Institute for Clinical Medical Research, School of Medicine, The First Affiliated Hospital of Xiamen University, Xiamen University, Xiamen, 361003, Fujian, China.
Department of Laboratory Medicine, Xiamen Key Laboratory of Genetic Testing, School of Medicine, the First Affiliated Hospital of Xiamen University, Xiamen University, Xiamen, 361003, Fujian, China.
Cardiovasc Diabetol. 2024 Sep 28;23(1):351. doi: 10.1186/s12933-024-02439-0.
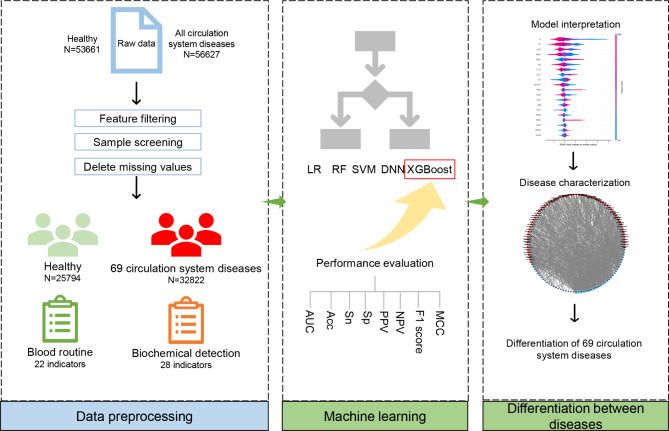
Cardiovascular disease, also known as circulation system disease, remains the leading cause of morbidity and mortality worldwide. Traditional methods for diagnosing cardiovascular disease are often expensive and time-consuming. So the purpose of this study is to construct machine learning models for the diagnosis of cardiovascular diseases using easily accessible blood routine and biochemical detection data and explore the unique hematologic features of cardiovascular diseases, including some metabolic indicators.
After the data preprocessing, 25,794 healthy people and 32,822 circulation system disease patients with the blood routine and biochemical detection data were utilized for our study. We selected logistic regression, random forest, support vector machine, eXtreme Gradient Boosting (XGBoost), and deep neural network to construct models. Finally, the SHAP algorithm was used to interpret models.
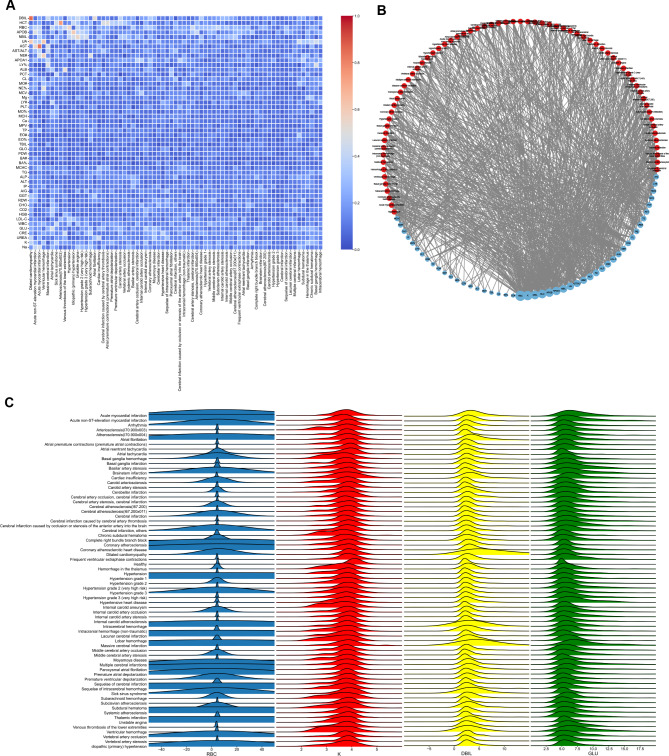
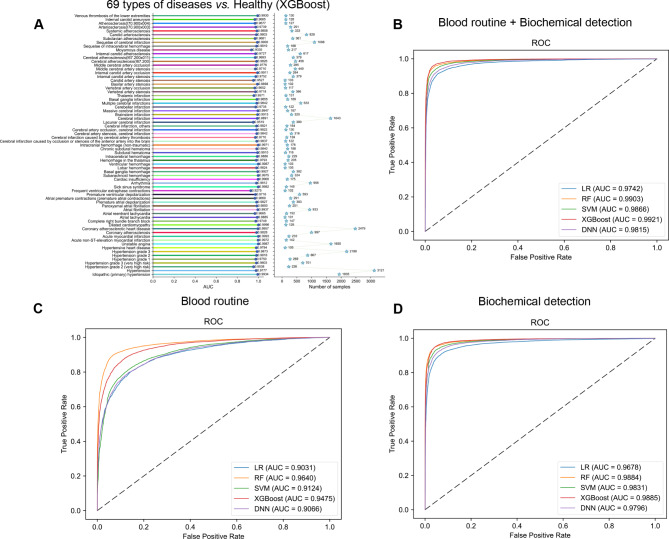
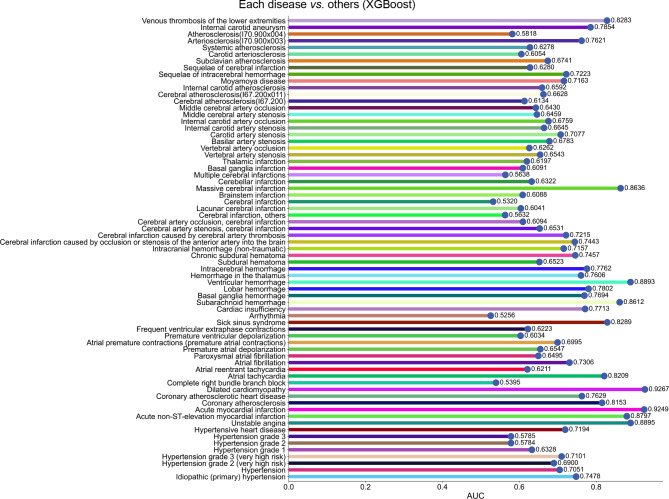
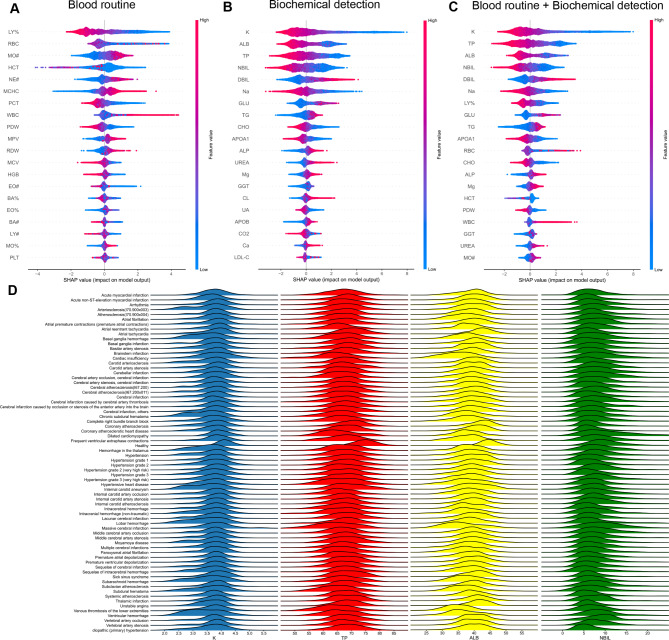
The circulation system disease prediction model constructed by XGBoost possessed the best performance (AUC: 0.9921 (0.9911-0.9930); Acc: 0.9618 (0.9588-0.9645); Sn: 0.9690 (0.9655-0.9723); Sp: 0.9526 (0.9477-0.9572); PPV: 0.9631 (0.9592-0.9668); NPV: 0.9600 (0.9556-0.9644); MCC: 0.9224 (0.9165-0.9279); F1 score: 0.9661 (0.9634-0.9686)). Most models of distinguishing various