Bulashevska Alla, Eils Roland
Theoretical Bioinformatics Department, German Cancer Research Center, Im Neuenheimer Feld 280, 69120 Heidelberg, Germany.
BMC Bioinformatics. 2006 Jun 14;7:298. doi: 10.1186/1471-2105-7-298.
The subcellular location of a protein is closely related to its function. It would be worthwhile to develop a method to predict the subcellular location for a given protein when only the amino acid sequence of the protein is known. Although many efforts have been made to predict subcellular location from sequence information only, there is the need for further research to improve the accuracy of prediction.
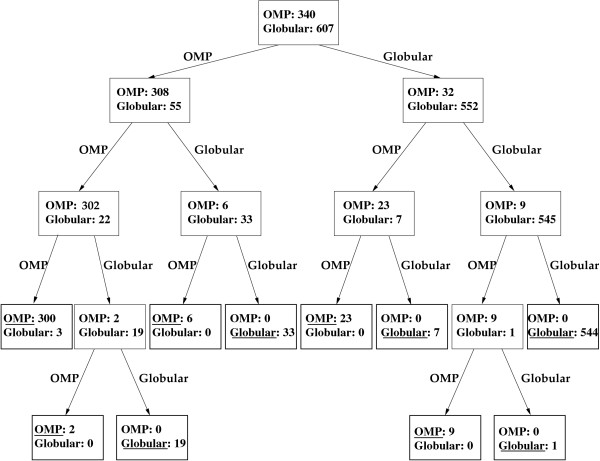
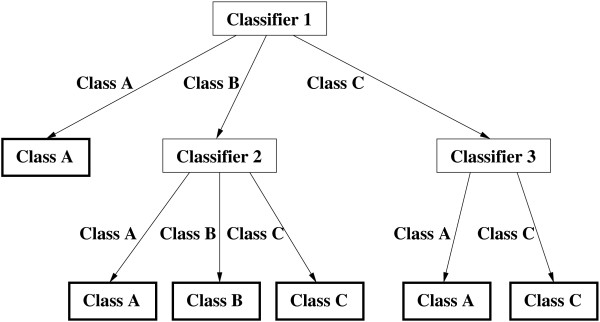
A novel method called HensBC is introduced to predict protein subcellular location. HensBC is a recursive algorithm which constructs a hierarchical ensemble of classifiers. The classifiers used are Bayesian classifiers based on Markov chain models. We tested our method on six various datasets; among them are Gram-negative bacteria dataset, data for discriminating outer membrane proteins and apoptosis proteins dataset. We observed that our method can predict the subcellular location with high accuracy. Another advantage of the proposed method is that it can improve the accuracy of the prediction of some classes with few sequences in training and is therefore useful for datasets with imbalanced distribution of classes.
This study introduces an algorithm which uses only the primary sequence of a protein to predict its subcellular location. The proposed recursive scheme represents an interesting methodology for learning and combining classifiers. The method is computationally efficient and competitive with the previously reported approaches in terms of prediction accuracies as empirical results indicate. The code for the software is available upon request.
蛋白质的亚细胞定位与其功能密切相关。当仅知道蛋白质的氨基酸序列时,开发一种预测给定蛋白质亚细胞定位的方法是很有价值的。尽管已经做出了许多努力仅从序列信息预测亚细胞定位,但仍需要进一步研究以提高预测的准确性。
引入了一种名为HensBC的新方法来预测蛋白质亚细胞定位。HensBC是一种递归算法,它构建了一个分类器的层次集成。所使用的分类器是基于马尔可夫链模型的贝叶斯分类器。我们在六个不同的数据集上测试了我们的方法;其中包括革兰氏阴性菌数据集、用于区分外膜蛋白的数据以及凋亡蛋白数据集。我们观察到我们的方法能够高精度地预测亚细胞定位。该方法的另一个优点是它可以提高训练中序列较少的某些类别的预测准确性,因此对于类分布不均衡的数据集很有用。
本研究介绍了一种仅使用蛋白质一级序列来预测其亚细胞定位的算法。所提出的递归方案代表了一种有趣的学习和组合分类器的方法。经验结果表明,该方法计算效率高,在预测准确性方面与先前报道的方法具有竞争力。可根据要求提供软件代码。