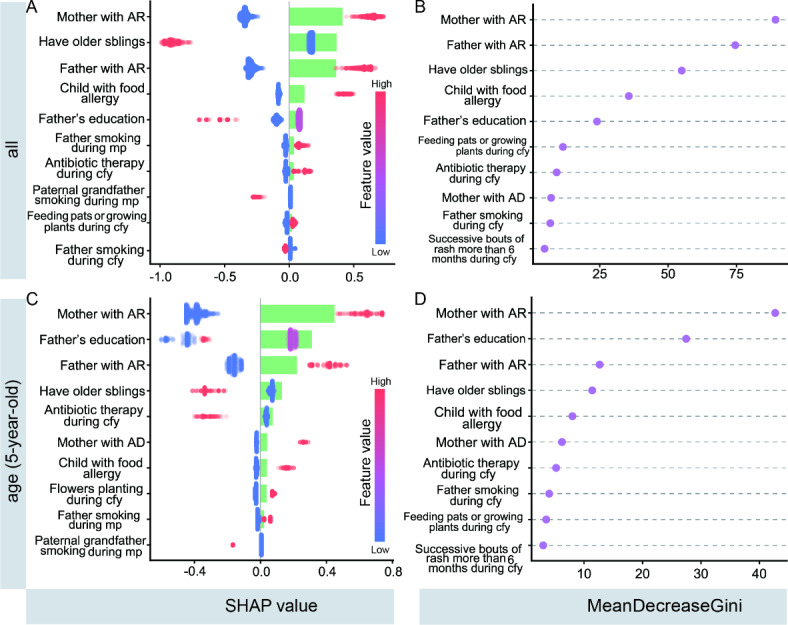
This study aimed to investigate the advantages and applications of machine learning models in predicting the risk of allergic rhinitis (AR) in children aged 2-8, compared to traditional logistic regression. The study analyzed questionnaire data from 7131 children aged 2-8, which was randomly divided into training, validation, and testing sets in a ratio of 55:15:30, repeated 100 times. Predictor variables included parental allergy, medical history during the child's first year (cfy), and early life environmental factors. The time of first onset of AR was restricted to after the age of 1 year to establish a clear temporal relationship between the predictor variables and the outcome. Feature engineering utilized the chi-square test and the Boruta algorithm, refining the dataset for analysis. The construction utilized Logistic Regression (LR), Support Vector Machine (SVM), Random Forest (RF), and Extreme Gradient Boosting Tree (XGBoost) as the models. Model performance was evaluated using the area under the receiver operating characteristic curve (AUROC), and the optimal decision threshold was determined by weighing multiple metrics on the validation sets and reporting results on the testing set. Additionally, the strengths and limitations of the different models were comprehensively analyzed by stratifying gender, mode of birth, and age subgroups, as well as by varying the number of predictor variables. Furthermore, methods such as Shapley additive explanations (SHAP) and purity of node partition in Random Forest were employed to assess feature importance, along with exploring model stability through alterations in the number of features. In this study, 7131 children aged 2-8 were analyzed, with 524 (7.35%) diagnosed with AR, with an onset age ranging from 2 to 8 years. Optimal parameters were refined using the validation set, and a rigorous process of 100 random divisions and repeated training ensured robust evaluation of the models on the testing set. The model construction involved incorporating fourteen variables, including the history of allergy-related diseases during the child's first year, familial genetic factors, and early-life indoor environmental factors. The performance of LR, SVM, RF, and XGBoost on the unstratified data test set was 0.715 (standard deviation = 0.023), 0.723 (0.022), 0.747 (0.015), and 0.733 (0.019), respectively; the performance of each model was stable on the stratified data, and the RF performance was significantly better than that of LR (paired samples t-test: p < 0.001). Different techniques for evaluating the importance of features showed that the top5 variables were father or mother with AR, having older siblings, history of food allergy and father's educational level. Utilizing strategies like stratification and adjusting the number of features, this study constructed a random forest model that outperforms traditional logistic regression. Specifically designed to detect the occurrence of allergic rhinitis (AR) in children aged 2-8, the model incorporates parental allergic history and early life environmental factors. The selection of the optimal cut-off value was determined through a comprehensive evaluation strategy. Additionally, we identified the top 5 crucial features that greatly influence the model's performance. This study serves as a valuable reference for implementing machine learning-based AR prediction in pediatric populations.
