Department of Chemical Engineering, Faculty of Engineering and Science, Universidad de La Frontera, Ave. Francisco Salazar 01145, Temuco 4811230, Chile.
Departamento de Ciencias Básicas, Facultad de Ciencias, Universidad Santo Tomas, Temuco 4780000, Chile.
Int J Mol Sci. 2024 Sep 24;25(19):10267. doi: 10.3390/ijms251910267.
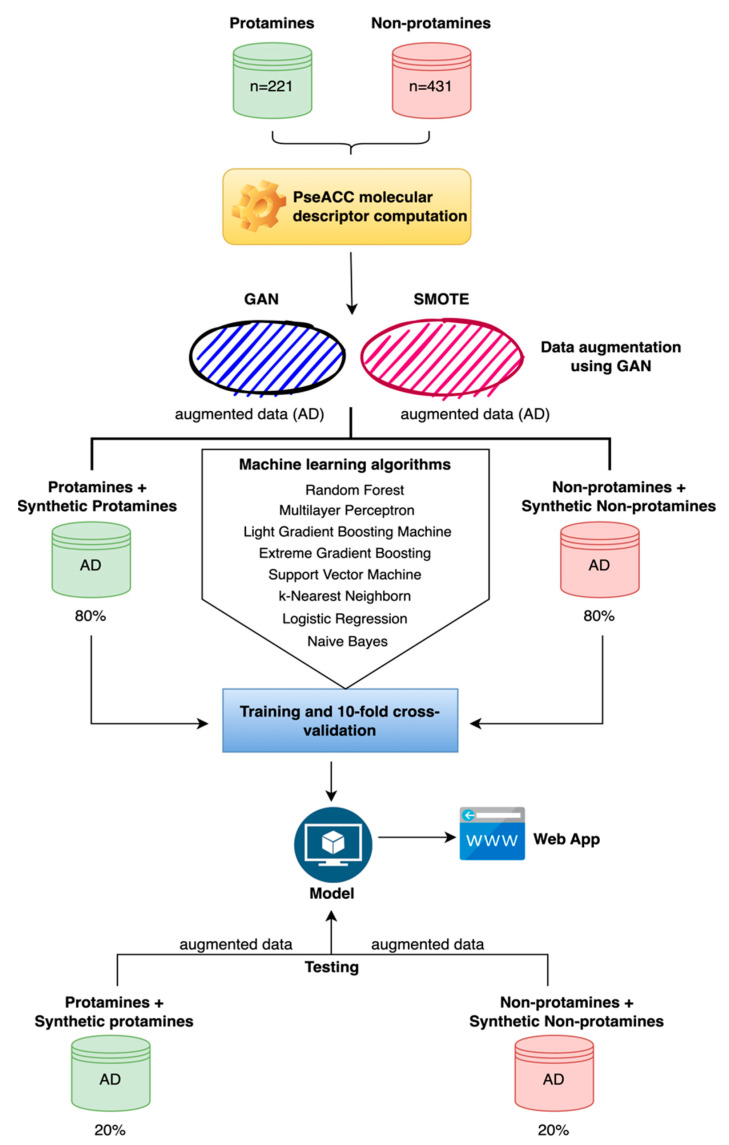
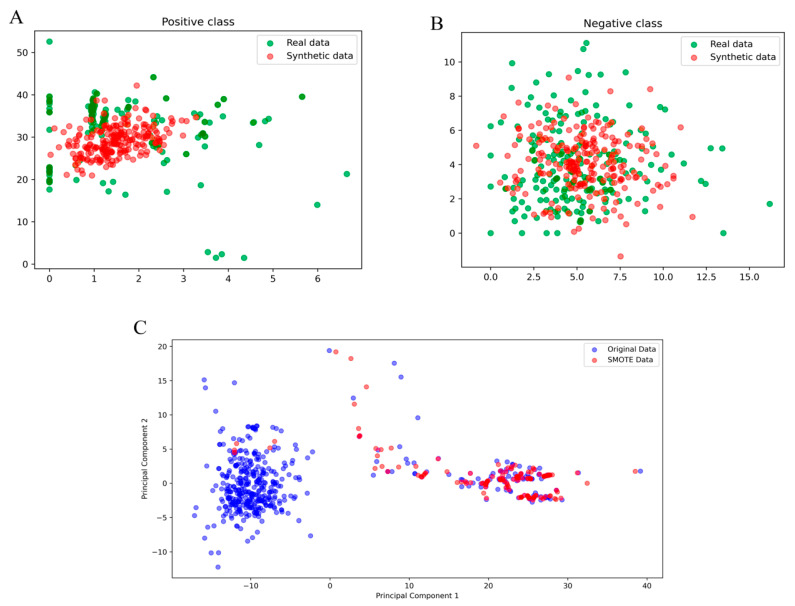
Protamines play a critical role in DNA compaction and stabilization in sperm cells, significantly influencing male fertility and various biotechnological applications. Traditionally, identifying these proteins is a challenging and time-consuming process due to their species-specific variability and complexity. Leveraging advancements in computational biology, we present PROTA, a novel tool that combines machine learning (ML) and deep learning (DL) techniques to predict protamines with high accuracy. For the first time, we integrate Generative Adversarial Networks (GANs) with supervised learning methods to enhance the accuracy and generalizability of protamine prediction. Our methodology evaluated multiple ML models, including Light Gradient-Boosting Machine (LIGHTGBM), Multilayer Perceptron (MLP), Random Forest (RF), eXtreme Gradient Boosting (XGBOOST), k-Nearest Neighbors (KNN), Logistic Regression (LR), Naive Bayes (NB), and Radial Basis Function-Support Vector Machine (RBF-SVM). During