School of Artificial Intelligence and Computer Science, Jiangnan University, No. 1800 Lihu Avenue, Binhu District, Wuxi 214000, China.
School of Artificial Intelligence, Hebei University of Technology, 5340 Xiping Road, Beichen District, Tianjin 300130, China.
Brief Bioinform. 2024 Sep 23;25(6). doi: 10.1093/bib/bbae504.
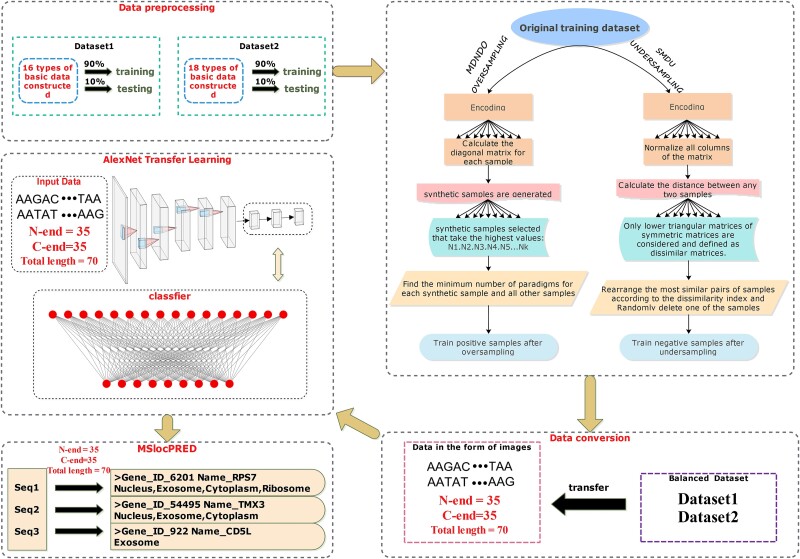
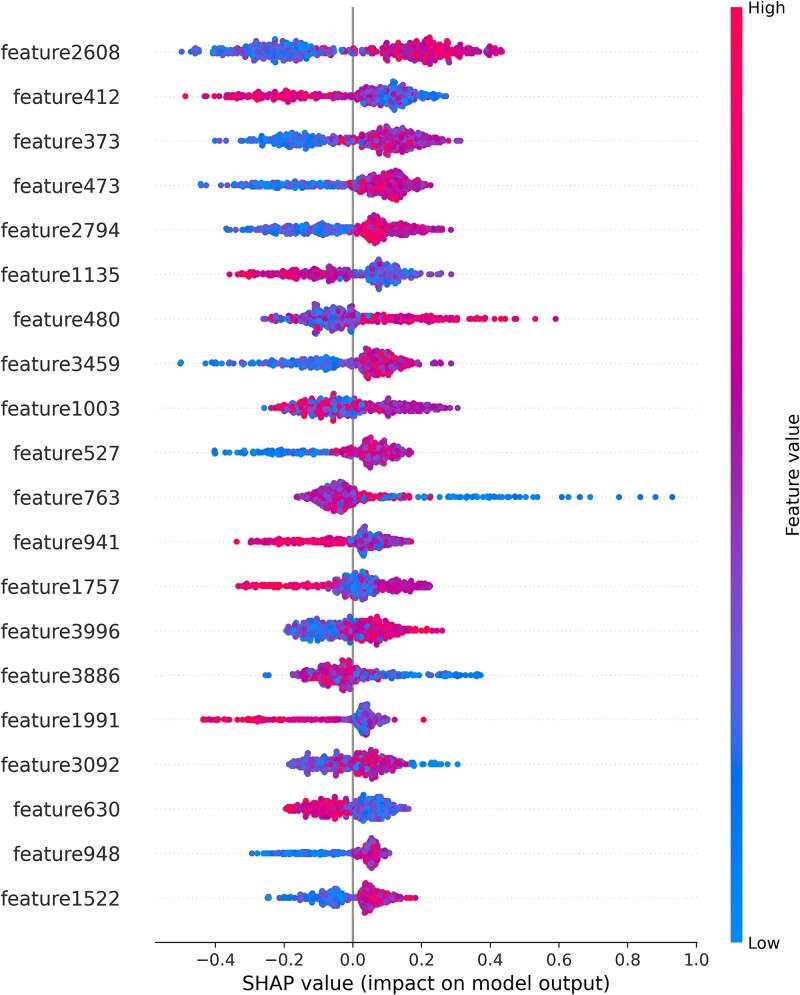
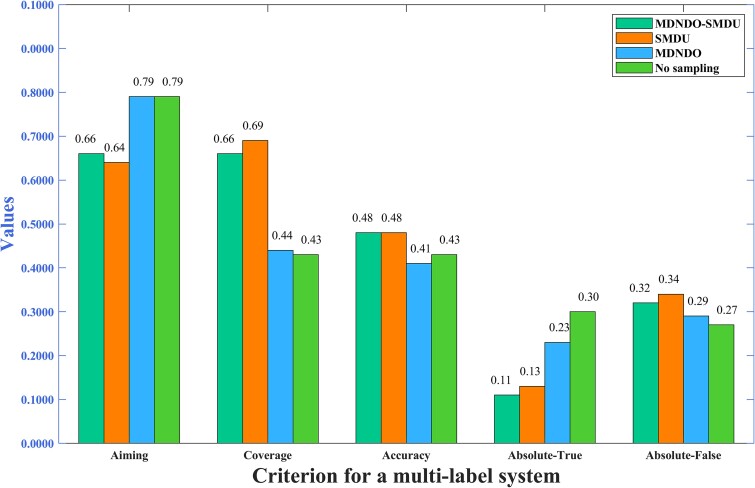
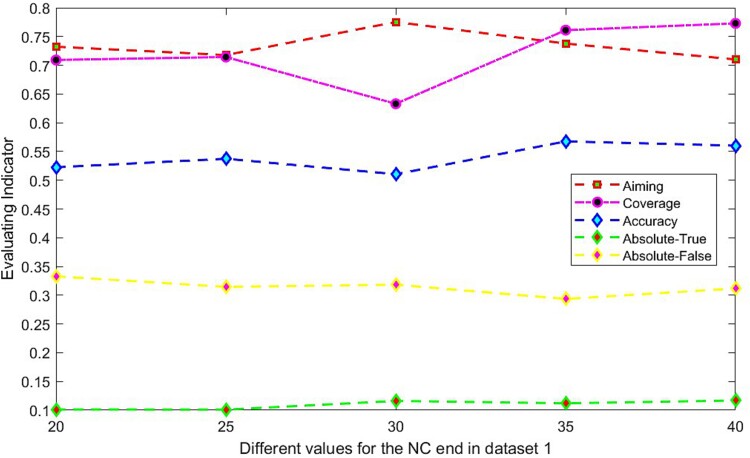
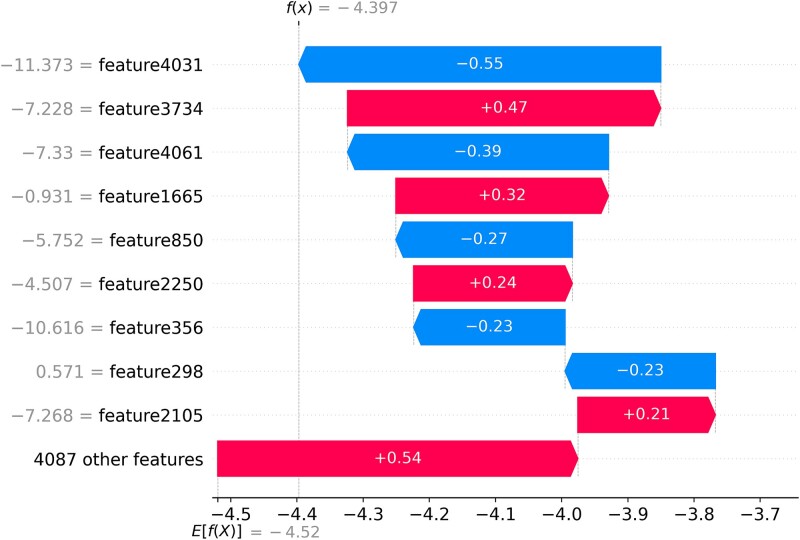
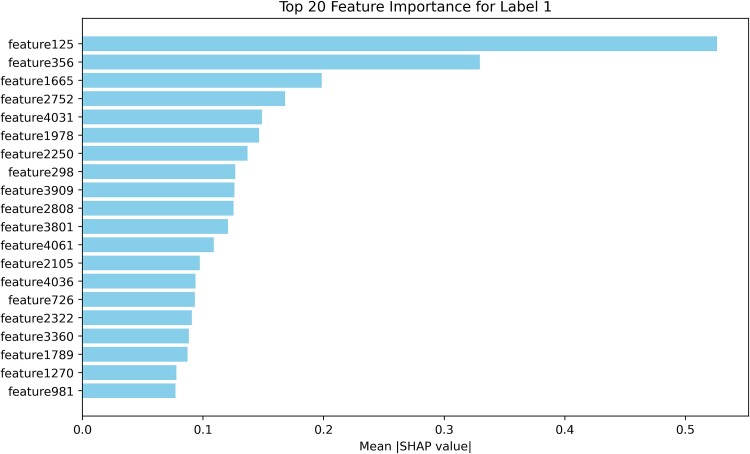
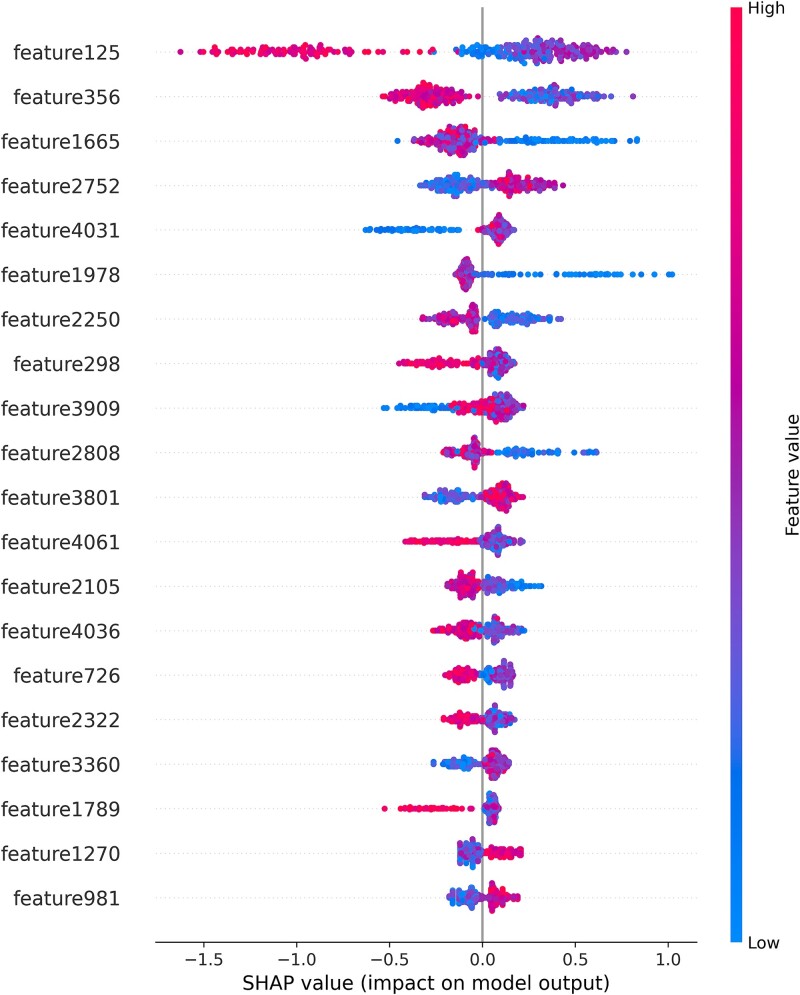
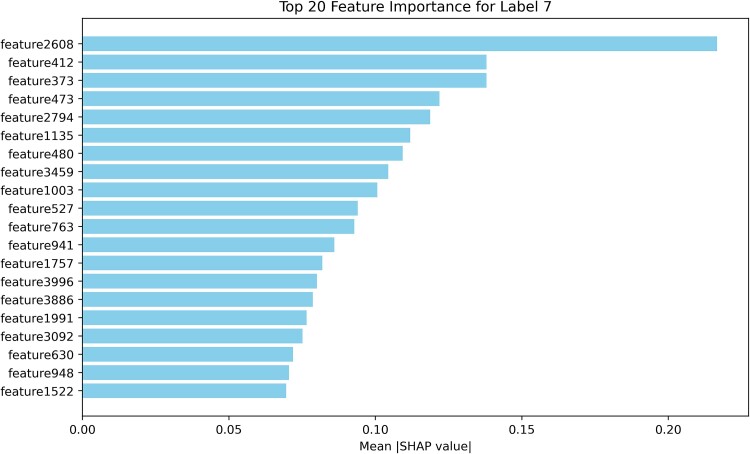
Subcellular localization of messenger ribonucleic acid (mRNA) is a universal mechanism for precise and efficient control of the translation process. Although many computational methods have been