Savic Radojka, Lavielle Marc
UMR 738 INSERM, Université Paris Diderot, Paris, France.
J Pharmacokinet Pharmacodyn. 2009 Aug;36(4):367-79. doi: 10.1007/s10928-009-9127-7. Epub 2009 Aug 13.
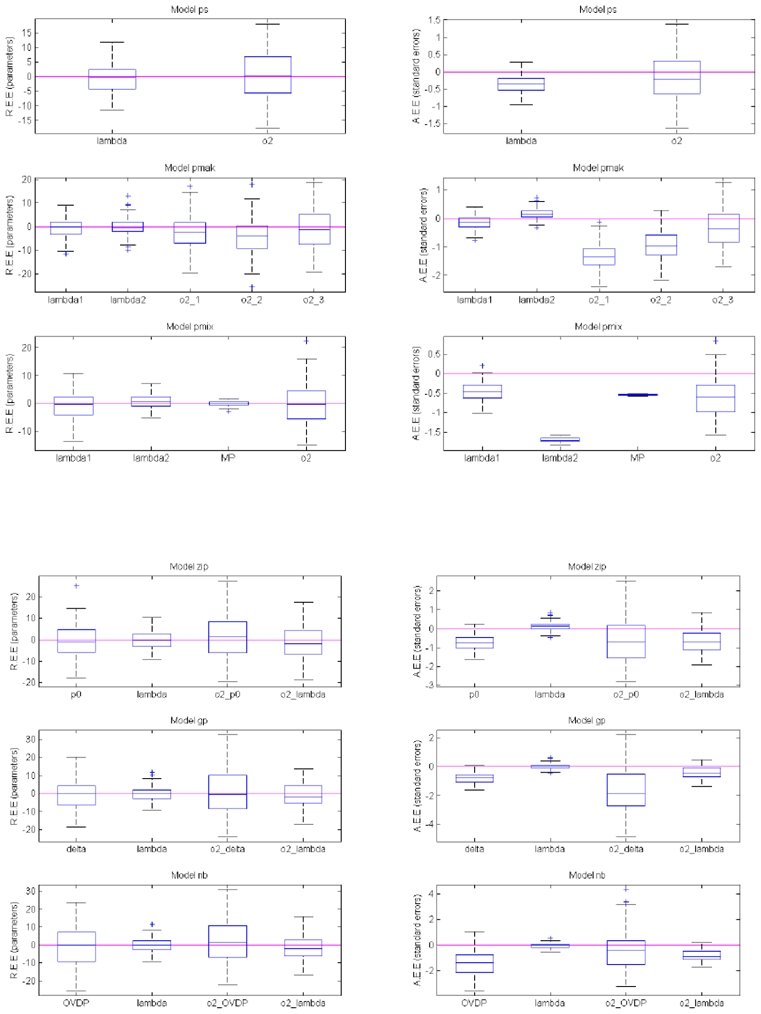
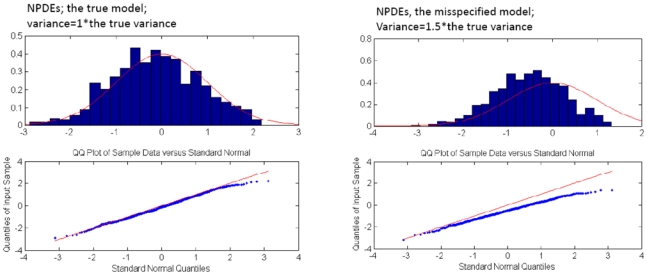
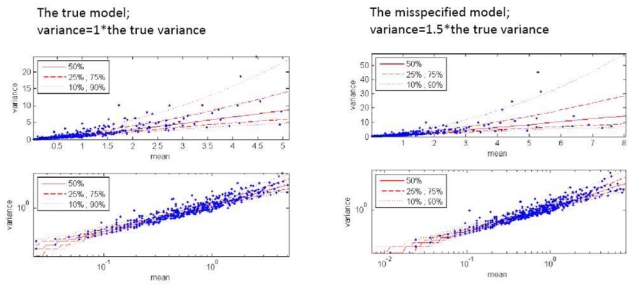
Analysis of count data from clinical trials using mixed effect analysis has recently become widely used. However, algorithms available for the parameter estimation, including LAPLACE and Gaussian quadrature (GQ), are associated with certain limitations, including bias in parameter estimates and the long analysis runtime. The stochastic approximation expectation maximization (SAEM) algorithm has proven to be a very efficient and powerful tool in the analysis of continuous data. The aim of this study was to implement and investigate the performance of a new SAEM algorithm for application to count data. A new SAEM algorithm was implemented in MATLAB for estimation of both, parameters and the Fisher information matrix. Stochastic Monte Carlo simulations followed by re-estimation were performed according to scenarios used in previous studies (part I) to investigate properties of alternative algorithms (Plan et al., 2008, Abstr 1372 [ http://wwwpage-meetingorg/?abstract=1372 ]). A single scenario was used to explore six probability distribution models. For parameter estimation, the relative bias was less than 0.92% and 4.13% for fixed and random effects, for all models studied including ones accounting for over- or under-dispersion. Empirical and estimated relative standard errors were similar, with distance between them being <1.7% for all explored scenarios. The longest CPU time was 95 s for parameter estimation and 56 s for SE estimation. The SAEM algorithm was extended for analysis of count data. It provides accurate estimates of both, parameters and standard errors. The estimation is significantly faster compared to LAPLACE and GQ. The algorithm is implemented in Monolix 3.1, (beta-version available in July 2009).
使用混合效应分析对临床试验计数数据进行分析近来已得到广泛应用。然而,可用于参数估计的算法,包括拉普拉斯算法和高斯求积法(GQ),存在一定局限性,如参数估计偏差以及分析运行时间长等问题。随机近似期望最大化(SAEM)算法已被证明是分析连续数据的一种非常高效且强大的工具。本研究的目的是实现并研究一种应用于计数数据的新SAEM算法的性能。在MATLAB中实现了一种新的SAEM算法,用于估计参数和费舍尔信息矩阵。根据先前研究(第一部分)中使用的场景进行随机蒙特卡罗模拟,随后进行重新估计,以研究替代算法的特性(Plan等人,2008年,摘要1372 [http://wwwpage - meetingorg/?abstract = 1372])。使用单个场景探索六种概率分布模型。对于参数估计,在所有研究的模型中,包括考虑过分散或欠分散的模型,固定效应和随机效应的相对偏差分别小于0.92%和4.13%。经验相对标准误差和估计相对标准误差相似,在所有探索的场景中,它们之间的距离<1.7%。参数估计的最长CPU时间为95秒,标准误差估计为56秒。SAEM算法已扩展用于计数数据的分析。它能提供参数和标准误差的准确估计。与拉普拉斯算法和GQ相比,估计速度明显更快。该算法已在Monolix 3.1中实现(2009年7月可获取测试版)。