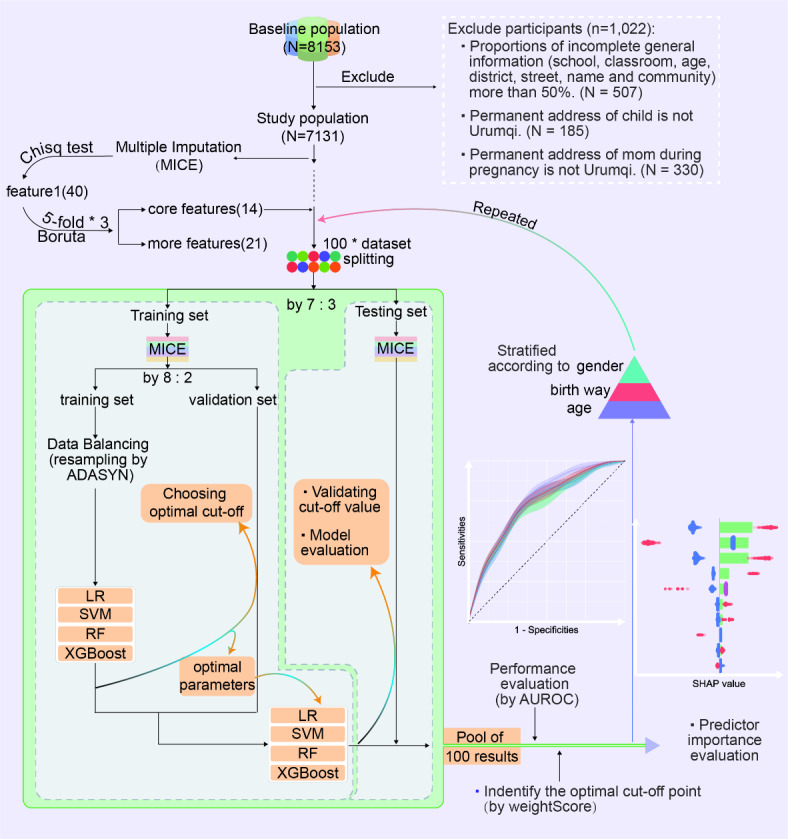
本研究旨在探讨机器学习模型在预测 2-8 岁儿童变应性鼻炎(AR)风险方面的优势和应用,与传统的逻辑回归相比。研究分析了 7131 名 2-8 岁儿童的问卷调查数据,将其随机分为训练集、验证集和测试集,比例为 55:15:30,并重复 100 次。预测变量包括父母过敏、儿童第一年(cfy)期间的病史和早期生活环境因素。AR 的首次发病时间限制在 1 岁以后,以便在预测变量和结果之间建立明确的时间关系。特征工程利用卡方检验和 Boruta 算法,对数据集进行了精炼分析。构建利用了逻辑回归(LR)、支持向量机(SVM)、随机森林(RF)和极端梯度提升树(XGBoost)作为模型。模型性能使用接收者操作特征曲线下的面积(AUROC)进行评估,并通过在验证集上权衡多个指标和报告测试集上的结果来确定最佳决策阈值。此外,还通过对性别、出生方式和年龄亚组以及不同预测变量数量进行分层,以及通过改变特征数量,对不同模型的优缺点进行了全面分析。此外,还采用了 Shapley 加性解释(SHAP)和随机森林中节点分区的纯度等方法来评估特征的重要性,并通过改变特征数量来探索模型的稳定性。在这项研究中,分析了 7131 名 2-8 岁的儿童,其中 524 名(7.35%)被诊断为 AR,发病年龄为 2 至 8 岁。通过验证集对最优参数进行了细化,并通过 100 次随机划分和重复训练的严格过程,确保了模型在测试集上的稳健评估。模型构建包括纳入了 14 个变量,包括儿童第一年与过敏相关疾病的病史、家族遗传因素和早期生活室内环境因素。LR、SVM、RF 和 XGBoost 在未分层数据测试集上的性能分别为 0.715(标准偏差=0.023)、0.723(0.022)、0.747(0.015)和 0.733(0.019);每个模型在分层数据上的性能都很稳定,RF 性能明显优于 LR(配对样本 t 检验:p<0.001)。不同的特征重要性评估技术表明,前 5 个变量是父母中有 AR、有兄弟姐妹、有食物过敏史和父亲的教育程度。通过分层和调整特征数量等策略,本研究构建了一个随机森林模型,该模型优于传统的逻辑回归。该模型专门设计用于检测 2-8 岁儿童变应性鼻炎(AR)的发生,纳入了父母过敏史和早期生活环境因素。通过综合评价策略确定了最佳截断值。此外,我们还确定了对模型性能影响最大的前 5 个关键特征。本研究为在儿科人群中实施基于机器学习的 AR 预测提供了有价值的参考。