constructed by researchers for predicting mRNA subcellular localization, very few of these computational methods have been designed to predict subcellular localization with multiple localization annotations, and their generalization performance could be improved. In this study, the prediction model MSlocPRED was constructed to identify multi-label mRNA subcellular localization. First, the preprocessed Dataset 1 and Dataset 2 are transformed into the form of images. The proposed MDNDO-SMDU resampling technique is then used to balance the number of samples in each category in the training dataset. Finally, deep transfer learning was used to construct the predictive model MSlocPRED to identify subcellular localization for 16 classes (Dataset 1) and 18 classes (Dataset 2). The results of comparative tests of different resampling techniques show that the resampling technique proposed in this study is more effective in preprocessing for subcellular localization. The prediction results of the datasets constructed by intercepting different NC end (Both the 5' and 3' untranslated regions that flank the protein-coding sequence and influence mRNA function without encoding proteins themselves.) lengths show that for Dataset 1 and Dataset 2, the prediction performance is best when the NC end is intercepted by 35 nucleotides, respectively. The results of both independent testing and five-fold cross-validation comparisons with established prediction tools show that MSlocPRED is significantly better than established tools for identifying multi-label mRNA subcellular localization. Additionally, to understand how the MSlocPRED model works during the prediction process, SHapley Additive exPlanations was used to explain it. The predictive model and associated datasets are available on the following github: https://github.com/ZBYnb1/MSlocPRED/tree/main.
信使核糖核酸(mRNA)的亚细胞定位是精确和有效控制翻译过程的通用机制。尽管研究人员已经构建了许多用于预测 mRNA 亚细胞定位的计算方法,但很少有这些计算方法被设计用于预测具有多个定位注释的亚细胞定位,并且它们的泛化性能可以得到提高。在这项研究中,构建了预测模型 MSlocPRED 来识别多标签 mRNA 亚细胞定位。首先,将预处理后的数据集 1 和数据集 2 转换为图像形式。然后,使用提出的 MDNDO-SMDU 重采样技术来平衡训练数据集中每个类别的样本数量。最后,使用深度迁移学习来构建预测模型 MSlocPRED,以识别 16 类(数据集 1)和 18 类(数据集 2)的亚细胞定位。不同重采样技术的比较测试结果表明,本研究提出的重采样技术在亚细胞定位的预处理中更有效。通过截取不同 NC 端(侧翼编码序列的 5'和 3'非翻译区,影响 mRNA 功能而不编码蛋白质本身)长度构建数据集的预测结果表明,对于数据集 1 和数据集 2,当 NC 端分别被 35 个核苷酸截取时,预测性能最佳。与已建立的预测工具进行独立测试和五重交叉验证比较的结果表明,MSlocPRED 用于识别多标签 mRNA 亚细胞定位的性能明显优于已建立的工具。此外,为了了解 MSlocPRED 模型在预测过程中的工作方式,使用 SHapley Additive exPlanations 对其进行了解释。预测模型和相关数据集可在以下 github 上获得:https://github.com/ZBYnb1/MSlocPRED/tree/main。