Chaurasia Priyanka, Yogarajah Pratheepan, Ali Mahdi Abbas, McClean Sally, Kaleem Ahmad Mohammad, Jafar Tabrez, Kumar Singh Sanjay
School of Computing, Engineering & Intelligent Systems, Ulster University, Londonderry, United Kingdom.
Department of Biochemistry, King George Medical University, Lucknow, India.
Front Digit Health. 2025 May 30;7:1608949. doi: 10.3389/fdgth.2025.1608949. eCollection 2025.
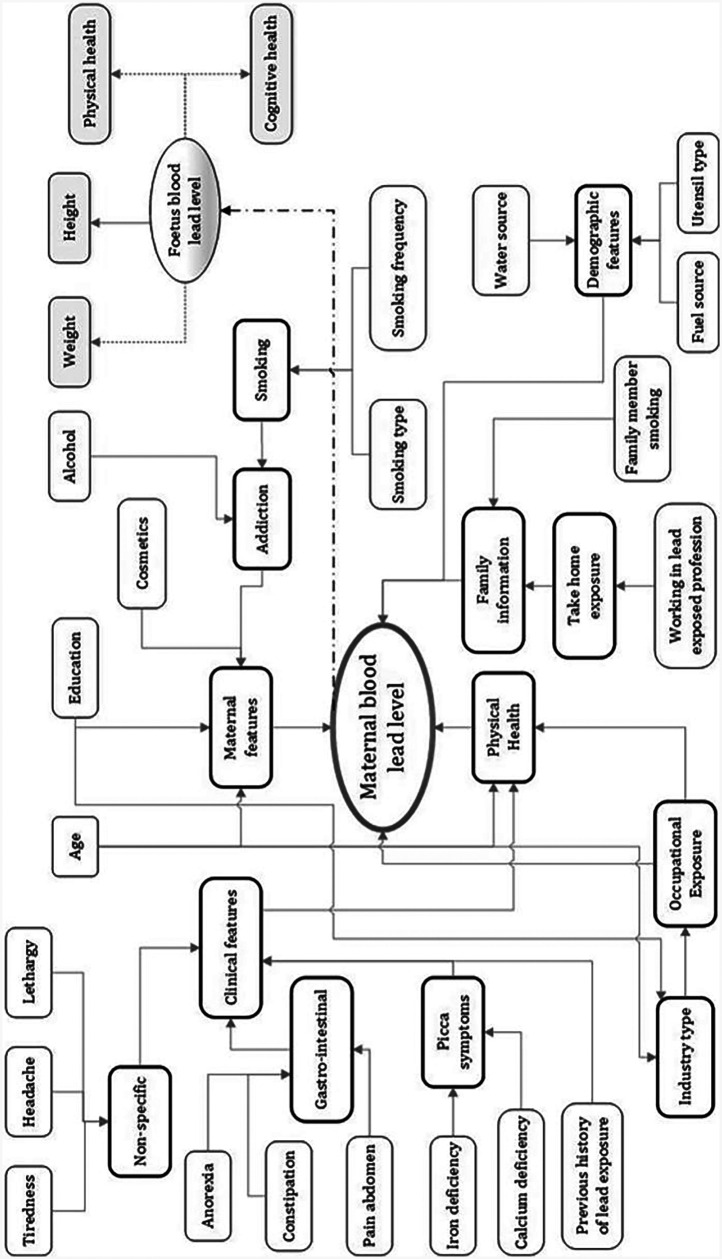
Lead toxicity is a well-recognised environmental health issue, with prenatal exposure posing significant risks to infants. One major pathway of exposure to infants is maternal lead transfer during pregnancy. Therefore, accurately characterising maternal lead levels is critical for enabling targeted and personalised healthcare interventions. Current detection methods for lead poisoning are based on laboratory blood tests, which are not feasible for the screening of a wide population due to cost, accessibility, and logistical constraints. To address this limitation, our previous research proposed a novel machine learning (ML)-based model that predicts lead exposure levels in pregnant women using sociodemographic data alone. However, for such predictive models to gain broader acceptance, especially in clinical and public health settings, transparency and interpretability are essential.
Understanding the reasoning behind the predictions of the model is crucial to building trust and facilitating informed decision-making. In this study, we present the first application of an explainable artificial intelligence (XAI) framework to interpret predictions made by our ML-based lead exposure model.
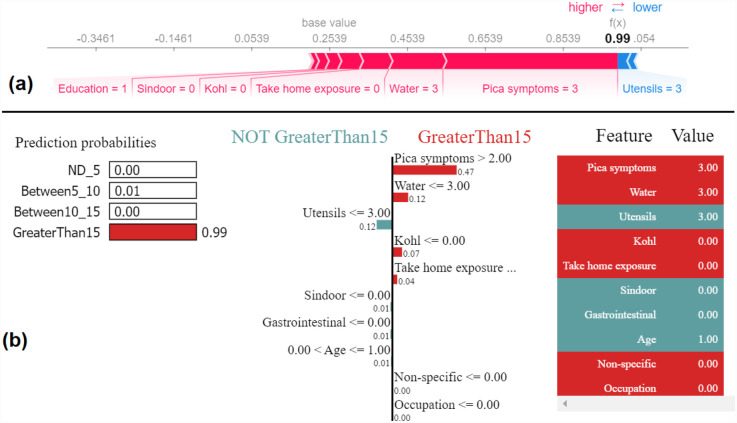
Using a dataset of 200 blood samples and 12 sociodemographic features, a Random Forest classifier was trained, achieving an accuracy of 84.52%.
We applied two widely used XAI methods, SHAP (SHapley additive explanations) and LIME (Local Interpretable Model-Agnostic Explanations), to provide insight into how each input feature contributed to the model's predictions.
铅中毒是一个广为人知的环境卫生问题,产前接触铅对婴儿构成重大风险。婴儿接触铅的一个主要途径是孕期母体铅转移。因此,准确表征母体铅水平对于实施有针对性的个性化医疗干预至关重要。目前铅中毒的检测方法基于实验室血液检测,由于成本、可及性和后勤限制,这种方法对于广泛人群的筛查并不可行。为解决这一局限性,我们之前的研究提出了一种基于机器学习(ML)的新型模型,该模型仅使用社会人口统计学数据预测孕妇的铅暴露水平。然而,要使此类预测模型获得更广泛的认可,尤其是在临床和公共卫生环境中,透明度和可解释性至关重要。
理解模型预测背后的推理对于建立信任和促进明智决策至关重要。在本研究中,我们首次应用可解释人工智能(XAI)框架来解释基于机器学习的铅暴露模型所做的预测。
使用包含200个血液样本和12个社会人口统计学特征的数据集,训练了一个随机森林分类器,准确率达到84.52%。
我们应用了两种广泛使用的XAI方法,即SHAP(Shapley值加法解释)和LIME(局部可解释模型无关解释),以深入了解每个输入特征如何对模型的预测产生影响。