circulation system diseases also had good performance, the model performance of distinguishing dilated cardiomyopathy from other circulation system diseases was the best (AUC: 0.9267 (0.8663-0.9752)). The model interpretation by the SHAP algorithm indicated features from biochemical detection made major contributions to predicting circulation system disease, such as potassium (K), total protein (TP), albumin (ALB), and indirect bilirubin (NBIL). But for models of distinguishing various circulation system diseases, we found that red blood cell count (RBC), K, direct bilirubin (DBIL), and glucose (GLU) were the top 4 features subdividing various circulation system diseases.
The present study constructed multiple models using 50 features from the blood routine and biochemical detection data for the diagnosis of various circulation system diseases. At the same time, the unique hematologic features of various circulation system diseases, including some metabolic-related indicators, were also explored. This cost-effective work will benefit more people and help diagnose and prevent circulation system diseases.
心血管疾病,又称循环系统疾病,仍是全球发病率和死亡率的主要原因。传统的心血管疾病诊断方法往往既昂贵又耗时。因此,本研究旨在使用易于获得的血常规和生化检测数据构建用于心血管疾病诊断的机器学习模型,并探索心血管疾病的独特血液学特征,包括一些代谢指标。
在数据预处理后,我们使用了 25794 名健康人和 32822 名患有循环系统疾病的患者的血常规和生化检测数据。我们选择了逻辑回归、随机森林、支持向量机、极端梯度提升(XGBoost)和深度神经网络来构建模型。最后,我们使用 SHAP 算法对模型进行解释。
XGBoost 构建的循环系统疾病预测模型表现最佳(AUC:0.9921(0.9911-0.9930);Acc:0.9618(0.9588-0.9645);Sn:0.9690(0.9655-0.9723);Sp:0.9526(0.9477-0.9572);PPV:0.9631(0.9592-0.9668);NPV:0.9600(0.9556-0.9644);MCC:0.9224(0.9165-0.9279);F1 分数:0.9661(0.9634-0.9686))。区分各种循环系统疾病的大多数模型也表现良好,区分扩张型心肌病与其他循环系统疾病的模型性能最佳(AUC:0.9267(0.8663-0.9752))。SHAP 算法的模型解释表明,生化检测中的特征对预测循环系统疾病有重要贡献,如钾(K)、总蛋白(TP)、白蛋白(ALB)和间接胆红素(NBIL)。但对于区分各种循环系统疾病的模型,我们发现红细胞计数(RBC)、K、直接胆红素(DBIL)和葡萄糖(GLU)是区分各种循环系统疾病的前 4 个特征。
本研究使用血常规和生化检测数据中的 50 个特征构建了多个用于诊断各种循环系统疾病的模型。同时,还探索了各种循环系统疾病的独特血液学特征,包括一些代谢相关指标。这项具有成本效益的工作将使更多的人受益,并有助于诊断和预防循环系统疾病。