Liu Zheng, Shu Wenqi, Li Teng, Zhang Xuan, Chong Wei
Department of Emergency, The First Hospital of China Medical University, No. 155, Nanjing North Street, Heping District, Shenyang, 11001, China.
Sci Rep. 2025 Jan 6;15(1):887. doi: 10.1038/s41598-025-85121-z.
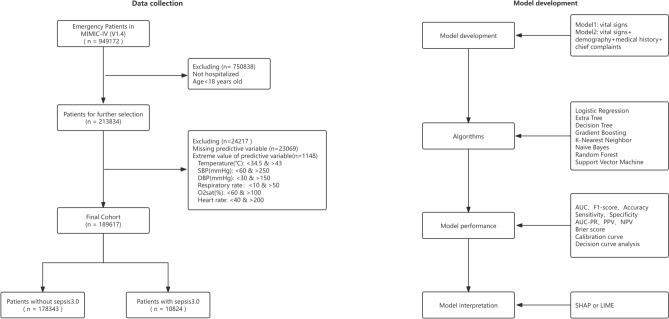
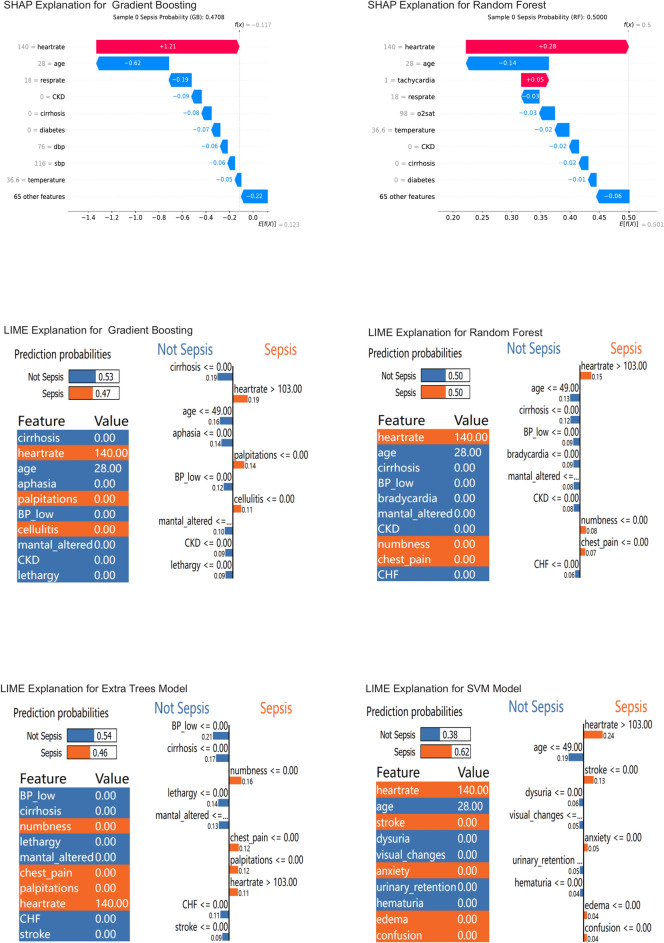
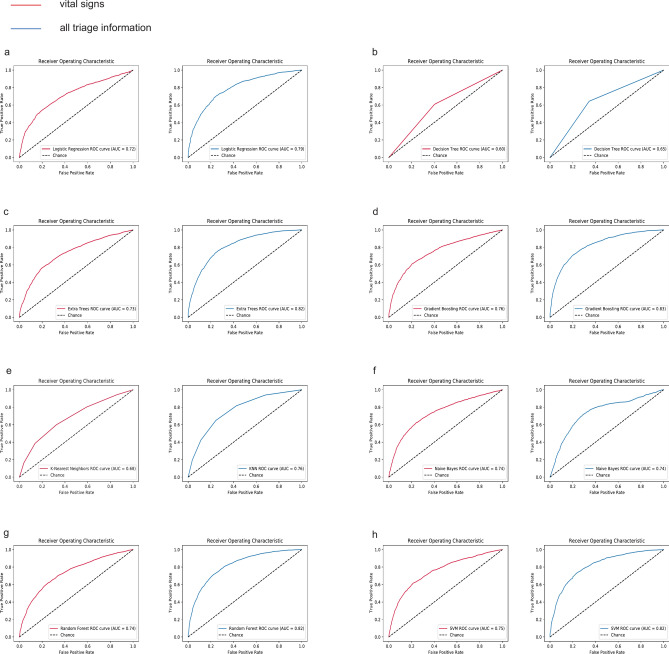
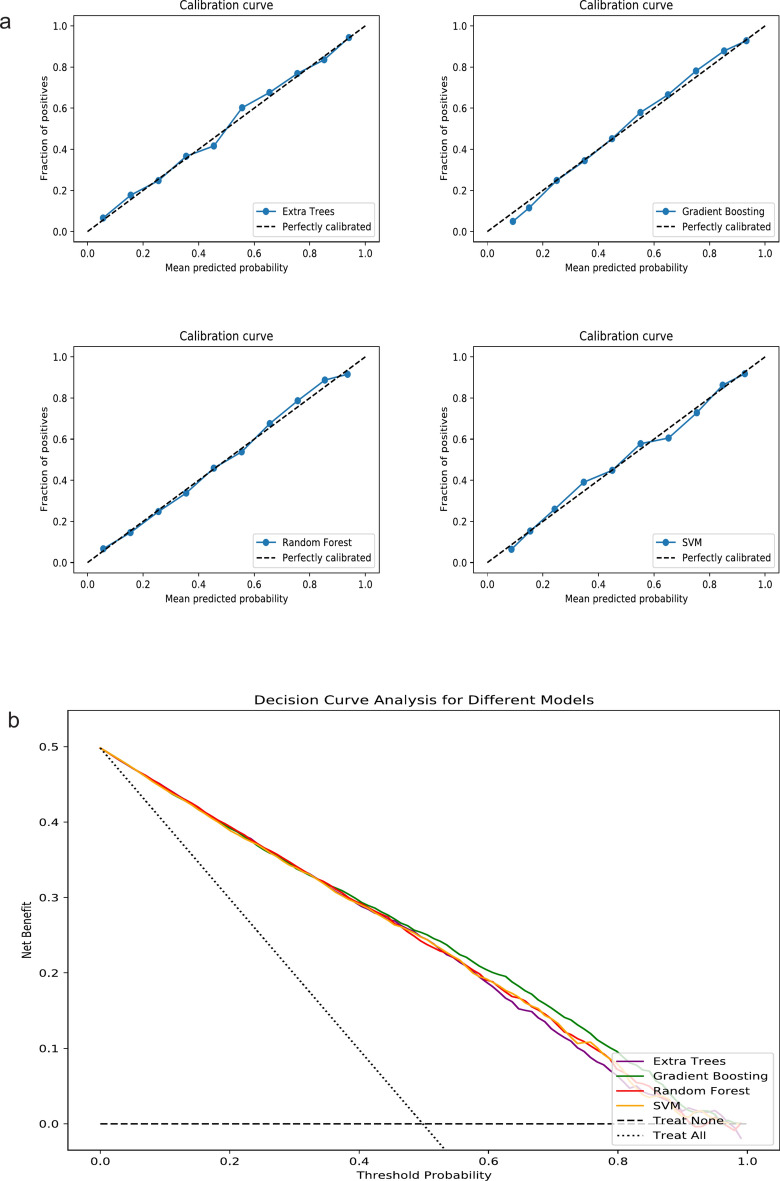
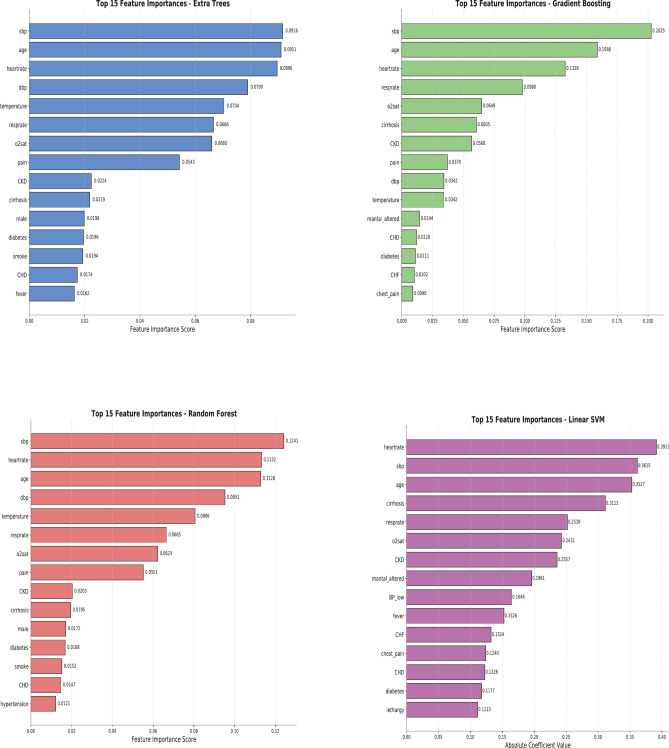
The study aimed to develop and validate a sepsis prediction model using structured electronic medical records (sEMR) and machine learning (ML) methods in emergency triage. The goal was to enhance early sepsis screening by integrating comprehensive triage information beyond vital signs. This retrospective cohort study utilized data from the MIMIC-IV database. Two models were