ten-fold cross-validation on our training dataset, the MLP model with GAN-augmented data demonstrated superior performance metrics: 0.997 accuracy, 0.997 F1 score, 0.998 precision, 0.997 sensitivity, and 1.0 AUC. In the independent testing phase, this model achieved 0.999 accuracy, 0.999 F1 score, 1.0 precision, 0.999 sensitivity, and 1.0 AUC. These results establish PROTA, accessible via a user-friendly web application. We anticipate that PROTA will be a crucial resource for researchers, enabling the rapid and reliable prediction of protamines, thereby advancing our understanding of their roles in reproductive biology, biotechnology, and medicine.
鱼精蛋白在精子细胞的 DNA 压缩和稳定中起着至关重要的作用,显著影响男性生育能力和各种生物技术应用。传统上,由于其物种特异性的变异性和复杂性,鉴定这些蛋白质是一个具有挑战性和耗时的过程。利用计算生物学的进步,我们提出了 PROTA,这是一种新颖的工具,它结合了机器学习(ML)和深度学习(DL)技术,以高精度预测鱼精蛋白。我们首次将生成对抗网络(GANs)与监督学习方法相结合,以提高鱼精蛋白预测的准确性和泛化能力。我们的方法评估了多个 ML 模型,包括 Light Gradient-Boosting Machine (LIGHTGBM)、Multilayer Perceptron (MLP)、Random Forest (RF)、eXtreme Gradient Boosting (XGBOOST)、k-Nearest Neighbors (KNN)、Logistic Regression (LR)、Naive Bayes (NB) 和 Radial Basis Function-Support Vector Machine (RBF-SVM)。在我们的训练数据集上进行十折交叉验证时,具有 GAN 增强数据的 MLP 模型表现出了优越的性能指标:0.997 准确率、0.997 F1 得分、0.998 精度、0.997 敏感性和 1.0 AUC。在独立测试阶段,该模型实现了 0.999 准确率、0.999 F1 得分、1.0 精度、0.999 敏感性和 1.0 AUC。这些结果确立了 PROTA 的地位,可通过用户友好的网络应用程序访问。我们预计 PROTA 将成为研究人员的重要资源,能够快速可靠地预测鱼精蛋白,从而推进我们对其在生殖生物学、生物技术和医学中的作用的理解。