Ayele Misganaw Ketema, Baye Getachew Alemu, Yesuf Seid Hassen, Engda Abebaw Agegne, Mitiku Eshetie Teka
Department of information technology, Debark university, Debark, Ethiopia.
Department of computer science, University of Gondar, Gondar, Ethiopia.
Sci Rep. 2025 Jul 31;15(1):27907. doi: 10.1038/s41598-025-03206-1.
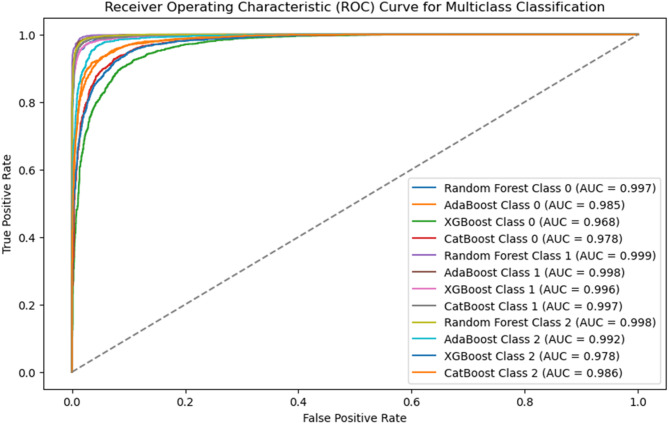
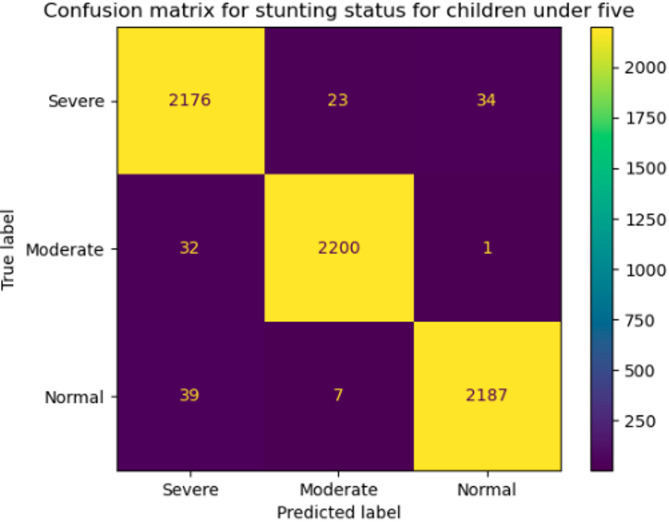
Childhood stunting is a persistent public health challenge in Ethiopia, significantly impacting children's physical growth, cognitive development, and overall well-being. This study overcame a key limitation in previous stunting prediction models by developing a multi-class classification model that predicts stunting severity (severe, moderate, normal) using Ethiopia's nationally representative EDHS data from 2011 to 2016. Secondary data from the 2011 and 2016 Ethiopian Demographic and Health Surveys (EDHS) were analyzed, comprising 18,451 instances with 28 features. Data preprocessing included handling missing values, duplicate removal, feature selection, and synthetic minority over-sampling technique (SMOTE) for class balancing, resulting in 33,495 instances with 18 selected features. Four ensemble machine learning algorithms Random Forest, AdaBoost, XGBoost, and CatBoost were implemented and evaluated based on accuracy, precision, recall, F1-score, and ROC-AUC. Among the models, Random Forest achieved the highest performance with an accuracy of 97.985%, precision of 97.986%, recall of 97.985%, F1-score of 97.954%, and ROC-AUC of 99.995%. The top risk factors contributing to stunting included child's age, maternal education level, birth order, household wealth index, mother's BMI, breastfeeding duration, and access to clean water and sanitation. This study demonstrates the effectiveness of machine learning in accurately predicting childhood stunting in Ethiopia. The findings provide critical insights for healthcare professionals and policymakers to implement targeted intervention strategies, ultimately reducing childhood stunting prevalence.
儿童发育迟缓是埃塞俄比亚持续存在的公共卫生挑战,对儿童的身体生长、认知发展和整体福祉产生重大影响。本研究通过开发一个多类分类模型克服了先前发育迟缓预测模型中的一个关键限制,该模型使用埃塞俄比亚2011年至2016年具有全国代表性的埃塞俄比亚人口与健康调查(EDHS)数据来预测发育迟缓的严重程度(严重、中度、正常)。对2011年和2016年埃塞俄比亚人口与健康调查(EDHS)的二手数据进行了分析,包括18451个实例和28个特征。数据预处理包括处理缺失值、去除重复项、特征选择以及用于类别平衡的合成少数过采样技术(SMOTE),从而得到33495个实例和18个选定特征。实施了四种集成机器学习算法——随机森林、自适应增强(AdaBoost)、极端梯度提升(XGBoost)和类别提升(CatBoost),并基于准确率、精确率、召回率、F1分数和ROC曲线下面积(ROC-AUC)进行评估。在这些模型中,随机森林表现最佳,准确率为97.985%,精确率为97.986%,召回率为97.985%,F1分数为97.954%,ROC-AUC为99.995%。导致发育迟缓的主要风险因素包括儿童年龄、母亲教育水平、出生顺序、家庭财富指数、母亲的体重指数、母乳喂养持续时间以及获得清洁水和卫生设施的情况。本研究证明了机器学习在准确预测埃塞俄比亚儿童发育迟缓方面的有效性。研究结果为医疗保健专业人员和政策制定者实施有针对性的干预策略提供了关键见解,最终降低儿童发育迟缓的患病率。