developed: Model 1 based on vital signs alone, and Model 2 incorporating vital signs, demographic characteristics, medical history, and chief complaints. Eight ML algorithms were employed, and model performance was evaluated using metrics such as AUC, F1 Score, and calibration curves. SHapley Additive exPlanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) methods were used to enhance model interpretability. The study included 189,617 patients, with 5.95% diagnosed with sepsis. Model 2 consistently outperformed Model 1 across most algorithms. In Model 2, Gradient Boosting achieved the highest AUC of 0.83, followed by Extra Tree, Random Forest, and Support Vector Machine (all 0.82). The SHAP method provided more comprehensible explanations for the Gradient Boosting algorithm. Modeling with comprehensive triage information using sEMR and ML methods was more effective in predicting sepsis at triage compared to using vital signs alone. Interpretable ML enhanced model transparency and provided sepsis prediction probabilities, offering a feasible approach for early sepsis screening and aiding healthcare professionals in making informed decisions during the triage process.
该研究旨在利用结构化电子病历(sEMR)和机器学习(ML)方法在急诊分诊中开发并验证一种脓毒症预测模型。目标是通过整合生命体征以外的综合分诊信息来加强早期脓毒症筛查。这项回顾性队列研究使用了MIMIC-IV数据库中的数据。开发了两种模型:模型1仅基于生命体征,模型2纳入了生命体征、人口统计学特征、病史和主要症状。采用了八种ML算法,并使用AUC、F1分数和校准曲线等指标评估模型性能。使用SHapley加法解释(SHAP)和局部可解释模型无关解释(LIME)方法来提高模型的可解释性。该研究纳入了189,617名患者,其中5.95%被诊断为脓毒症。在大多数算法中,模型2始终优于模型1。在模型2中,梯度提升算法的AUC最高,为0.83,其次是极端随机树、随机森林和支持向量机(均为0.82)。SHAP方法为梯度提升算法提供了更易于理解的解释。与仅使用生命体征相比,使用sEMR和ML方法结合综合分诊信息进行建模在预测分诊时的脓毒症方面更有效。可解释的ML提高了模型的透明度,并提供了脓毒症预测概率,为早期脓毒症筛查提供了一种可行的方法,并有助于医疗保健专业人员在分诊过程中做出明智的决策。